
ML.NET 튜토리얼 - 시작하기(10분)
시작
목적
Visual Studio에서 ML.NET Model Builder를 사용하여 ML.NET으로 첫 번째 기계 학습 모델을 학습시키고 사용합니다.
ML.NET CLI를 설치한 다음 ML.NET으로 첫 번째 기계 학습 모델을 학습하고 사용합니다.
필수 구성 요소
없음.
macOS 12.0 이상 버전.
완료 시간
10분 + 다운로드/설치 시간
시나리오
고객 리뷰의 텍스트가 부정적인 감정인지 긍정적인 감정인지 예측할 수 있는 앱입니다.
다운로드 및 설치
Visual Studio 2026을 다운로드하여 설치합니다.
설치하는 동안 .NET 데스크톱 개발 워크로드를 선택적 ML.NET Model Builder 구성 요소와 함께 선택해야 합니다. 위의 링크를 사용하면 다음 이미지에 표시된 대로 모든 필수 구성 요소를 올바르게 미리 선택해야 합니다.

이미 Visual Studio 2026이 있나요?
이 자습서는 최신 버전의 Visual Studio에 최적화되어 있습니다. Visual Studio 2026이 이미 있는 경우 최신 상태이고 필요한 워크로드가 설치되어 있는지 확인하세요.
-
컴퓨터에서 Visual Studio 설치 관리자를 찾으세요.
Windows 시작 메뉴에서 "
installer"를 검색한 후 결과에서 Visual Studio 설치 관리자를 선택하세요. - 메시지가 표시되면 설치 프로그램이 자체적으로 업데이트하도록 허용합니다.
- Visual Studio 2026에 대한 업데이트가 사용 가능해지면 업데이트 단추가 표시됩니다. 설치를 수정하기 전에 업데이트하려면 단추를 선택하세요. 이 자습서에서는 최신 Visual Studio 2026 버전을 사용하는 것이 좋습니다.
- Visual Studio 2026 설치를 찾아 수정을 선택합니다.
- .NET 데스크톱 개발을 선택하고 오른쪽 창에서 ML.NET Model Builder가 선택되어 있는지 확인합니다. 수정 버튼을 선택합니다.
최신 버전의 Model Builder로 업그레이드
Visual Studio에서 ML.NET Model Builder를 사용하도록 설정한 후 최신 버전을 다운로드 및 설치하세요.
다운로드한 후 .vsix 파일을 두 번 클릭하여 확장을 설치합니다.
.NET SDK 설치
.NET 앱을 빌드하려면 .NET 8 SDK(소프트웨어 개발 키트)를 다운로드하여 설치해야 합니다.
.NET 8 SDK x64(Intel) 다운로드
.NET 8 SDK Arm64(Apple Silicon) 다운로드
Apple M1 또는 M2 칩이 있는 Mac을 사용하는 경우 Arm64 버전의 SDK를 설치해야 합니다.
ML.NET CLI 설치
ML.NET 명령줄 인터페이스(CLI)는 ML.NET으로 기계 학습 모델을 빌드하기 위한 도구를 제공합니다.
참고: 현재 ML.NET CLI는 미리 보기 상태이며 이전 LTS 버전인 .NET SDK(.NET 8)만 지원합니다.
설치 단계의 경우 Bash 콘솔을 사용하는 것이 좋습니다. macOS의 기본값은 zsh 콘솔이므로 새 터미널을 열고 아래 명령을 실행하여 단일 인스턴스를 만들 수 있습니다.
bashX64 컴퓨터의 경우 - 다음 명령을 실행합니다.
dotnet tool install -g mlnet-linux-x64ARM64 칩 아키텍처의 경우 - 대신 다음 명령을 실행합니다.
dotnet tool install -g mlnet-linux-arm64도구가 성공적으로 설치되면 [arch]가 칩 아키텍처인 다음 출력 메시지가 표시되어야 합니다.
You can invoke the tool using the following command: mlnet
Tool 'mlnet-linux-[arch]' (version 'X.X.X') was successfully installed.dotnet tool install -g mlnet-osx-x64ARM64 칩 아키텍처의 경우 - 대신 다음 명령을 실행합니다.
dotnet tool install -g mlnet-osx-arm64도구가 성공적으로 설치되면 [arch]가 칩 아키텍처인 다음과 유사한 출력 메시지가 표시됩니다.
You can invoke the tool using the following command: mlnet
Tool 'mlnet-osx-[arch]' (version 'X.X.X') was successfully installed.
참고: Bash 이외의 콘솔(예: macOS의 새로운 기본값인 zsh)을 사용하는 경우 mlnet 실행 파일을 제공해야 합니다. 권한을 부여하고 시스템 경로에 mlnet을 포함하세요. 이 작업을 수행하는 방법에 관한 지침은 mlnet(또는 모든 전역 도구)을 설치할 때 터미널에 표시됩니다. 일반적으로 chmod +x [PATH-TO-MLNET-CLI-EXECUTABLE] 명령은 대부분 시스템에서 작동합니다.
아래와 유사한 지침이 표시되면 터미널에서 실행합니다.
cat << \EOF >> ~/.zprofile
#Add .NET Core SDK tools
export PATH="$PATH:~/.dotnet/tools"
EOF또는 다음 명령을 사용하여 mlnet 도구를 실행할 수 있습니다.
~/.dotnet/tools/mlnet명령에서 여전히 오류가 발생하면 아래의 문제가 발생했습니다 버튼을 사용하여 문제를 보고하고 문제 해결에 대한 도움을 받으세요.
앱 만들기
Visual Studio를 열고 새 .NET 콘솔 앱을 만듭니다.
- Visual Studio 2026 시작 창에서 새 프로젝트 만들기를 선택합니다.
