

endjin revolutionizes simple tasks with ML.NET

Industry
Information Technology and Services
Organization Size
Small (1-100 employees)
Country/region
United Kingdom
Technology
Company
Endjin is a boutique business, technology consultancy, and Microsoft Gold Partner for Cloud Platform, Data Platform, Data Analytics and DevOps based in the United Kingdom. Endjin has an infectious enthusiasm for the revolutionary power of technology and for harnessing that power to help customers solve hard problems. Recently, they have focused on using machine learning to solve mundane, but high value business problems. This has shown that while machine learning is great for solving novel use cases, its ability to revolutionize simple, everyday tasks is often overlooked.
We have been amazed at the ease with which AutoML and ML.NET can be used to reduce the time spent on time consuming and monotonous tasks. The freedom gained through the use of these accessible and powerful technologies allows us to focus our time on creative-thought-led analytics and attaining valuable insights from the data they produce."
Business problem
In 2014, endjin created Azure Weekly, a free newsletter that summarizes the week's top news in the Azure ecosystem. For the first 25 issues, the team at endjin manually curated the newsletter, but as the volume of content grew, they realized this was unsustainable. They applied their company mantra of "work smarter" and automated the end-to-end process by creating their own custom C# text classifier to classify articles from over 300 blogs into 19 categories, including AI + Machine Learning, Analytics, DevOps, Internet of Things, Networking, and Web. This worked relatively well, but in addition to the requirement of keeping an active list of keywords to classify against, manual corrections were needed every week, which caused major maintenance overhead.
200+ issues and many thousands of subscribers later, endjin decided to start looking into a machine learning solution. They knew at the heart of the content platform that they had two core problems to solve - a binary classification problem ("is this an article about Azure?") and a multiclass classification problem ("which area of Azure does this article cover?"). Thus, endjin decided to use ML.NET in order to solve these problems, improve their platform, and remove the manual maintenance overhead.
When you look at the work/processes carried out by most organizations, you can break them down into a series of 1 second decision-steps. If you apply machine learning, reactive workflows, and the API Economy to the problem space we start to get to the heart of what the 4th Industrial Revolution could deliver"
Why ML.NET?
Although their programming language of choice is C#, the previous lack of a first-class machine learning framework for .NET meant that endjin had been using R and Python in their day-to-day customer facing data science and ML experiments. However, productionizing machine learning models written in R and Python were problematic due to limited hosting options. The rest of endjin's content platform is built using PaaS and Serverless components, so the combination of ML.NET and Azure Functions was incredibly appealing to the company; as soon as ML.NET was announced at //build 2018, they started using the machine learning framework to their app.
Impact of ML.NET and AutoML
Endjin has greatly benefited from the high performance of ML.NET, not just in terms of speed improvements when classifying articles, but also in terms of accuracy. Since adopting ML.NET, they have seen far fewer mis-categorized articles, which translates to less manual interventions and faster content production.
Using the ML.NET CLI with AutoML has also made the whole process of training, evaluating, and generating the code to use ML.NET foolproof. Using AutoML to choose the best performing model and to automatically generate model training and consumption code for classification (as compared to manually choosing the data transformations, algorithms, and algorithm options to create an ML.NET model and code) improved the model accuracy from 68% to 78%, and running this model against historic data not only highlighted many articles that had been misclassified, but also identified many valid articles that had been excluded by the original classification model.
