

Power BI は、ML.NET を使用する主要なインフルエンサーを特定します
業界
テクノロジ
組織の規模
企業(従業員数 10,000 人以上)
国/地域
米国
テクノロジ
会社
Power BI は、ユーザーがデータをビジュアル化したり、組織全体で分析情報を共有したり、アプリに埋め込んだりできるようにする、Microsoft が開発したビジネス分析ソリューションです。Power BI は、ユーザーがデータからレポートを作成するのに役立つ、グラフ、グラフ、ゲージなどのさまざまなデータ可視化を提供します。最近、Power BI は、組織内の全員が AI の能力を活用してより良い意思決定を行うために、機械学習を活用してユーザーの複雑なタスクを簡略化してきました。2019 年 2月 に Power BI、最初の AI を使用したデータ視覚化である Key Influencersのプレビューを行いました。これは、バックグランドで ML.NET を使用して、自然な方法でデータの理由付けを行い、分析情報を表示します。]
ビジネスの問題
どの企業でも、主要なインフルエンサー (業績と成果の主な推進要因) と顧客セグメントを特定して理解することは、戦略的なビジネス上の意思決定を行い、ビジネスの変更に優先順位を付け、競争上の優位性を獲得するために重要です。 主要なインフルエンサーを分析すると、どの要因が業績に最大の影響を与えるかを明らかにできます。また、"顧客がこのサービスについて否定的なレビューを残す要因は何か" や "住宅価格の上昇に影響を与えるものは何か" などの質問に企業が答えるのに役立ちます。
