

endjin 用 ML.NET 彻底改变了简单任务

行业
信息技术和服务
组织规模
小型(1-100 名员工)
国家/地区
英国
技术
公司
Endjin 是一家位于英国的精品企业,提供技术咨询服务,并且是 Microsoft 云平台、数据平台、数据分析和 DevOps 的金牌合作伙伴。Endjin 对技术的革命性力量充满热情,并且热衷于利用这种力量帮助客户解决难题,这种热情极具感染力。最近,他们专注于使用机器学习来解决平凡但高价值的商业问题。这表明,虽然机器学习非常适用于解决新用例,但其彻底改变简单的日常任务的能力往往受到忽视。
AutoML 和 ML.NET 的易用性让我们十分惊讶,它们可用来减少耗时和枯燥的任务所花费的时间。借助这些易于访问且功能强大的技术,我们可以将宝贵时间集中在创造性的思维导向分析上,并从它们产生的数据中获取有价值的见解。”
业务问题
2014 年,endjin 创建了 Azure 周报,一个免费新闻稿,总结了 Azure 生态系统中本周的热门新闻。对于前 25 个问题,endjin 的团队手动特选新闻稿,但是随着内容量的增长,他们意识到这是不可持续的。他们应用了公司的座右铭 “更智能地工作”,并通过创建自己的自定义 C# 文本分类器,将 300 多篇博客中的文章分类为 19 个类别,包括 AI + 机器学习、分析、DevOps、物联网、网络和 Web,从而自动完成端到端过程。此操作效果相对良好,但除了需要保留要分类的关键字有效列表外,每周还需要手动更正,这会导致重大维护开销。
在出现 200 多个问题和成千上万的订阅者之后,endjin 决定开始研究机器学习解决方案。他们知道在内容平台的中心,他们有两个核心问题需要解决 - 二元分类问题(“这是一篇有关 Azure 的文章吗?”)和多分类问题(“这篇文章涵盖了 Azure 的哪个区域?”)。因此,endjin 决定使用 ML.NET,以便解决这些问题、改进他们的平台,并去除手动维护开销。
当你查看大多数组织执行的工作/流程时,可以将它们分解为一系列的 1 秒决策步骤。如果你将机器学习、反应式工作流和 API 经济应用于问题空间,我们将开始了解 第四次工业革命可以带来什么影响的核心”
