

HMRI 使用 ML.NET 构建了面向医学研究的人在回路 ML 框架

行业
医疗保健
组织规模
大型(1,000-9,999 名员工)
国家/地区
澳大利亚
技术
公司
Hunter Medical Research Institute (HMRI)。是一个旨在改善社区健康和福祉的组织。为了实现这一目标,它将科学家、临床医生和公共卫生专业人员汇集在一起,以快速跟踪新的和更好的卫生解决方案提供情况。
Hunter Medical Research Institute (HMRI)。是一个旨在改善社区健康和福祉的组织。为了实现这一目标,它将科学家、临床医生和公共卫生专业人员汇集在一起,以快速跟踪新的和更好的卫生解决方案提供情况。
要了解该研究的详细信息,请参阅论文 "A method for rapid machine learning development for data mining with Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, Simon Quilty。
业务问题
医疗保健机构拥有大量数据。此数据通常采用非结构化文本格式。即使对其进行数字化,也往往难以从数据中提取有意义且可操作的见解。正则表达式、SQL 查询和“现成”自然语言处理软件等技术仅取得有限的成功。
在此类情况下,机器学习可以帮助分析和提取数据中有价值的信息。机器学习工具以前用于对临床笔记进行分类,以用于各种临床和研究目的。但使用这些机器学习工具通常需要软件开发或数据科学技能,而这往往超出了医疗专业人员的范围。
即使在对模型进行训练的方案中,如果模型处于非监督状态,也会在用于现实世界中取得次优结果。由于医疗决策承受高度的风险,医疗专业人员必须信任他们的模型,并且在模型出现错误时使用其专业知识提供反馈。
因此,HMRI 的研究人员使用 ML.NET 开发人机循环 (HITL) 机器学习开发框架,以便医疗专业人员可以更轻松地标记数据、训练模型,并使用这些模型进行推理,而无需编程或机器学习经验。更重要的是,他们构建了一个反馈机制,以便医疗专家将其技能和专业知识整合到机器学习过程中。因此,这种高级别监督可在数据点较少的实际用例中获得更好的结果。
为什么选择 ML.NET?
HMRI 使用 Model Builder 开始使用 ML.NET。Model Builder 提供了一种方法来快速验证是否可以使用机器学习解决其问题。在验证使用机器学习解决问题的有效性后,他们利用了 ML.NET 自动化机器学习 (AutoML) API。ML.NET AutoML API 在其自定义 HITL 机器学习开发框架中自动选择算法和管道,并自动进行超参数优化。
ML.NET 的影响
HMRI 使用 Model Builder 来开始使用 ML.NET。Model Builder 提供了一种方法来快速验证是否可以使用机器学习来解决其问题。在验证使用机器学习解决问题的有效性后,他们利用了 ML.NET 自动化机器学习(AutoML) API。ML.NET AutoML API 在其自定义 HITL 机器学习开发框架中自动选择算法和管道,并自动进行超参数优化。
通过使用 ML.NET,HMRI 消除了将开发工作外包的需求,并且能够使用现有技能和资源在内部构建所有内容。
此外,通过利用解决方案中的 ML.NET,他们能够为医疗专家提供一个界面,以训练和使用不需要编程或机器学习体验的机器学习模型。
解决方案体系结构
用户与之交互的界面是一个 Web 应用程序,支持在模型训练和使用阶段中执行任务。
数据
对于初始实现,用于训练模型的数据来自历史医疗记录。所使用的一个数据集是包含大约 30,000 条记录的 40 年死亡率数据库,另一个数据集则是包含约 13,000 条记录的航空医学检索数据集。
数据存储在 SQL Server 数据库中。在训练之前,医疗专家使用 Web 应用程序将测试集标记为预定义的类别,以在训练循环期间计算准确度指标。然后,将使用一小组随机选择的数据进行第一轮训练。
培训、评估和消耗工作流

该模型的训练由医疗专家从 Web 应用程序触发。服务器端 ML.NET 代码将处理模型训练和重新训练。然后,模型将预测所有剩余数据。预测和置信度分数存储在 SQL Server 数据库中。SQL Server 存储过程将用于针对测试集计算和存储准确度指标。然后,这些指标将通过 Web 应用程序返回以向医疗专家显示。整个过程在几秒钟内即可完成。
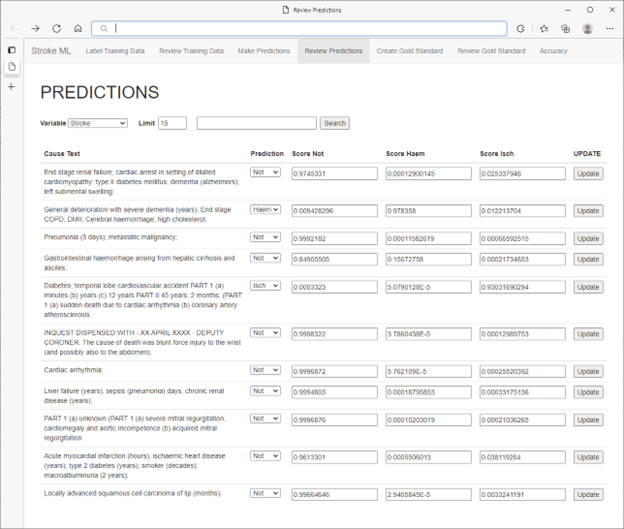
* 不是实际患者数据
医学专家发现,他们能够直观地使用召回率和特异性指标来指导如何选择要标记的其他病例,从而最大程度地快速改进模型性能。通过基于置信度分数排序选择性确定标记,可实现进一步的性能提升。在此过程中,医学专家不仅可以通过借助低分确认预测,还可通过借助高分更改错误预测来进行主动学习。
此时,医疗专家可以启动使用更正的数据标签重新训练模型的作业。在医疗专家对其模型性能感到满意之前,此标签、培训、评估循环将一直持续下去。训练事件时间戳、评估指标和其他信息将记录到 SQL Server 数据库,以便以后进行检查和审核。
在标记、训练、评估循环完成后,使用 SQL Server 的内置随机数生成器从 SQL Server 数据库中选择了一组验证预测。这些数据点已由一组对模型预测并不知情的医学专家进行标记。
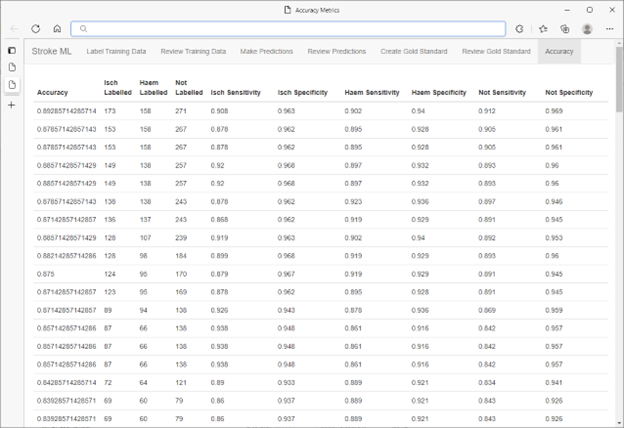
模型的结果准确度在 90 年代时为中到高。此结果使研究人员能够放心地在其正在进行的医学研究中使用该模型生成的分类。结合了 HITL 工作流的 ML.NET 的速度意味着可以经济高效地将其重复用于不同的分类任务和/或不同的数据集,而不会对准确度造成影响。
未来的计划
对依赖于快速和准确分类医疗自由文本的未来研究而言,由 HMRI 研究人员开发的“医生在回路”工作流将表现出重要价值。