

HMRI、ML.NET を使用した医学研究のための Human-In-The-Loop ML フレームワークを構築

業界
医療
組織の規模
大規模 (1,000 ~ 9,999 人の従業員)
国/地域
オーストラリア
テクノロジ
会社
ハンター医学研究所 (HMRI) は、コミュニティの健康とウェルビーイングの向上を目的とした組織です。科学者、臨床医、公衆衛生の専門家が一同に会して、新しく、より良い健康解決策を迅速に提供することによって、これを実現します。
ハンター医学研究所 (HMRI) は、コミュニティの健康とウェルビーイングの向上を目的とした組織です。科学者、臨床医、公衆衛生の専門家が一同に会して、新しく、より良い健康解決策を迅速に提供することによって、これを実現します。
研究の詳細は、「A method for rapid machine learning development for data mining with Doctor-In-The-Loop」 (Neva J Bull、Bridget Honan、Neil J. Spratt、Simon Quilty) の論文に記載されています。
ビジネスの問題
医療機関には大量のデータがあります。通常、このデータは非構造化テキスト形式です。デジタル化された場合でも、データから意味のある実行可能な分析情報を抽出することが困難な場合がよくあります。正規表現、SQL クエリ、自然言語処理ソフトウェアなどの手法では、その成功は限られたものになります。
そのような場合、機械学習はデータから価値ある情報を分析し、抽出するのに役立ちます。これまでにも、機械学習ツールは、さまざまな臨床および研究目的で、臨床記録をカテゴリーに分類するために以前に使用されています。しかし、これらの機械学習ツールを使用するには、ソフトウェア開発やデータ サイエンスのスキルが必要な場合が多くあります。このようなスキルは、医療専門家の範囲を超えていることが多く見られます。
モデルのトレーニングを行うシナリオでも、教師なしで実施すると、モデルは実際に使用する場合に最適でない結果を出すことになります。医療的な判断には高いリスクが伴うため、専門知識を持つ医療専門家がモデルを信頼し、モデルが間違っている場合は、専門知識を生かしてフィードバックを行うことが重要です。
そのため、HMRI の研究者は、ML.NET を使用して Human-In-The-Loop (HITL) 機械学習開発フレームワークを開発し、医療専門家がプログラミングや機械学習の経験がなくてもデータのラベル付けを行い、モデルをトレーニングし、モデルの推論に簡単に使用できるようにしています。さらに重要なのは、医療専門家が自らのスキルや専門知識を機械学習プロセスに組み込むことができるように、フィードバック メカニズムを構築したことです。その結果、この高レベルの監視により、実際のユース ケースで、少ないデータ ポイントでより良い結果を得られるようになります。
ML.NET を選ぶ理由
HMRI は Model Builder を使用して、ML.NET の使用を開始しました。Model Builder は、機械学習を使用して問題を解決できるかどうかを迅速に検証する方法を提供しました。問題に対して機械学習を使用することの有効性を検証した後、ML.NET 自動機械学習 (AutoML) API を活用しました。ML.NET AutoML API は、カスタム HITL 機械学習開発フレームワーク内で、アルゴリズムの選択とパイプラインおよびハイパーパラメーターの最適化を自動的に選択しました。
ML.NET の影響
HMRI は Model Builder を使用して、ML.NET の使用を開始しました。Model Builder は、機械学習を使用して問題を解決できるかどうかを迅速に検証する方法を提供しました。問題に対して機械学習を使用することの有効性を検証した後、ML.NET 自動機械学習 (AutoML) API を活用しました。ML.NET AutoML API は、カスタム HITL 機械学習開発フレームワーク内で、アルゴリズムの選択とパイプラインおよびハイパーパラメーターの最適化を自動的に選択しました。
ML.NET を使用することで、HMRI は開発作業を外部に委託する必要がなくなり、既存のスキルやリソースを使用して、すべて社内で構築できるようになりました。
さらに、ソリューションの一部として ML.NET を活用することで、医療専門家がプログラミングや機械学習の経験を必要とせずに機械学習モデルをトレーニングして使用するためのインターフェイスを提供することができました。
ソリューション アーキテクチャ
ユーザーが操作するインターフェイスは、モデルのトレーニングと消費のフェーズにおけるいくつかのタスクをサポートする Web アプリケーションです。
データ
初期実装では、モデルのトレーニングに使用されたデータは、過去の医療記録から取得したものです。使用した 1 つのデータセットには、40 年間の死亡データベースで約 30,000 件の記録があり、もう 1 つには航空医療検索データで、約 13,000 件の記録があります。
データは、SQL Server データベースに格納されます。トレーニングの前に、医療専門家は Web アプリケーションを使用してテスト セットを事前定義済みのカテゴリーにラベル付けし、トレーニング ループ中に精度メトリックを計算します。次に、ランダムに選択された小規模なデータセットがトレーニングの最初のラウンドに使用されます。
トレーニング、評価、および消費のワークフロー