-
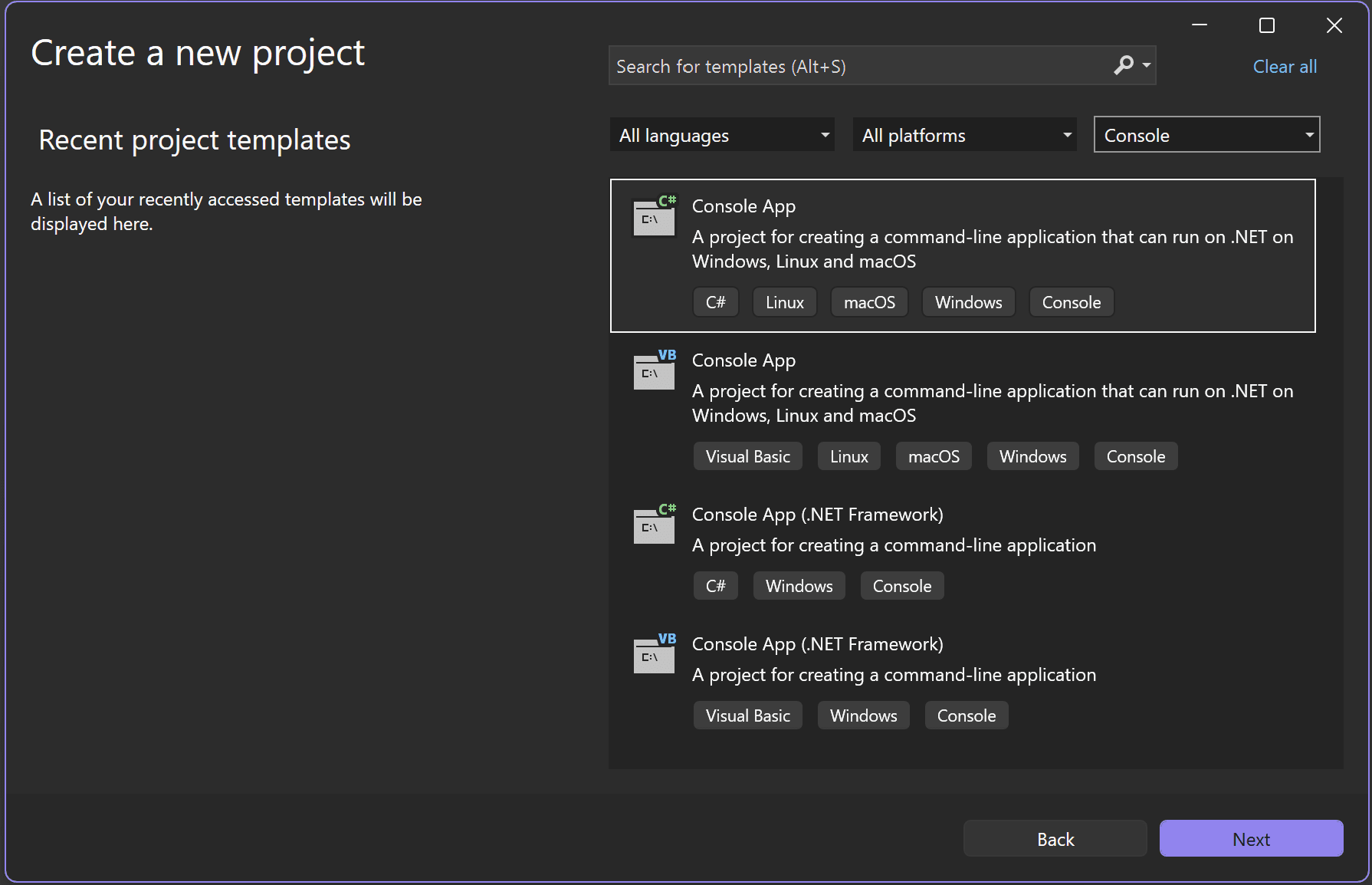
C# 콘솔 앱 프로젝트 템플릿을 선택합니다.
![Visual Studio 시작 화면의 스크린샷.]()
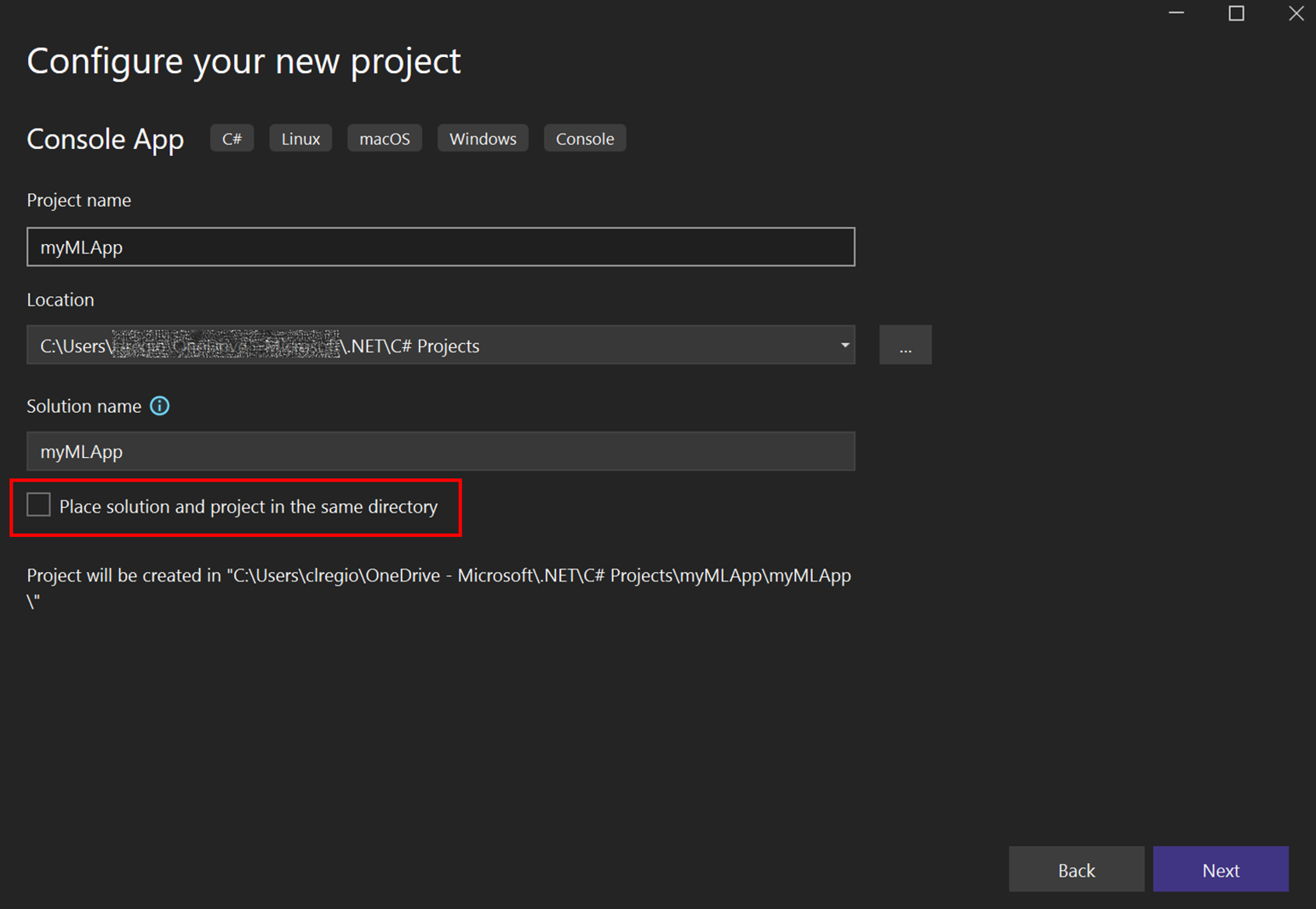
- 프로젝트 이름을
myMLApp으로 변경합니다. -
솔루션과 프로젝트를 같은 디렉터리에 배치가 선택 해제되어 있는지 확인합니다.
![Visual Studio 프로젝트 구성 화면의 스크린샷]()
- 다음 단추를 선택합니다.
- 프레임워크로 .NET 10.0(표준 기간 지원)을 선택합니다.
- 만들기 단추를 선택합니다. Visual Studio는 프로젝트를 만들고
Program.cs파일을 로드합니다.
