

Microsoft Defender 使用 ML.NET 阻止恶意软件
行业
技术
组织规模
大型(1,000-9,999 名员工)
国家/地区
美国
技术
公司
Microsoft Defender 高级威胁防护 (ATP) 是 Microsoft 的统一安全平台,用于智能预防性保护、违约后检测、自动调查和响应;它保护端点免受网络威胁,检测高级攻击和数据泄露,自动化安全事件,并结合使用云、行为分析和机器学习的强大功能改进安全态势。
业务问题
Microsoft Defender ATP 每天处理数万亿信号,每个月则处理 50 亿个新出现的威胁。这些威胁从试图钓鱼用户凭据的 PDF 和包含武器化宏的文档文件,到包含多态恶意软件可执行文件的受密码保护的 zip 文件,不一而足。
能够在第一时间预测和阻止这些威胁对于保护客户端安全至关重要。但人类一次能够查看和记住的信息是有限的。手动完成其中每个属性都是一项耗时的任务,并且速度很慢,无法抵御传入的威胁。鉴于每月出现的新型威胁的规模,人工手动流程根本无法扩展,这使得机器学习不仅是适合此项任务,更是保护用户的必要手段。此外,有人可能会查看一个恶意软件并发现导致其成为恶意软件的属性,但实际上,该恶意软件可能具有数十万个其他属性指示存在威胁,但人类无法花时间一一确定。
另一方面,计算机具有更大的容量和更快的响应时间;它们可以即时查看所有(可能数十万个)潜在威胁的属性,并选取将威胁标记为恶意软件的所有属性。然后,计算机可以使用其找到的属性来发现人类仅使用少量属性可能无法预测的新恶意软件。

因此,Microsoft Defender ATP 决定利用机器学习和 ML.NET(从技术上讲,它使用名为 TLC 的 ML.NET 衍生产品,它是 Microsoft 在过去 10 多年里使用的内部机器学习框架)来增强针对恶意软件的实时防护,以便能够更轻松、准确地预测信号是否为恶意并组织传入的威胁,以保护其用户的计算机安全。
ML.NET 的影响