为什么选择 ML.NET?
虽然他们选择的编程语言是 C#,但由于以前缺少适用于 .NET 的一流机器学习框架,endjin 一直在面向客户的日常数据科学和 ML 试验中使用 R 和 Python。但是,由于托管选项有限,以 R 和 Python 编写的机器学习模型的生产存在问题。endjin 的其余内容平台是使用 PaaS 和无服务器组件构建的,因此,ML.NET 和 Azure Functions 的组合对公司非常有吸引力。在 //build 2018 ML.NET 宣布后,他们就立即开始将机器学习框架用于其应用。
ML.NET 和 AutoML 的影响
ML.NET 的高性能极大地帮助了 endjin,不仅包括对项目进行分类时的速度改进,在准确性方面也是如此。自采用 ML.NET 以来,它们看到的误分类文章要少得多,这就减少了手动干预,加快了内容生产速度。
将 ML.NET CLI 与 AutoML 结合使用,让整个训练、评估和生成代码,以使用 ML.NET 的整个流程变得再简单不过。使用 AutoML 选择最佳模型,并自动生成分类的训练和用于分类消耗量(与手动选择数据转换、算法和算法选项来创建 ML.NET 模型和代码相比),可将模型精度从 68% 提升到 78%,并且对照历史数据运行此模型不仅能够突出显示被错误分类的许多文章,还能发现许多被原始分类模型排除的有效文章。
解决方案体系结构
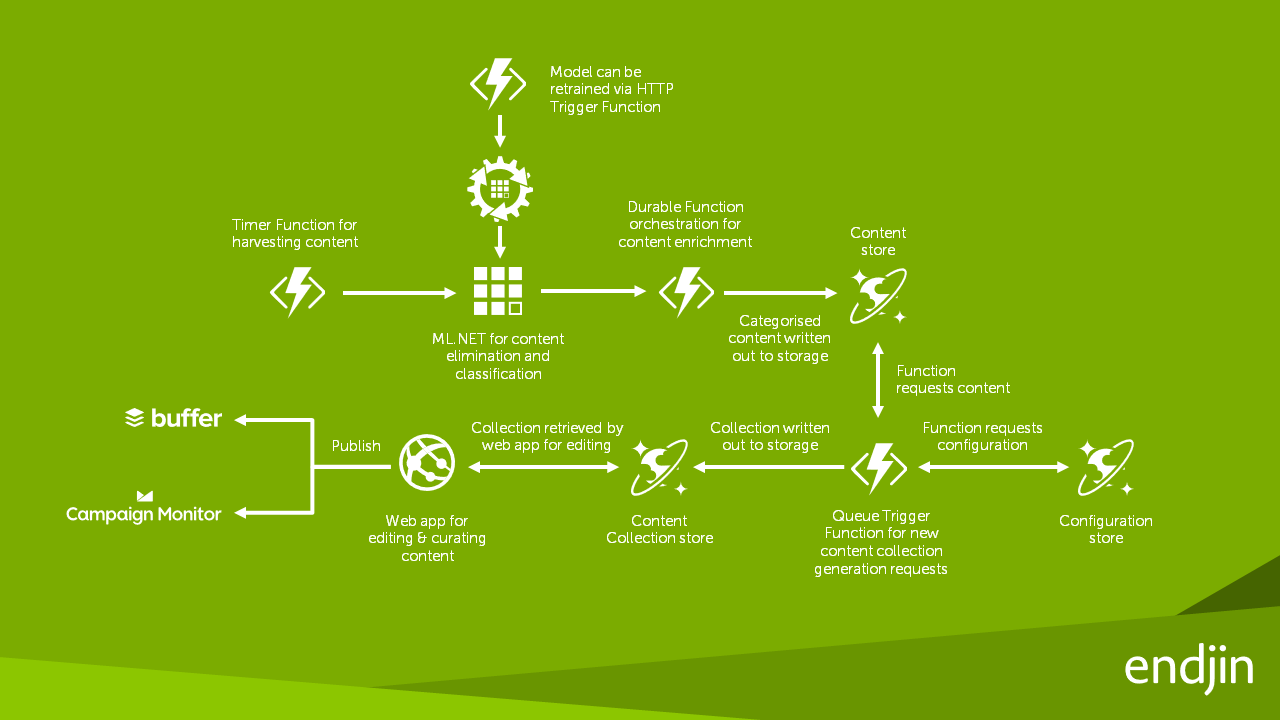
使用 ML.NET 创建应用程序
endjin 最初开始使用 ML.NET 时,他们创建了将历史内容平台数据转换为 CSV数据集的工具,以手动训练 ML.NET 模型,并创建了另一个工具以随机选择 20% 的训练数据集作为验证数据集。然后,他们手动创建了 ML.NET 模型来预测文章所属类别。
可以使用具有 AutoML 功能的 ML.NET CLI 后,将简化进程并生成明显更好的结果。首先,AutoML 能自动从训练数据集生成验证数据集,因此不再需要 endjin 的第二个自定义工具。其次,设置一个小时的最大探索时间,AutoML 能够训练、调整和评估多个分类模型并显示前 5 个模型。