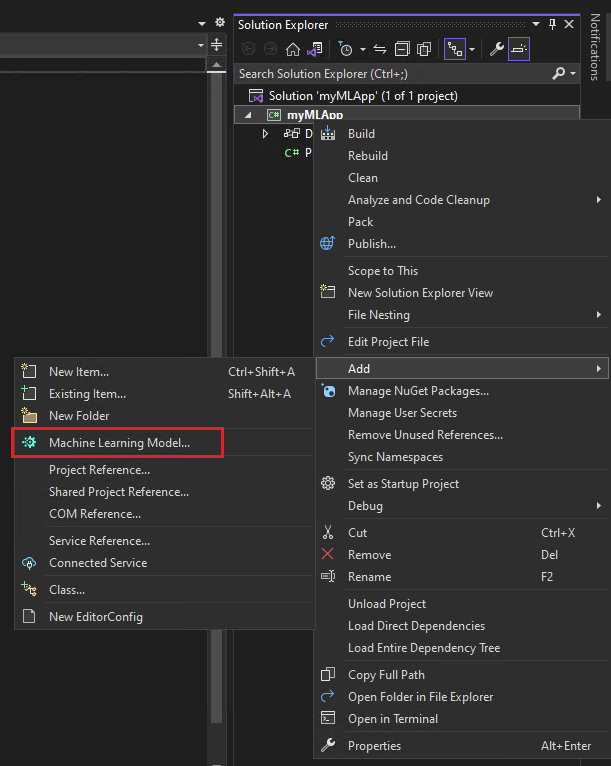
기계 학습 추가
-
솔루션 탐색기에서
myMLApp프로젝트를 마우스 오른쪽 버튼으로 클릭하고 추가 > 기계 학습 모델을 선택합니다.![선택한 기계 학습 모델을 표시하는 Visual Studio 스크린샷입니다.]()
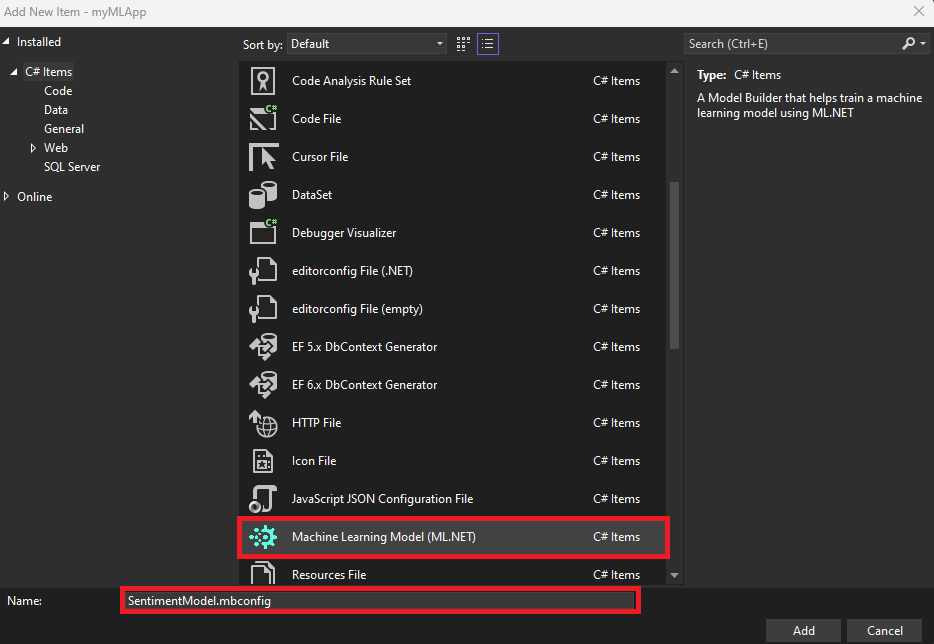
- 새 항목 추가 대화 상자에서 Machine Learning 모델(ML.NET)을 선택했는지 확인하십시오.
-
이름 필드를
SentimentModel.mbconfig로 변경하고 [추가] 버튼을 선택합니다.![선택한 기계 학습 모델(ML.NET)과 SentimentModel.mbconfig를 파일 이름으로 표시하는 새 항목 추가 대화 상자입니다.]()
SentimentModel.mbconfig라는 새 파일이 솔루션에 추가되고 Model Builder UI가 Visual Studio에서 고정된 새 도구 창에서 열립니다. mbconfig 파일은 단순히 UI의 상태를 추적하는 JSON 파일입니다.
Model Builder는 다음 단계에서 기계 학습 모델을 빌드하는 과정을 안내합니다.
터미널에서 다음 명령을 실행합니다.
mkdir myMLApp
cd myMLAppmkdir 명령은 myMLApp라는 새 디렉터리를 만들고 cd myMLApp 명령은 새로 만든 앱 디렉터리로 이동합니다.
다음 단계에서 모델 학습 코드가 생성됩니다.
시나리오 선택
모델을 생성하려면 먼저 기계 학습 시나리오를 선택해야 합니다. Model Builder는 몇 가지 시나리오를 지원합니다.
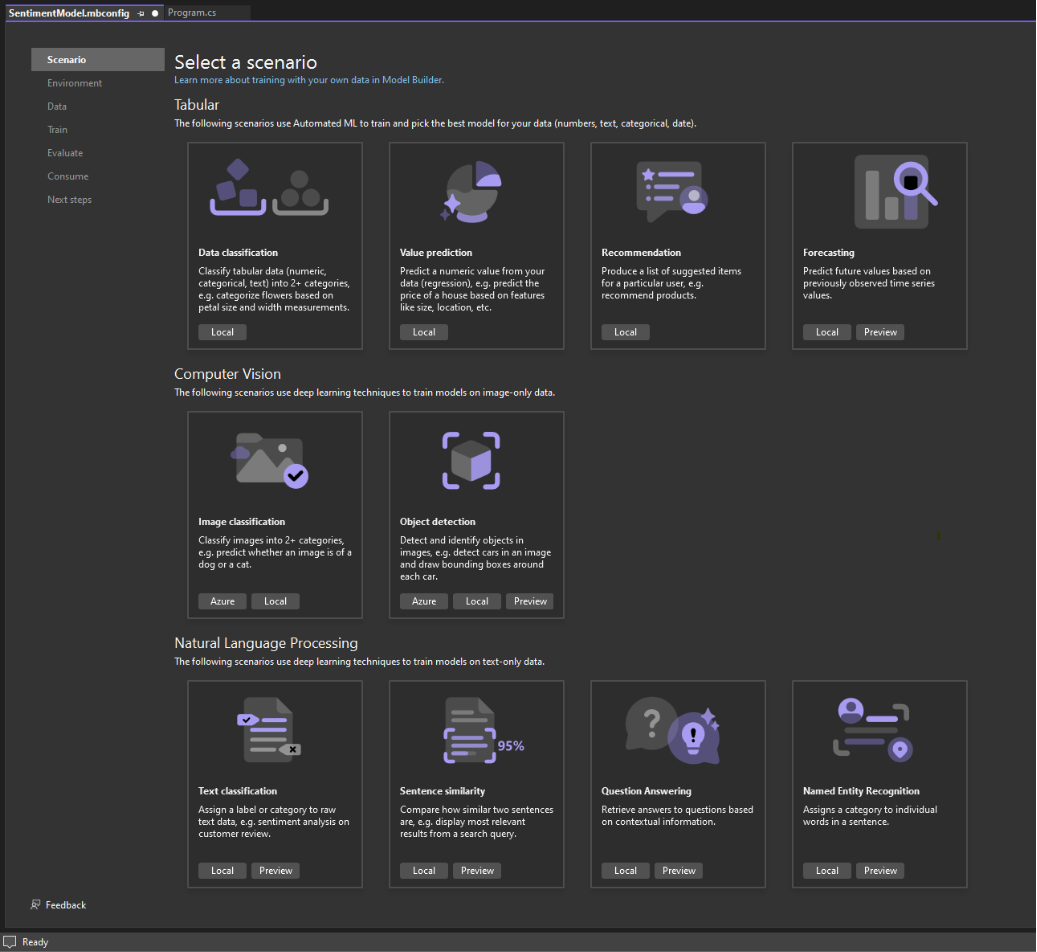
참고: 자습서 스크린샷이 보이는 것과 일치하지 않으면 Model Builder 버전을 업데이트해야 할 수 있습니다. 확장 > 확장 관리로 이동하여 Model Builder에 사용 가능한 업데이트가 없는지 확인합니다. 이 자습서에서 사용되는 버전은 17.18.2입니다.