Microsoft Defender ATP 使用分类算法来标记和显示威胁(包括以前看不到的威胁),否则这些威胁在数十亿个正常事件中仍然无法觉察,并且第一代传感器无法对不熟悉和细微的刺激做出反应。Microsoft Defender ATP 的模型优化了 Microsoft Defender ATP 可用的大量数据和计算资源的使用。此外,根据 Microsoft Defender ATP 对实际警报的分析,所使用的机器学习技术至少比手动设计的启发技术精确 20%。ML.NET 的受监督机器学习算法在预泄露级别阻止了 35% 的威胁,从而抵御了恶意 URL、电子邮件附件和其它新出现威胁中恶意软件的侵害。
解决方案体系结构
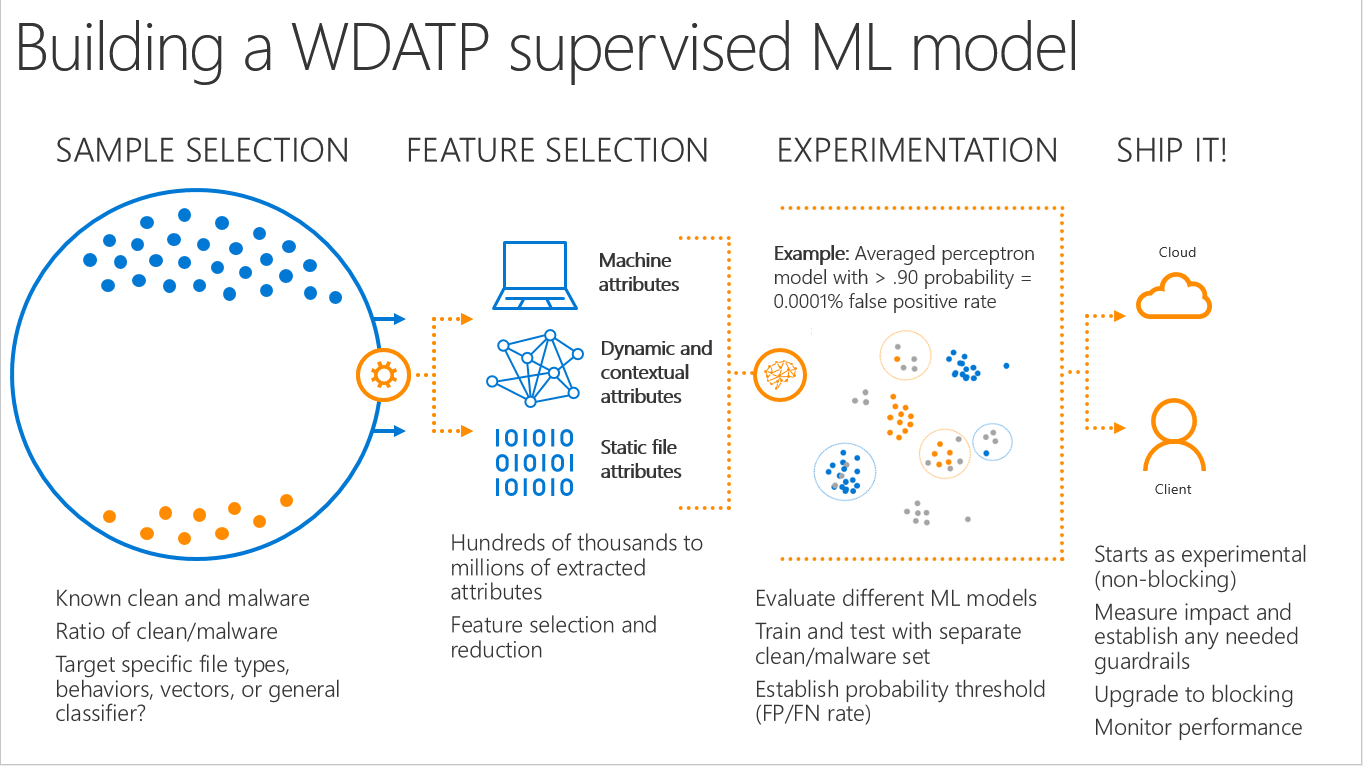
数据处理和功能选择
对于 Microsoft Defender ATP,拥有一组包含训练数据集中的清理数据和恶意软件的大量标记的训练数据非常重要,这使得它可以模仿实际应用场景,并演示真正的客户每天所看到的内容。以平均训练周期计算,Microsoft Defender ATP 中的一个模型可能占用大约 1 亿行数据,其中每个行都有 190,000 个功能。
在训练检测恶意软件的模型时,选择好特性非常重要。研究人员和计算机查找两种类型的功能: 静态文件特性和行为组件。静态文件属性包括如文件已签名、签名者和各种模糊哈希之类的内容。行为特性包括以下内容(如文件与其他文件相关)、此文件是否从其他文件中插入,文件所连接到的 LP 以及对系统所做的更改。训练数据集可包含几千到几百万种特性。
模型定型
Microsoft Defender ATP 有多种模型可用于多种用途。例如,它们有一些模型侧重于首次发现的 PE 威胁、宏威胁和基于脚本的攻击。还有一些模型侧重于基础数据;例如,一些模型专门针对文件的模糊哈希进行训练。除此之外,它们还有另一层集成模型,这些模型从这些单独的分类器接收信号,再次检查系统活动是否是恶意的。
Microsoft Defender ATP 每天对最新数据训练这些模型。模型经过训练后便会保存下来,工程管道会将其加载到 Defender 云基础结构,在那里由客户端进行查询。
[模型]多样化对于拥有篡改-可复原的机器学习系统非常重要。”
使用 ML.NET 算法,Microsoft Defender ATP 能够生成大量机器学习模型,以更有效地保护其用户免受潜在威胁,使 5 亿人的计算机免受恶意软件的攻击。