モデルのトレーニングは、医療専門家が Web アプリケーションからトリガーします。サーバー側の ML.NET コードは、モデルのトレーニングと再トレーニングを処理します。その後、モデルは、残りのすべてのデータを予測します。予測値と信頼度スコアは、SQL Server データベースに格納されます。SQL Server ストアド プロシージャは、テスト セットに対して精度メトリックを計算および格納するために使用されます。これらのメトリックは、Web アプリケーションを介して医療専門家に表示されます。このプロセス全体は数秒で完了します。
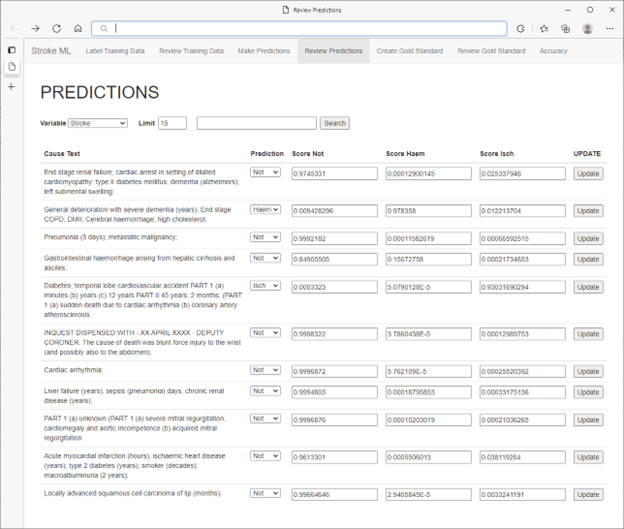
* 実際の患者データではありません
医療専門家は、ラベル付けするケースの追加選択をガイドするために、再現率と特異度のメトリックを直感的に使用でき、その結果、モデルのパフォーマンスを最大および迅速に向上させられることを発見しました。さらに、信頼度スコアによる並べ替えに基づいて選択的にターゲットのラベル付けを行うことで、パフォーマンスがさらに向上しました。そうすることで、医療専門家は低スコアと予測されたケースを確認するだけでなく、高いスコアと予測された間違ったケースを修正することで、アクティブ ラーニングに取り組んでいます。
この時点で、医療専門家は、修正されたデータ ラベルを使用してモデルを再トレーニングするジョブを開始できます。このラベル、トレーニング、評価のループは、医療専門家がモデルのパフォーマンスに満足するまで続けられます。トレーニング イベントのタイムスタンプ、評価メトリック、その他の情報は、SQL Server データベースに記録され、後で検査と監査を行うことができます。
ラベル付け、トレーニング、評価ループが完了すると、SQL Server の組み込み乱数ジェネレーターを使用して、SQL Server データベースから予測値の検証セットが選択されます。これらのデータ ポイントは、モデルの予測に対して盲検化された医療専門家のパネルによってラベル付けされました。
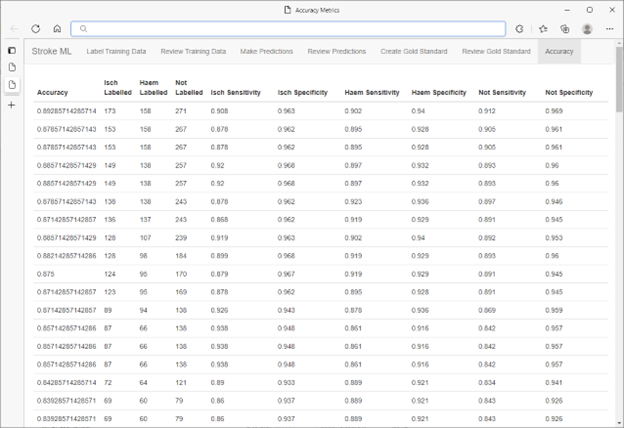
モデルの結果の精度は、90% 台半ばから後半でした。この結果は、研究者が現在実施している医学研究において、モデルによって生成された分類を使用することに自身を与えるものでした。ML.NET の高速性と HITL ワークフローの組み合わせにより、精度を落とすことなく、さまざまな分類タスクや異なるデータ セットに対して、非常に効率的で費用対効果の高い方法で繰り返し実行できるようになりました。
今後の予定
HMRI 研究者によって開発された Doctor-In-The-Loop ワークフローは、医療用フリーテキストの迅速かつ正確な分類に依存する今後の研究にとって非常に重要なものであることを証明します。