Solution architecture
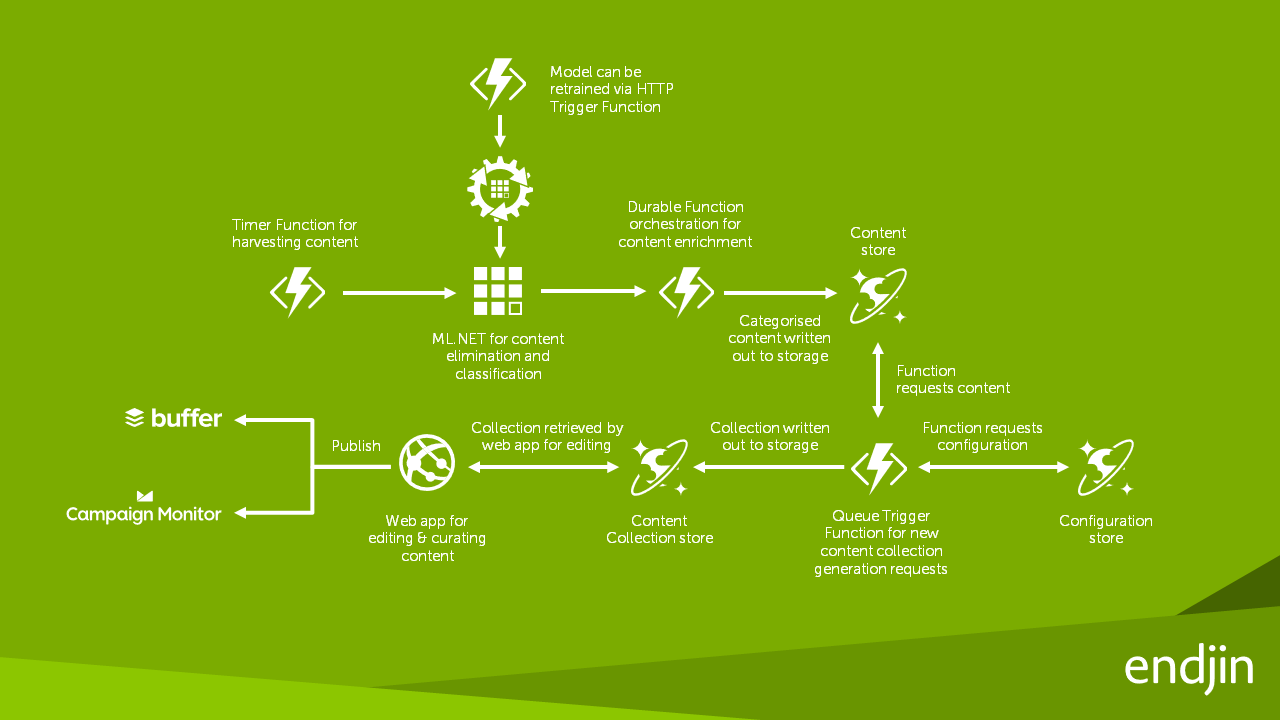
Creating an application with ML.NET
When endjin first started using ML.NET, they created a tool to convert the historical content platform data into a CSV dataset to manually train an ML.NET model, and they created another tool to randomly select 20% of the training dataset as a validation dataset. They then manually created a ML.NET model to predict which category an article belongs to.
Once the ML.NET CLI with AutoML was available to use, it simplified the process and produced significantly better results. Firstly, AutoML automatically generated a validation dataset from the training dataset, so endjin's second custom tool was no longer needed. Secondly, setting a max exploration time for one hour, AutoML was able to train, tune and evaluate multiple classification models and display the top 5 performing models.
Once endjin had the trained ML.NET models generated by AutoML, they integrated the models into the existing content platform, simply swapping out the existing custom classification algorithms. The ML.NET models were hosted inside an Azure Function to enable elastic scale of model evaluation. A new Durable Function was used to allow the models to be retrained on demand.