ただし、主要なインフルエンサーや顧客セグメンテーションのためのこのデータ分析のプロセスには、多くの時間、労力、専門知識が必要であり、複数の関数のコーディング、サンプリング、有意差検定、結果のランク付けなどが行われることが多くあります。そこで、Power BI は、ユーザーが意味のある分析情報を得るためのプロセスを高速化し、複雑なコードを書く必要なく統計分析を行うことができるようにするために、機械学習ソリューションを導入しました。
主要な影響元と ML.NET
Power BI は、機械学習ソリューションとして主要なインフルエンサーの視覚化を作成しました。これにより、企業は AI を活用して、データをより短時間で分析し、重要なビジネス上の意思決定をより迅速に行うことができます。言い換えると、ユーザーは主要なインフルエンサーを使用して、データの分析に費やす時間を減らし、AI 視覚化から収集された分析情報への取り組みにより多くの時間を費やすことができます。
ユーザーが分析のために主要業績評価指標 (KPI) を選択した場合 (たとえば、保持率、クリックスルー率など)、主要なインフルエンサーは ML.NET が提供する機械学習アルゴリズムを使用して、指標を促進する最も重要な点を把握できるほか、より詳しい調査対象となる興味深いセグメントを見つけることができます。主要なインフルエンサーは、ユーザーのデータを分析し、重要な要素をランク付けし、それらの要素の相対的重要度を対比させ、カテゴリ別と数値別の両方の指標について、主要なインフルエンサーと最上位のセグメントとして表示します。
ソリューション アーキテクチャ
Power BI は、複数の形式で出荷されます。 キー インフルエンサーの視覚化は、モバイル、デスクトップ、共有サービス、プレミアム サービスの形式でサポートされています。