이 경우 고객 리뷰의 내용(텍스트)을 기반으로 감정을 예측합니다.
-
Model Builder 시나리오 화면에서 주석이 속하는 범주(긍정 또는 부정)를 예측하므로 데이터 분류 시나리오를 선택합니다.
![Model Builder 데이터 분류 옵션의 스크린샷]()
-
데이터 분류 시나리오를 선택한 후 교육 환경을 선택해야 합니다. 일부 시나리오는 Azure에서 교육을 지원하지만 분류는 현재 로컬 교육만 지원하므로 로컬 환경을 선택한 상태로 유지하고 데이터 단계로 이동하세요.
![Model Builder에서 로컬 학습 환경이 선택됩니다.]()
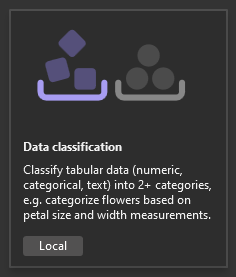
모델을 생성하려면 컴퓨터 학습 시나리오를 선택해야 합니다.
ML.NET CLI에서 지원하는 몇 가지 ML 시나리오가 있습니다.
- 분류 - 어떤 카테고리 데이터가 속하는지 예측하려는 경우 사용합니다(예: 고객 리뷰의 감정을 긍정적 또는 부정적으로 분석).
- 이미지 분류 - 이미지가 속한 범주를 예측하려는 경우(예: 이미지가 고양이인지 강아지인지 예측) 이 옵션을 사용합니다.
- 회귀(예: 값 예측) - 숫자 값을 예측하려는 경우(예: 집값 예측) 사용합니다.
- 예측 - 시계열의 미래 값을 예측하려는 경우(예: 분기별 매출 예측) 사용합니다.
- 추천 - 과거 평점(예: 제품 추천)을 기반으로 사용자에게 항목을 추천하려는 경우 사용합니다.
이 경우 고객 리뷰의 내용(텍스트)을 기반으로 감정을 예측하므로 분류를 사용합니다.
데이터 다운로드 및 추가
UCI Machine Learning 리포지토리에서 Sentiment Labeled Sentences 데이터 세트를 다운로드합니다. sentiment labelled sentences.zip의 압축을 풀고 yelp_labelled.txt 파일을 myMLApp 디렉터리에 저장합니다.
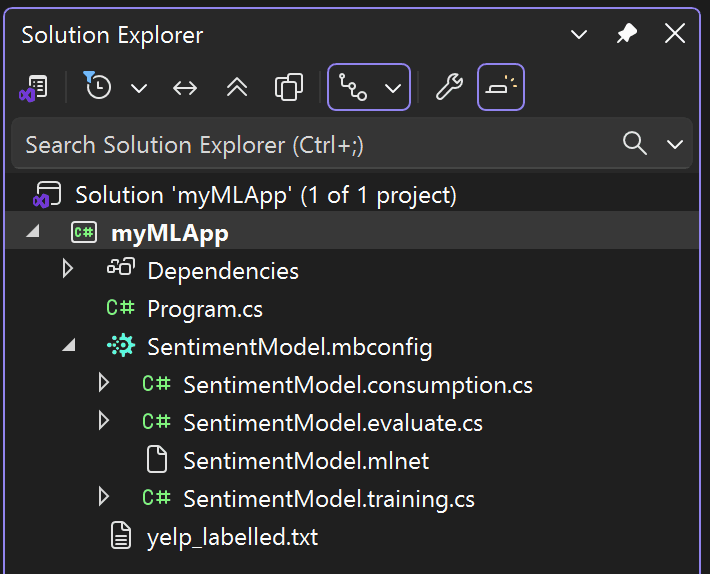
솔루션 탐색기가 다음과 같이 표시됩니다.
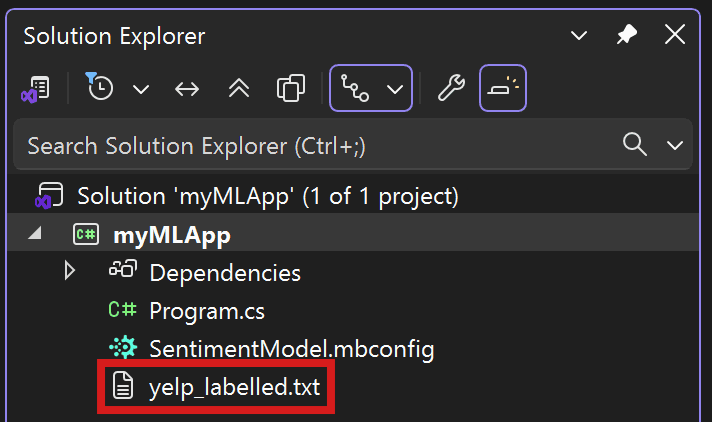
yelp_labelled.txt의 각 행은 Yelp에서 사용자가 남긴 식당에 대한 다른 리뷰를 나타냅니다. 첫 번째 열은 사용자가 남긴 메모를 나타내고 두 번째 열은 텍스트의 감정을 나타냅니다(0은 부정, 1은 긍정). 열은 탭으로 구분되고 데이터 세트에는 머리글이 없습니다. 데이터는 다음과 같이 표시됩니다.
Wow... Loved this place. 1
Crust is not good. 0
Not tasty and the texture was just nasty. 0데이터 추가
Model Builder에서 로컬 파일의 데이터를 추가하거나 SQL Server 데이터베이스에 연결할 수 있습니다. 이 경우 파일에서 yelp_labelled.txt를 추가합니다.
입력 데이터 소스 유형으로 파일을 선택합니다.
yelp_labelled.txt를 찾습니다. 데이터세트를 선택하면 데이터 미리 보기 섹션에 데이터 미리 보기가 나타납니다. 데이터세트에 헤더가 없으므로 헤더가 자동 생성됩니다("col0" 및 "col1").예측할 열(레이블)에서 "col1"을 선택합니다. 레이블은 예측하는 것으로, 이 경우 데이터 세트의 두 번째 열("col1")에 있는 감정입니다.
레이블을 예측하는 데 사용되는 열을 기능이라고 합니다. 레이블 외에 데이터 세트의 모든 열이 자동으로 기능으로 선택됩니다. 이 경우 검토 주석 열("col0")은 기능 열입니다. 기능 열을 업데이트하고 고급 데이터 옵션에서 다른 데이터 로드 옵션을 수정할 수 있지만 이 예제에서는 필요하지 않습니다.