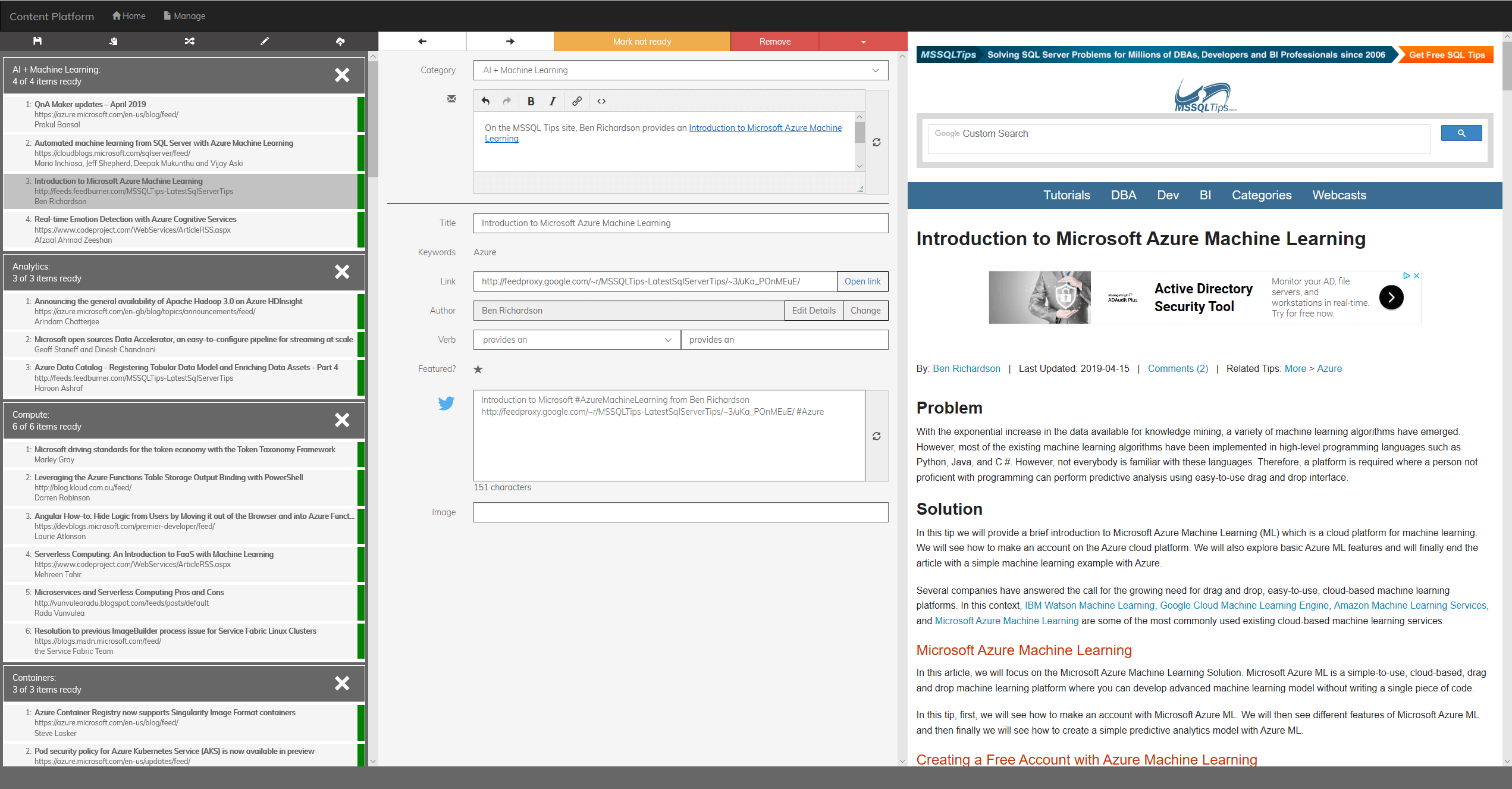
Data processing
Fortunately, the team at endjin knew when they built the original version of the content platform that one day they would want to improve it using machine learning, so they kept all the data used to generate the newsletters in both raw and processed formats (over 4,000 JSON files that were around 3 GB in total size). These were transformed into two training datasets: a 28 MB .CSV file for binary classification, and a 9 MB .CSV file for multiclass classification.
Data transformations and machine learning algorithms
As the title and contents of the blog posts being classified are free text, both need to be converted using the Featurize Text data transformation. Then the title and contents were joined together into a single field using the Concatenate data transformation.
The original model that endjin manually created used the SdcaMaximumEntropy multiclass classification algorithm. However, when endjin used the ML.NET CLI with AutoML, they found even higher performing models for their scenarios.
For the first scenario ("is this an article about Azure?") AutoML selected AveragedPerceptronBinary as the best performing algorithm. For the second scenario ("which area of Azure does this article cover?") AutoML selected LightGbmMulti as the highest performing algorithm and generated the following code to train the multiclass classifier:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin has used ML.NET to improve their process of selecting and categorizing articles for their Azure newsletter. Using ML.NET and AutoML to generate machine learning models has also allowed the company to focus less on fine-tuning model parameters and more on delivering their business value.