ユーザーが Key Influencer ビジュアルに列を追加すると、トレーニング データがAnalysis Services (Power BI の背後にあるデータベース エンジン) に送信されるフローがトリガーされます。Analysis Services ML.NET を実行して機械学習モデルをトレーニングし、結果が返されます。したがって、選択した機能をユーザーが更新するたびにモデルがトレーニングされます。全体的な目標は、数秒で分析を実行し、対話型エクスペリエンスを有効にすることです。
全体的なフローを以下に示します。
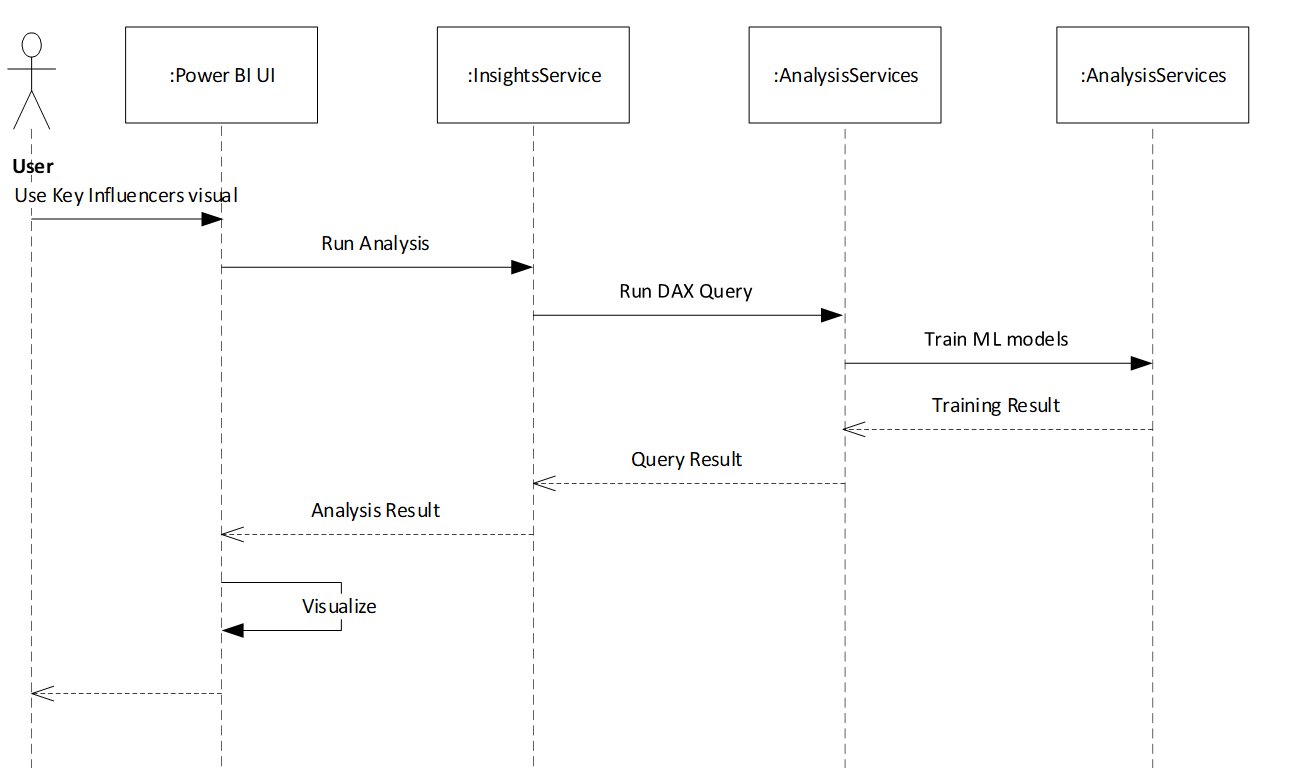
ML.NET は、.NET Framework ライブラリとして使用され、オンプレミスで実行されます (Power BI Desktop で使用されている場合) またはクラウド (Power BI サービスで使用されている場合)。 Power BI のデータセットは、Analysis Services にネイティブなバイナリ形式で保存されます。
カテゴリ別主要なインフルエンサー
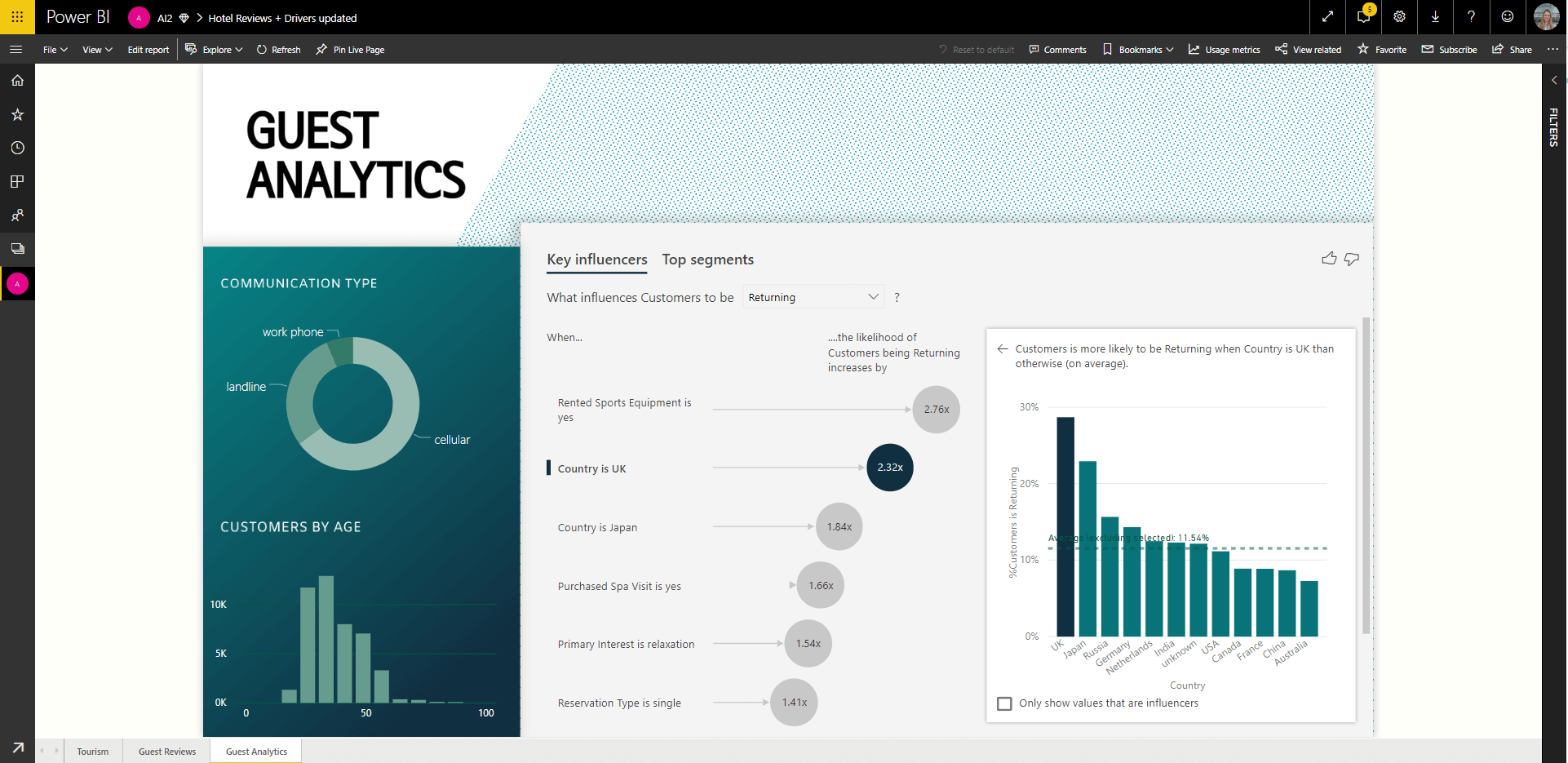
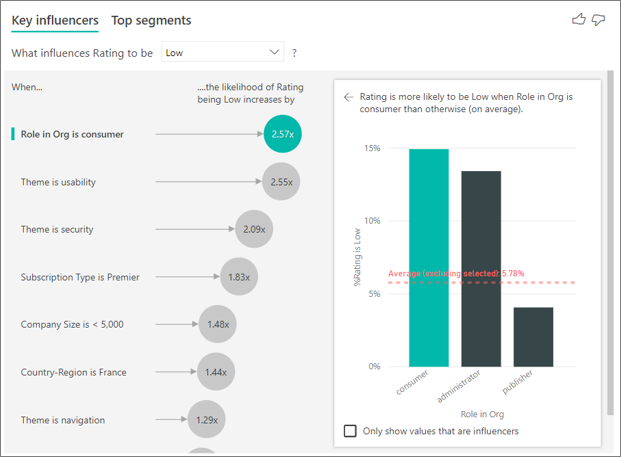
カテゴリ別のメトリックには、評価やランク付けなどが含まれます。次の例では、メトリックは Rating で、視覚化によって、組織内のロールが使用者で、低評価の確率に影響を与える上位の単一要素であると判断されています。視覚化では、次のような追加情報が右側のペインに表示されます:
- 14.93% の 消費者 が低いスコアを付けます。
