

HMRI built a Human-In-The-Loop ML framework for medical research using ML.NET

Industry
Healthcare
Organization Size
Large (1,000-9,999 employees)
Country/region
Australia
Technology
Company
Hunter Medical Research Institute (HMRI) is an organization whose purpose is to improve the health and wellbeing of their communities. It does so by bringing together scientists, clinicians, and public health professionals to fast-track the provision of new and better health solutions.
Hunter Medical Research Institute (HMRI) is an organization whose purpose is to improve the health and wellbeing of their communities. It does so by bringing together scientists, clinicians, and public health professionals to fast-track the provision of new and better health solutions.
The details of the research can be found in the paper, "A method for rapid machine learning development for data mining with Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, Simon Quilty.
Business Problem
Healthcare institutions have large amounts of data. Usually, this data is in the format of unstructured text. Even when digitized, it's often difficult to extract meaningful and actionable insights from the data. Techniques like regular expressions, SQL queries and 'off the shelf' natural language processing software have limited success.
In such cases, machine learning can help analyze and extract valuable information from the data. Machine learning tools have previously been used to classify clinical notes into categories for a variety of clinical and research purposes. However, using these machine learning tools often requires software development or data science skills. Skills that are often beyond the scope of medical professionals.
Even in scenarios where a model is trained, when left unsupervised, the models achieve suboptimal results when used in the real-world. With the high stakes involved in medical decisions, it's important that medical professionals can trust their models and in cases where a model is wrong, use their expertise to provide feedback.
That's why researchers at HMRI used ML.NET to develop a Human-In-The-Loop (HITL) machine learning development framework to make it easier for medical professionals to label data, train models, and use these models for inferencing with no programming or machine learning experience required. More importantly, they've built a feedback mechanism so medical experts can incorporate their skills and expertise into the machine learning process. As a result, this high level of supervision achieves better results in real-world use cases with fewer data points.
Why ML.NET?
HMRI used Model Builder to get started with ML.NET. Model Builder provided a way to quickly validate whether their problem could be solved using machine learning. Once they had validated the efficacy of using machine learning for their problem, they leveraged the ML.NET Automated Machine Learning (AutoML) API. The ML.NET AutoML API automated choosing an algorithm as well as pipeline and hyperparameter optimization inside their custom HITL machine learning development framework.
Impact of ML.NET
HMRI used Model Builder to get started with ML.NET. Model Builder provided a way to quickly validate whether their problem could be solved using machine learning. Once they had validated the efficacy of using machine learning for their problem, they leveraged the ML.NET Automated Machine Learning (AutoML) API. The ML.NET AutoML API automated choosing an algorithm as well as pipeline and hyperparameter optimization inside their custom HITL machine learning development framework.
By using ML.NET, HMRI removed the need to outsource development efforts and was able to use existing skills and resources to build everything in-house.
In addition, by leveraging ML.NET as part of their solution, they were able to provide an interface for medical experts to train and consume machine learning models that required no programming or machine learning experience.
Solution architecture
The interface users interact with is a web application that supports several tasks in the model training and consumption phases.
Data
For the initial implementations, data used to train the models came from historical medical records. One dataset used was a 40-year mortality database containing about 30,000 records and the other an aeromedical retrieval dataset containing about 13,000 records.
The data is stored in a SQL Server database. Before training, medical experts use the web application to label a test set into predefined categories to calculate accuracy metrics during the training loop. Then, a small set of randomly chosen data are used for the first round of training.
Training, evaluation, and consumption workflow

Training of the model is triggered by the medical experts from the web application. The server side ML.NET code handles model training and retraining. The model then predicts all remaining data. Predictions and confidence scores are stored in the SQL Server database. SQL Server stored procedures are used to calculate and store accuracy metrics against the test-set. These metrics are then displayed back to the medical experts via the web application. This entire process completes in seconds.
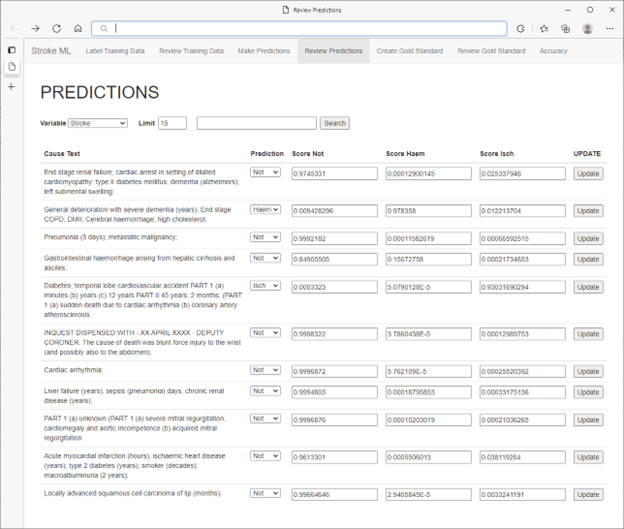
* Not actual patient data
The medical experts found that they were able to intuitively use recall and specificity metrics to guide selection of additional cases to label, resulting in both maximal and rapid improvement in model performance. Further performance gains were realized by selectively targeting labelling based on sorting by confidence scores. In doing so, medical experts engaged in active learning by not only confirming predictions with low scores but also correcting wrong predictions with high scores.
At this point, the medical experts can kick off a job to retrain the model using the corrected data labels. This label, training, evaluation loop continues until the medical experts are satisfied with the performance of their model. Training event timestamps, evaluation metrics and other information is logged to the SQL Server database for later inspection and auditability.
After the label, train, evaluate loop completes, a validation set of predictions is selected from the SQL Server database using SQL Server's inbuilt random number generator. These data points were labelled by a panel of medical experts blinded to the model's predictions.
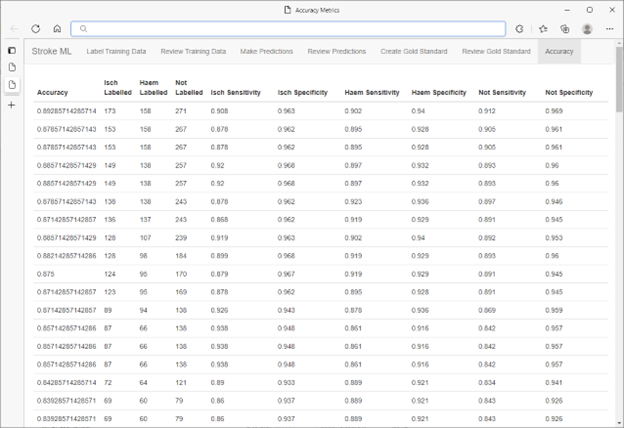
The resultant accuracy of the model was in the mid to high 90's. This result gave the researchers confidence to use the categorizations produced by the model in their ongoing medical research. The speed of ML.NET combined with the HITL workflow meant that it could be repeated for different categorization tasks and/or different data sets in a highly efficient, cost-effective manner without compromise to accuracy.
Future Plans
The Doctor-In-The-Loop workflow developed by HMRI researchers will prove invaluable for future research that depends on rapid and accurate categorization of medical free-text.