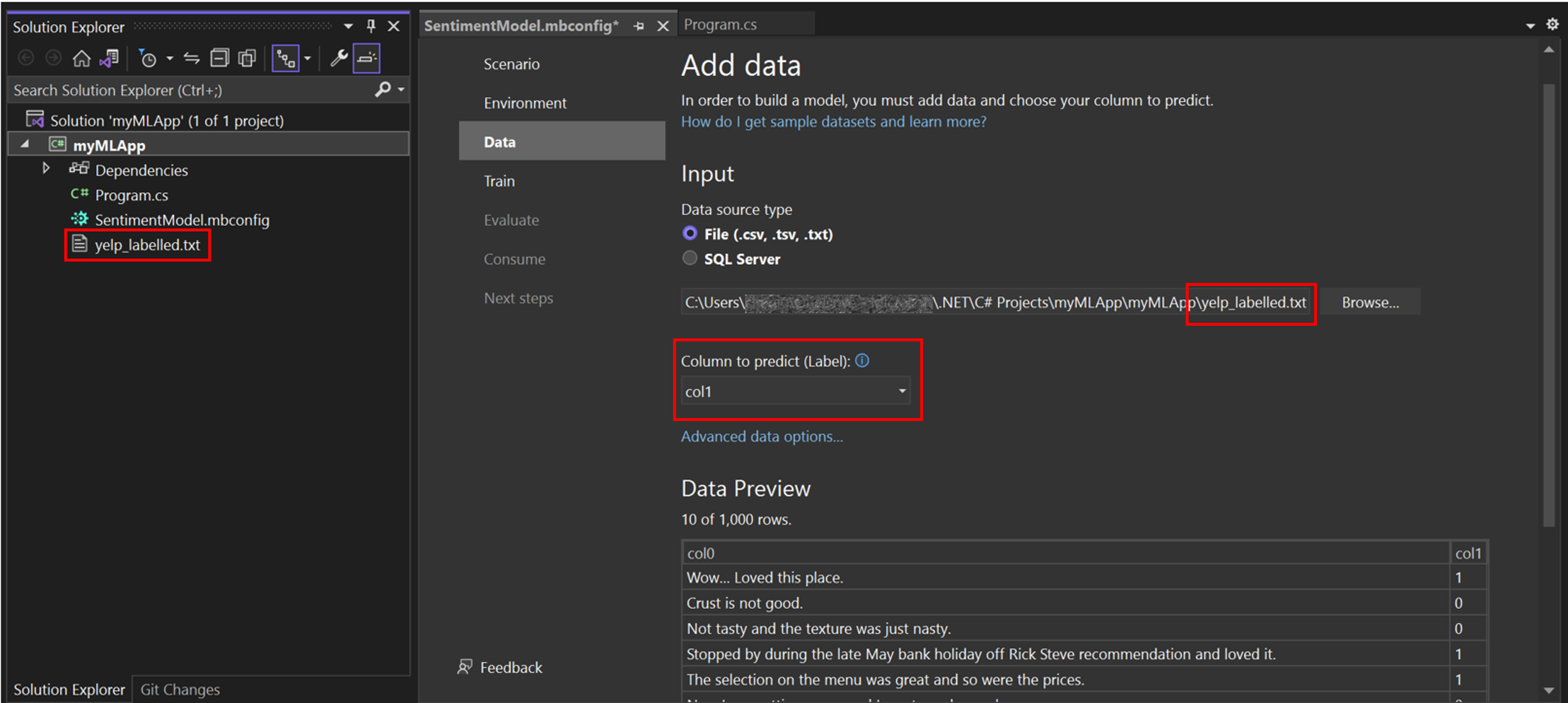
데이터를 추가한 후 학습 단계로 이동합니다.
모델 학습
이제 yelp_labelled.txt 데이터 세트를 사용하여 모델을 학습시킵니다.
Model Builder는 최고의 성능 모델을 빌드하기 위해 주어진 학습 시간을 기반으로 다양한 알고리즘과 설정으로 많은 모델을 평가합니다.
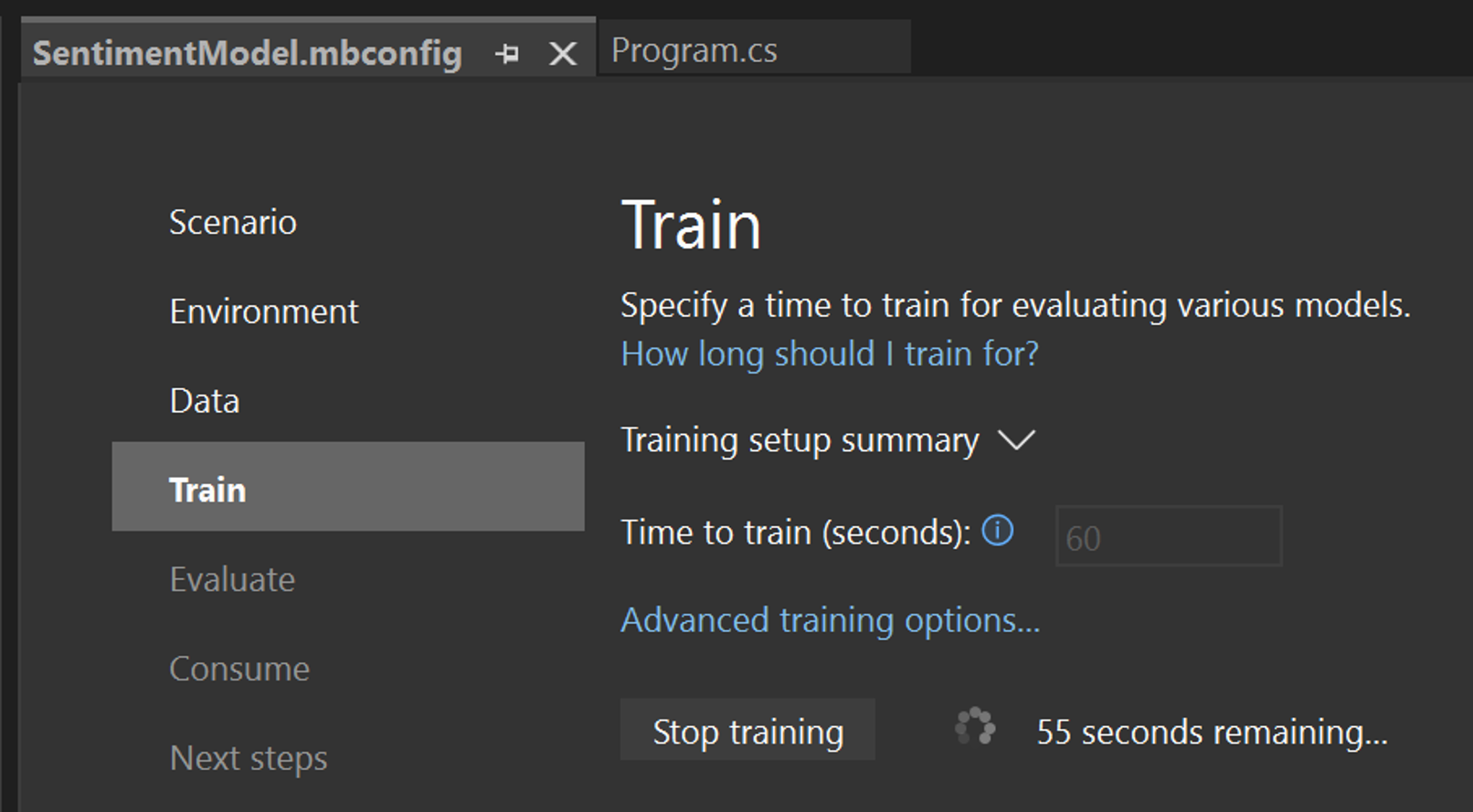
Model Builder가 다양한 모델을 탐색하도록 하는 시간인 학습 시간을 60초로 변경합니다(학습 후 발견된 모델이 없는 경우 이 숫자를 늘릴 수 있습니다) . 더 큰 데이터 세트의 경우 훈련 시간이 더 길어집니다. Model Builder는 데이터 세트 크기에 따라 훈련 시간을 자동으로 조정합니다.