- 他のすべての役割は、平均して時間の 5.78% に低いスコアを与えます。
- 消費者 は、他のすべての役割と比較して、2.57 倍低いスコアをつけています。
主要なインフルエンサーは、ML.NET を使用して、ワンホット エンコーディング、欠損値の置き換え、平均分散の正規化、および L-BFGS ロジスティック回帰 アルゴリズムを使用したカテゴリー別の指標にロジスティック回帰を実行します。この場合、アルゴリズムはデータ内のパターンを検索し、低評価を与えた顧客と高評価を与えた顧客がどのように異なるかを調べます。たとえば、サポート チケットを多く持つ顧客は、サポート チケットがほとんどないか持っていない顧客よりも、低評価の割合が高いことが明らかになる場合もあります。
数字で見る主要なインフルエンサー
数値メトリクスには、価格や販売数などが含まれる場合があります。下の例では、指標が「住宅価格」で、その可視化では、「キッチン品質が優れている」が住宅価格が上昇する可能性に影響を与える上位の単一要因であると判断されています。
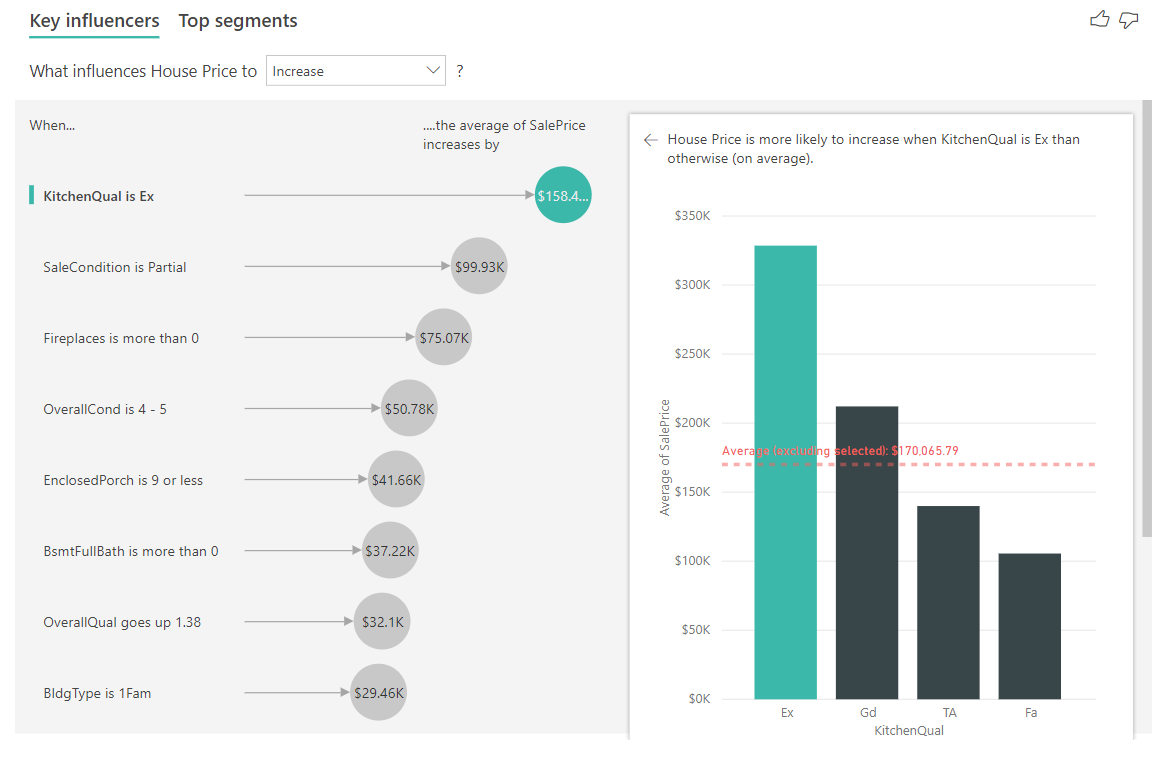
主要なインフルエンサーは、ML.NET を使用して線形回帰を実行します。カテゴリ別の主要なインフルエンサーと同じデータ変換を用いて、SDCA 回帰 アルゴリズムを使用します。この場合のアルゴリズムでは、寝室数や床面積などの説明因子に基づいて住宅価格がどのように変化するかに目を向けています。この場合は、すばらしいキッチンが住宅価格に与える影響を調べています。
上位セグメントの計算