在 endjin 拥有由 AutoML 生成的已接受训练的 ML.NET 模型后,它们已将模型集成到现有内容平台中,只需交换现有的自定义分类算法即可。ML.NET 模型托管在 Azure 函数内,以启用模型评估的弹性缩放。新的 Durable Function 用于允许按需重新训练模型。
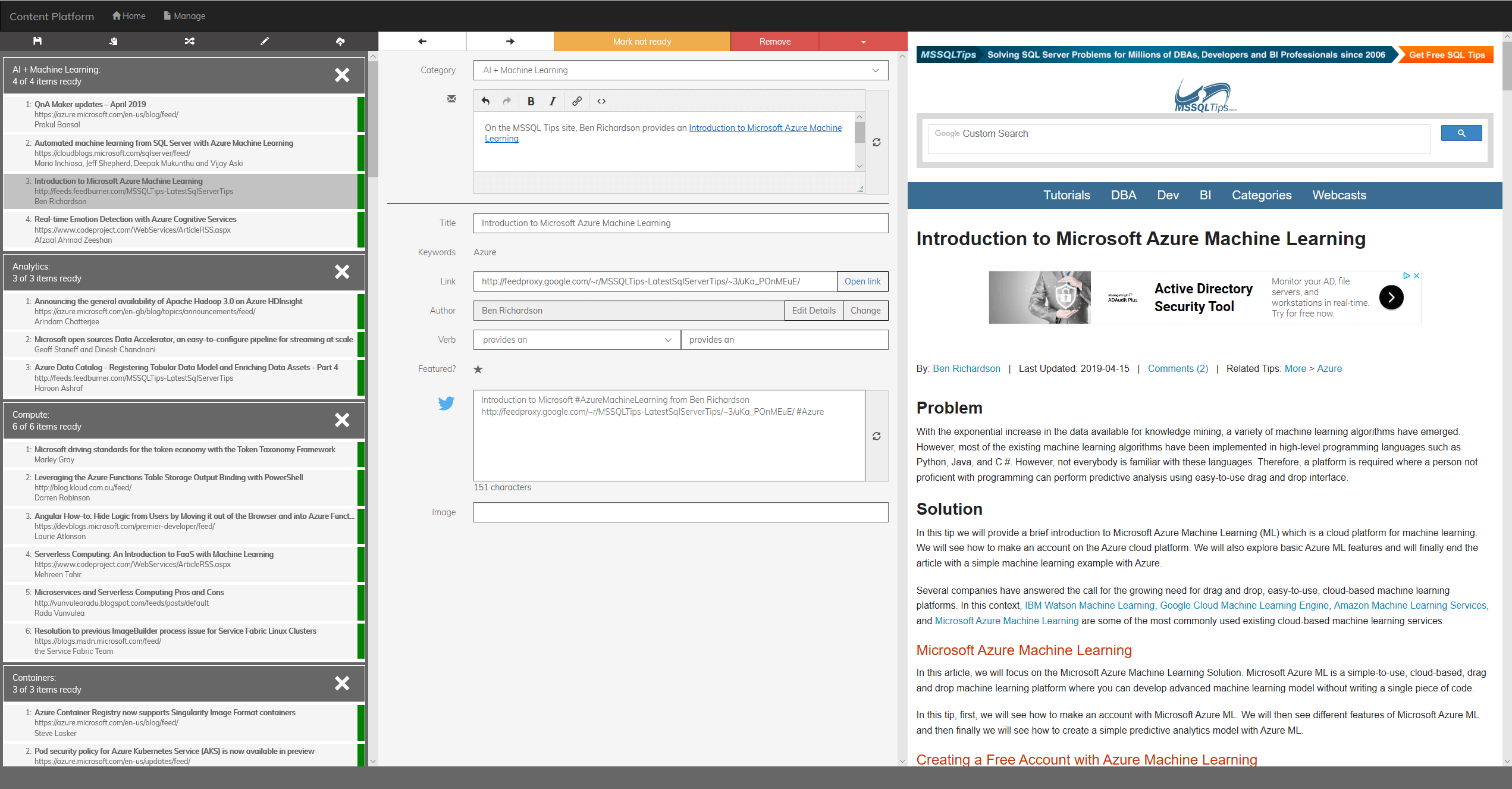
数据处理
幸运的是,endjin 团队在构建内容平台的原始版本时就希望未来能使用机器学习进行改进,因此他们以原始格式和已处理格式(超过 4000 个 JSON 文件,总大小约为 3 GB)保留了用于生成新闻稿的所有数据。这些数据集转换为两个训练数据集: 一个 28 MB,用于二进制分类的 CSV 文件,以及 9 MB,用于多类分类的 CSV 文件。
数据转换和机器学习算法
由于要分类的博客文章的标题和内容都为自由文本,因此需要使用 特征化文本 数据转换对两者进行转换。然后,使用 Concatenate 数据转换使标题和内容一同联接到单一字段。
endjin 手动创建的原始模型使用 SdcaMaximumEntropy 多类分类算法。但是,当 endjin 将 ML.NET CLI 和 AutoML 配合使用时,其发现了适用于其场景的更高性能的模型。
对于第一个场景(“这是一篇关于 Azure 的文章吗?”),AutoML 选择 AveragedPerceptronBinary 作为性能最佳的算法。对于第二个场景(“本文涵盖 Azure 的哪个区域?”),AutoML 选择 LightGbmMulti 作为性能最高的算法,并生成以下代码来训练多类分类器:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin 使用 ML.NET 改进了为 Azure 新闻稿选择和分类文章的流程。使用 ML.NET 和 AutoML 生成机器学习模型也帮助该公司减少了对微调模型参数的关注,转而更专注于提供商业价值。