고급 학습 옵션에 사용되는 최적화 메트릭 및 알고리즘을 업데이트할 수 있지만 이 예제에서는 필요하지 않습니다.
-
교육 시작을 선택하여 교육 프로세스를 시작합니다. 훈련이 시작되면 남은 시간을 볼 수 있습니다.
![Model Builder 학습]()
학습 결과
학습이 완료되면 학습 결과의 요약을 볼 수 있습니다.
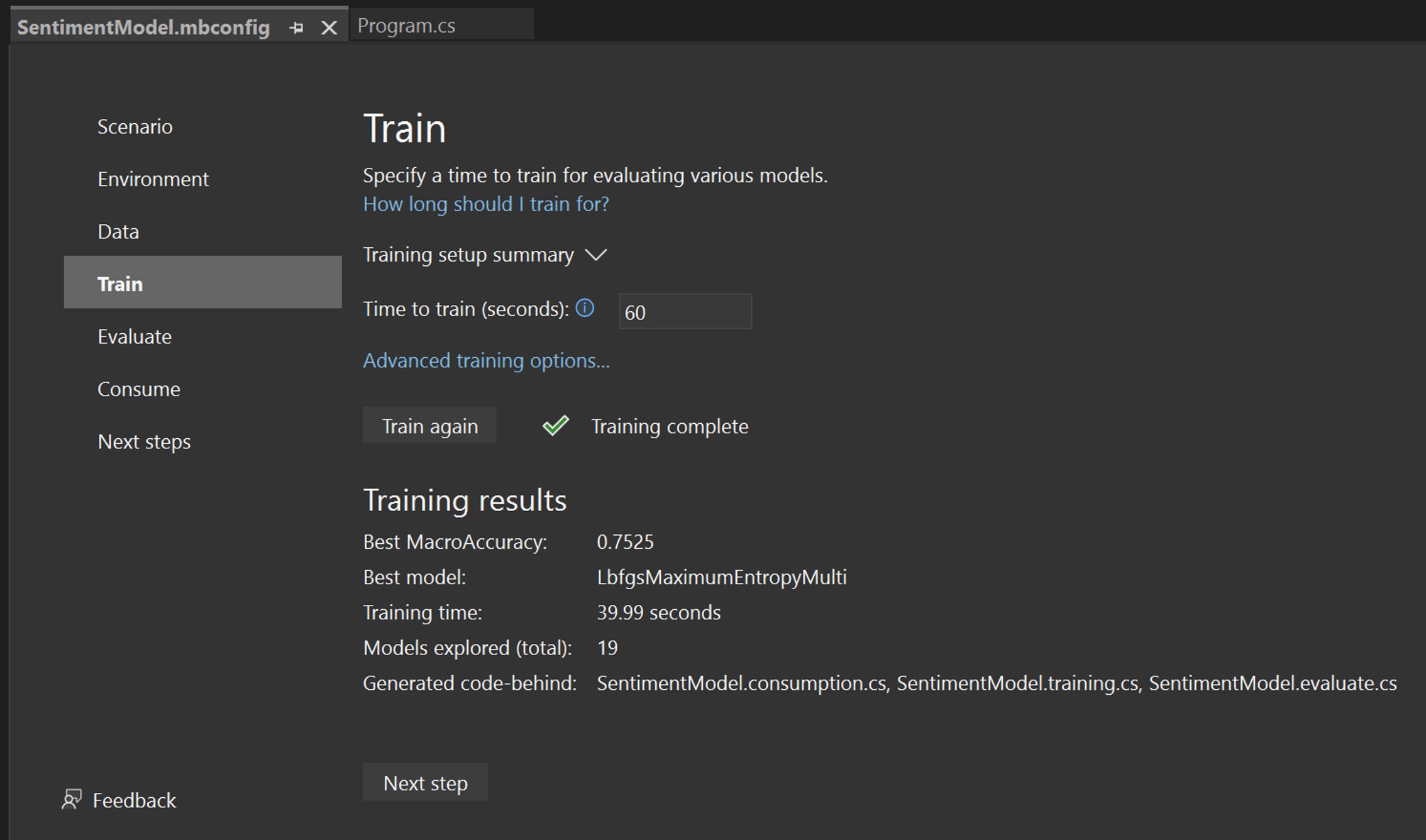
- 최고의 매크로 정확도 - Model Builder가 찾은 최고의 모델의 정확도를 보여줍니다. 정확도가 높다는 것은 모델이 테스트 데이터에서 더 정확하게 예측했다는 것을 의미합니다.
- 최상 모델- Model Builder의 탐색 중에 가장 잘 수행된 알고리즘을 보여줍니다.
- 학습 시간 - 모델을 학습/탐색하는 데 소요된 총 시간을 보여줍니다.
- 탐색된 모델(총)-지정된 시간 동안 Model Builder에서 탐색한 총 모델 수를 보여줍니다.
- 생성된 코드 숨김 - 모델을 사용하거나 새 모델을 학습시키는 데 도움이 되도록 생성된 파일의 이름을 보여 줍니다.
원하는 경우 Machine Learning 출력 창에서 교육 세션에 대한 자세한 정보를 볼 수 있습니다.
모델 학습이 끝나면 평가 단계로 이동합니다.
터미널에서 다음 명령(myMLApp 폴더에서)을 실행합니다.
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --name SentimentModel --train-time 60이러한 명령은 무엇을 의미하나요?
mlnet classification 명령은 AutoML을 사용하여 ML.NET을 실행하여 데이터 변환, 알고리즘 및 알고리즘 옵션의 다양한 조합을 사용하여 지정된 학습 시간에 분류 모델의 여러 반복을 탐색한 다음 성능이 가장 높은 모델을 선택합니다.
- --dataset:
yelp_labelled.txt를 데이터 세트로 선택했습니다(내부적으로 CLI는 하나의 데이터 세트를 훈련 및 테스트 데이터 세트로 분할합니다). - --label-col: 예측할 대상 열(또는 레이블)을 지정해야 합니다. 이 경우 두 번째 열의 감정을 예측하려고 합니다(인덱스가 0인 열은 이 열이 "1"임을 의미함).
- --has-header: 이 옵션을 사용하여 데이터 세트에 헤더가 있는지 여부를 지정합니다. 이 경우 데이터 세트에 헤더가 없으므로 false입니다.
- --name: 이 옵션을 사용하여 기계 학습 모델 및 관련 자산의 이름을 제공하세요. 이 경우 이 기계 학습 모델과 연결된 모든 자산의 이름에는 SentimentModel이 있습니다.
- --train-time: 또한 ML.NET CLI에서 다양한 모델을 탐색할 시간을 지정해야 합니다. 이 경우 60초(훈련 후 모델이 발견되지 않으면 이 숫자를 늘릴 수 있음). 더 큰 데이터 세트의 경우 더 긴 학습 시간을 설정해야 합니다.
진행률
ML.NET CLI가 다른 모델을 탐색하는 동안 다음 데이터가 표시됩니다.
- 교육 시작 - 이 섹션에는 사용된 트레이너(알고리즘)와 해당 반복에 대한 평가 메트릭을 포함하여 각 모델 반복이 표시됩니다.