上位セグメントでは、選択されたメトリック値に寄与する上位グループを表示します。セグメントは、複数の値の組み合わせで構成されます。たとえば、以下のセグメントは、消費者または管理者で、サポート チケットが 4 枚以上あり、29 か月以上顧客であるユーザーです。このセグメント内の顧客の 74.3% が低評価を付けているのに対し、平均的な顧客が低評価を付けている割合は 11.7% でした。
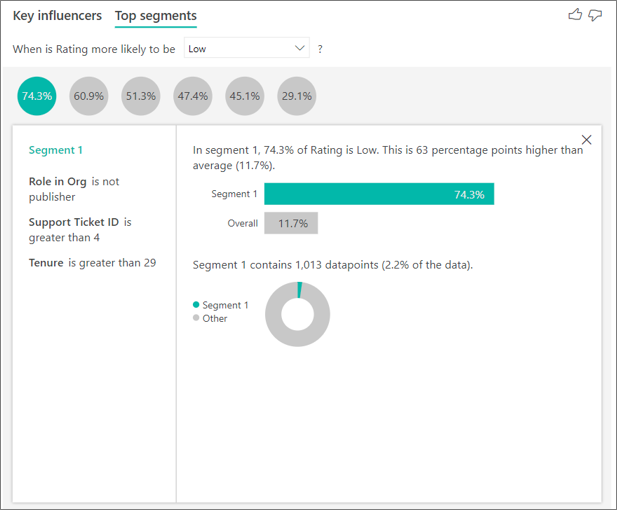
上位セグメントでは、ML.NET を使用して、高速木 アルゴリズム (カテゴリー別および数値別) を使用した決定木を実行し、興味深いサブグループを見つけます。その目的は、興味深い指標で相対的に高いデータ ポイントのサブグループを最終的に見つけることです。これには、評価の低い顧客や、価格の高い家などがあります。
アルゴリズムは、各説明因子を受け取り、どの因子が最適な分割をもたらすかを理由付けしようとします。決定木は分割を行った後、データのサブグループを取り出し、そのデータに対して次の最適な分割を決定します。この例では、セキュリティに関してコメントした顧客がサブグループになります。各分割後、このグループがパターンを推定する代表として十分なデータ ポイントを持っているか、またはデータに異常があり実際のセグメントではないか検討します。決定木の実行後は、セキュリティに関するコメントや大企業などのすべての分割結果が取り込まれ、セグメントが作成されます。
Power BI では、ML.NET を使用することで、顧客がビジネスにおける主要なインフルエンサーを簡単に特定できるようになり、顧客は時間と労力を節約し、ML.NET モデルから生み出される分析と分析情報に基づいて、変更点やビジネスの意思決定にフォーカスできるようになります。