- 남은 시간 - 이 표시줄과 진행률 표시줄은 훈련 과정에 남은 시간을 초 단위로 나타냅니다.
- 최고의 알고리즘 - 지금까지 어떤 알고리즘이 가장 잘 수행되었는지 보여줍니다.
- 최고 점수 - 지금까지 최고 모델의 성능을 보여줍니다. 정확도가 높다는 것은 모델이 테스트 데이터에서 더 정확하게 예측했다는 것을 의미합니다.
원하는 경우 CLI에서 생성한 로그 파일에서 교육 세션에 대한 자세한 정보를 볼 수 있습니다.
모델 평가
평가 단계는 최고 성능의 알고리즘과 최고의 정확도를 보여주고 UI의 모델입니다.
모델을 사용해 보세요
모델 사용해보기 섹션에서 샘플 입력을 예측할 수 있습니다. 텍스트 상자는 데이터 세트의 첫 번째 데이터 줄로 미리 채워져 있지만 입력을 변경하고 예측 단추를 선택하여 다른 감정 예측을 시도할 수 있습니다.
이 경우 0은 부정적인 감정을 의미하고 1은 긍정적인 감정을 의미합니다.
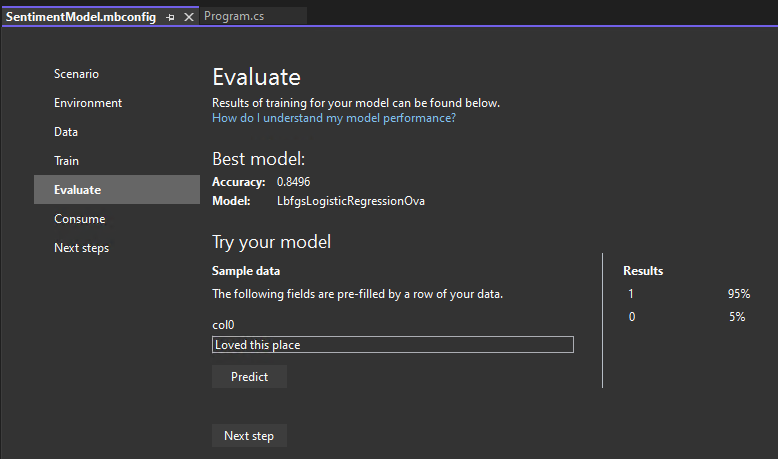
참고: 모델의 성능이 좋지 않으면(예: 정확도가 낮거나 모델이 '1' 값만 예측하는 경우) 시간을 더 추가하고 다시 학습을 시도할 수 있습니다. 이것은 매우 작은 데이터 세트를 사용하는 샘플입니다. 프로덕션 수준 모델의 경우 더 많은 데이터와 교육 시간을 추가하고 싶을 것입니다.
모델을 평가하고 테스트한 후 이용 단계로 이동합니다.
ML.NET CLI가 최상의 모델을 선택하면 학습 요약이 표시됩니다. 학습 요약에서는 지정된 학습 시간에 탐색된 모델 수를 포함하여 탐색 프로세스에 대한 요약을 보여 줍니다.
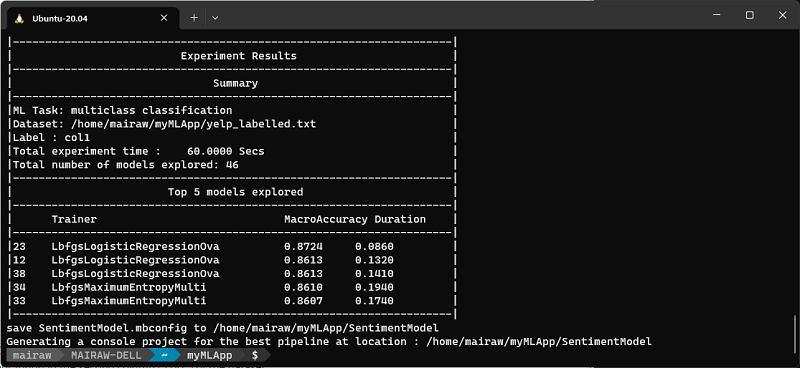
상위 모델
ML.NET CLI는 성능이 가장 높은 모델에 대한 코드를 생성하지만 지정된 탐색 시간에 발견된 가장 높은 정확도로 상위 모델(최대 5개)도 표시합니다. AUC, AUPRC 및 F1 점수를 포함하여 상위 모델에 대한 여러 평가 메트릭을 표시합니다. 자세한 내용은 ML.NET 메트릭을 참조하세요.
코드 생성
학습이 완료되면 네 개의 파일이 SentimentModel.mbconfig에 코드 숨김으로 자동으로 추가됩니다.
SentimentModel.consumption.cs: 이 파일에는 모델 사용에 사용할 수 있는 모델 입력 및 출력 클래스와Predict메서드가 포함되어 있습니다.SentimentModel.evaluate.cs: 이 파일에는 PFI(순열 기능 중요도) 기술을 사용하여 모델 예측에 가장 많이 기여하는 기능을 평가하는CalculatePFI메서드가 포함되어 있습니다.SentimentModel.mlnet: 이 파일은 직렬화된 zip 파일인 학습된 ML.NET 모델입니다.SentimentModel.training.cs: 이 파일에는 모델 예측에 대한 입력 열의 중요도를 이해하는 코드가 포함되어 있습니다.
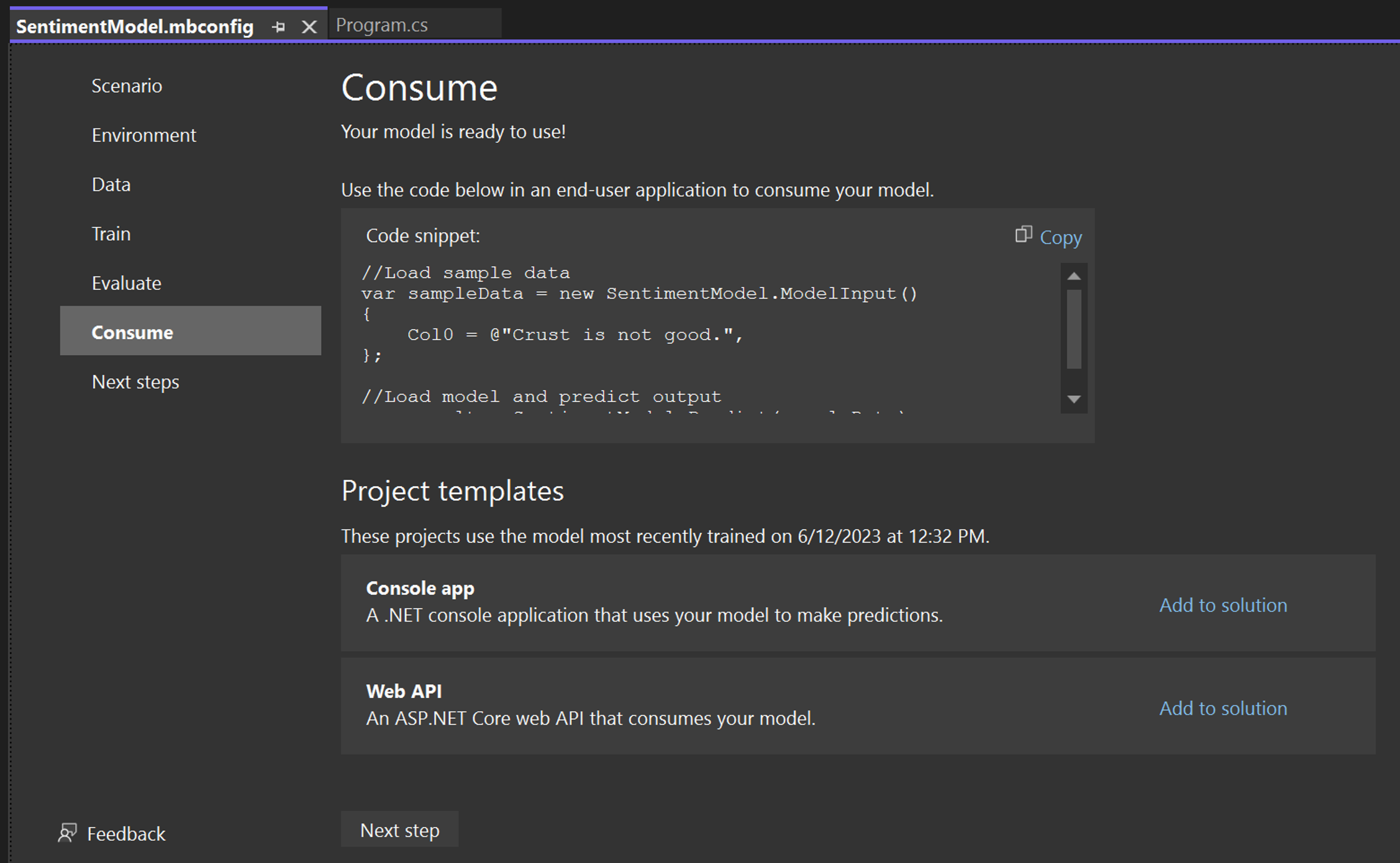
Model Builder 사용 단계에서는 모델에 대한 샘플 입력을 만들고 모델을 사용하여 해당 입력을 예측하는 코드 조각이 제공됩니다.
Model Builder는 또한 솔루션에 선택적으로 추가할 수 있는 프로젝트 템플릿을 제공합니다. 두 가지 프로젝트 템플릿(콘솔 앱과 웹 API)이 있으며 둘 다 훈련된 모델을 사용합니다.
ML.NET CLI는 기계 학습 모델과 다음을 포함하는 모델 학습 및 사용을 위한 코드를 모두 추가합니다.
-
다음 파일을 포함하는 .NET 콘솔 앱이 포함된 SentimentModel이라는 새 디렉터리가 만들어집니다.
Program.cs: 이 파일에는 모델을 실행하는 코드가 포함되어 있습니다.SentimentModel.consumption.cs: 이 파일에는 모델 사용에 사용할 수 있는 모델 입력 및 출력 클래스와Predict메서드가 포함되어 있습니다.SentimentModel.mbconfig: 이 파일은 훈련의 구성과 결과를 추적하는 JSON 파일입니다.SentimentModel.training.cs: 이 파일에는 최종 모델을 학습시키는 데 사용되는 학습 파이프라인(데이터 변환, 알고리즘 및 알고리즘 매개 변수)이 포함되어 있습니다.SentimentModel.zip: 이 파일은 직렬화된 zip 파일인 학습된 ML.NET 모델입니다.
모델을 시도하려면 콘솔 앱을 실행하여 모델을 사용하여 단일 문의 감정을 예측할 수 있습니다.
모델 사용
마지막 단계는 최종 사용자 애플리케이션에서 학습된 모델을 사용하는 것입니다.
-
myMLApp프로젝트의Program.cs코드를 다음 코드로 바꿉니다.Program.csusing MyMLApp; // Add input data var sampleData = new SentimentModel.ModelInput() { Col0 = "This restaurant was wonderful." }; // Load model and predict output of sample data var result = SentimentModel.Predict(sampleData); // If Prediction is 1, sentiment is "Positive"; otherwise, sentiment is "Negative" var sentiment = result.PredictedLabel == 1 ? "Positive" : "Negative"; Console.WriteLine($"Text: {sampleData.Col0}\nSentiment: {sentiment}"); -
myMLApp을 실행합니다(Ctrl+F5 또는 디버그 > 디버깅하지 않고 시작 선택). 입력 문이 양수인지 음수인지 예측하는 다음 출력이 표시되어야 합니다.![출력: 텍스트: 이 식당은 훌륭했어. 감정: 긍정적]()

ML.NET CLI가 학습된 모델과 코드를 생성했으므로 이제 다음 단계에 따라 .NET 애플리케이션(예: SentimentModel 콘솔 앱)에서 모델을 사용할 수 있습니다.
- 명령줄에서
consumeModelApp디렉터리로 이동합니다.Command promptcd SentimentModel -
코드 편집기에서
Program.cs를 열고 코드를 검사합니다. 코드는 다음과 유사해야 합니다.Program.csusing System; namespace SentimentModel.ConsoleApp { class Program { static void Main(string[] args) { // Add input data SentimentModel.ModelInput sampleData = new SentimentModel.ModelInput() { Col0 = @"Wow... Loved this place." }; // Make a single prediction on the sample data and print results var predictionResult = SentimentModel.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: @{"Wow... Loved this place."}"); Console.WriteLine($"Col1: {1F}"); Console.WriteLine($"\n\nPredicted Col1: {predictionResult.PredictedLabel}\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); } } } -
SentimentModel.ConsoleApp을 실행합니다. 터미널에서 다음 명령을 실행하여 이를 수행할 수 있습니다(SentimentModel디렉터리에 있는지 확인).Command promptdotnet run출력은 다음과 같이 표시되어야 합니다.
Command promptUsing model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data... Col0: Wow... Loved this place. Col1: 1 Class Score ----- ----- 1 0.9651076 0 0.034892436 =============== End of process, hit any key to finish ===============
다음 단계
축하합니다. ML.NET Model Builder를 사용하여 첫 번째 기계 학습 모델을 만들었습니다!
이제 기본 사항을 배웠으므로 Microsoft Learn의 자가 학습 모듈로 계속 진행합니다. 여기에서 센서 데이터를 사용하여 제조 장치가 고장났는지 여부를 감지할 수 있습니다.
Microsoft Learn: 예측 유지 관리 모델 학습
초보자용 ML.NET
Luis가 기계 학습과 AI의 개념을 소개하고, 이를 사용하여 수행할 수 있는 작업을 설명하고, OpenAI, Azure AI 서비스, ML.NET을 시작하는 방법을 안내합니다.
귀하는 다음 항목에도 또한 관심이 있을 수 있습니다...



축하합니다. ML.NET CLI를 사용하여 첫 번째 기계 학습 모델을 만들었습니다!
이제 분류에 ML.NET CLI(특히 감정 분석)를 사용했으므로 다른 시나리오를 시도할 수 있습니다. 택시 요금 데이터 세트를 사용하여 회귀 시나리오(특히 가격 예측)를 시도하여 ML.NET CLI를 사용하여 ML.NET 모델을 계속 빌드하세요.
초보자용 ML.NET
Luis가 기계 학습과 AI의 개념을 소개하고, 이를 사용하여 수행할 수 있는 작업을 설명하고, OpenAI, Azure AI 서비스, ML.NET을 시작하는 방법을 안내합니다.
귀하는 다음 항목에도 또한 관심이 있을 수 있습니다...