

endjin は ML.NET で簡単なタスクに革命をもたらします

業界
情報テクノロジとサービス
組織の規模
Small (1-100 の社員)
国/地域
イギリス
テクノロジ
会社
Endjin は、英国に拠点を置く、クラウド プラットフォーム、データ プラットフォーム、Data Analytics、および DevOps に関する Microsoft Gold パートナーのブティック型ビジネスおよびテクノロジー コンサルティング企業です。Endjin は、テクノロジーの革新的な力と、その力を利用して顧客が困難な問題を解決するためのサポートを情熱的に行っています。最近では、機械学習を使用して、ありふれてはいるものの価値の高いビジネスの問題を解決することに力を入れています。これにより、機械学習は斬新なユース ケースを解決するのに適している一方で、日常の単純な作業に革命をもたらす機能が見落とされがちであることがわかりました。
AutoML や ML.NET を使用することで、時間のかかる単調な作業に費やす時間を簡単に削減できることに驚いています。これらのアクセス可能で強力なテクノロジーを使用することで得られる自由は、創造的な思考に基づく分析や、生成されたデータから価値ある分析情報を得る時間にフォーカスすることができます。"
ビジネスの問題
2014 年、endjin は、Azure エコシステムにおける週間トップ ニュースをまとめた無料のニュースレター Azure Weekly を創刊しました。最初の 25 号までは、endjin チームが手作業でニュースレターを管理していましたが、コンテンツの量が増えるにつれ、これでは持続できないと考えました。endjin チームは、会社のモットーである "work smarter" を適用し、独自のカスタム C# テキスト分類器を作成して、300 以上のブログ記事を AI + Machine Learning、Analytics、DevOps、モノのインターネット (IoT)、Network、Web などの 19 のカテゴリに分類することで、エンド ツー エンドのプロセスを自動化しました。これは比較的良く機能していましたが、分類するためのキーワードのアクティブなリストを維持する必要があることに加え、毎週手作業での修正が必要であり、メンテナンスの大きなオーバーヘッドが発生していました。
200 部以上の発行数と何千人ものサブスクライバーを抱え、endjin は機械学習ソリューションの検討を開始することにしました。それは、コンテンツ プラットフォームが解決する必要のある 2 つの中核的な問題である、二項分類問題 ("これは Azure に関する記事ですか?") と多項分類問題 ("この記事は Azure のどの領域をカバーしていますか?") です。これらの問題を解決し、プラットフォームを改善し、手作業によるメンテナンスのオーバーヘッドをなくすために、endjin は ML.NET を使用することを決定しました。
ほとんどの組織によって実行されている作業/プロセスを確認するときに、1 秒でできる判断手順の一式に分割できます。機械学習、リアクティブ ワークフロー、および API 経済を、問題領域に適用すると、第 4 次産業革命 の核心に迫り始めることになります。"
ML.NET を選ぶ理由
選択したプログラミング言語は C# ですが、以前は .NET 用のファーストクラスの機械学習フレームワークがなかったため、endjin はデータ サイエンスと ML の実験に直面する日々の顧客に R と Python を使用していました。 ただし、R と Python で記述された機械学習モデルの本番化は、ホスティング オプションが限られているため問題がありました。 endjin の残りのコンテンツ プラットフォームは PaaS およびサーバーレス コンポーネントを使用して構築されているため、ML.NET と Azure Functions の組み合わせは会社にとって非常に魅力的でした。 ML.NET が //build 2018 で発表されるとすぐに、アプリで機械学習フレームワークの使用を開始しました。
ML.NET と AutoML の影響
endjin は、記事を分類する際の速度の向上だけでなく、精度の点でも、ML.NET の高性能から大きな恩恵を受けています。 ML.NET を採用して以来、誤分類された記事がはるかに少なくなりました。これは、手動による介入が少なくなり、コンテンツの作成が速くなることを意味します。
ML.NET CLI を AutoML と併用することで、確実にML.NET を使用するための学習、評価、コードの生成のプロセス全体を作成することもできます。AutoML を使用して最高性能のモデルを選択し、分類 (データ変換、アルゴリズム、アルゴリズム オプションを手動で選択して ML.NET モデルとコードを作成するのと比較します) のためのモデル学習と消費コードを自動的に生成すると、モデルの精度が 68% から 78% に向上し、このモデルを過去のデータに対して実行することで、誤って分類された多くの記事が強調表示されるだけでなく、元の分類モデルでは除外されていた多くの有効な記事も特定することができました。
ソリューション アーキテクチャ
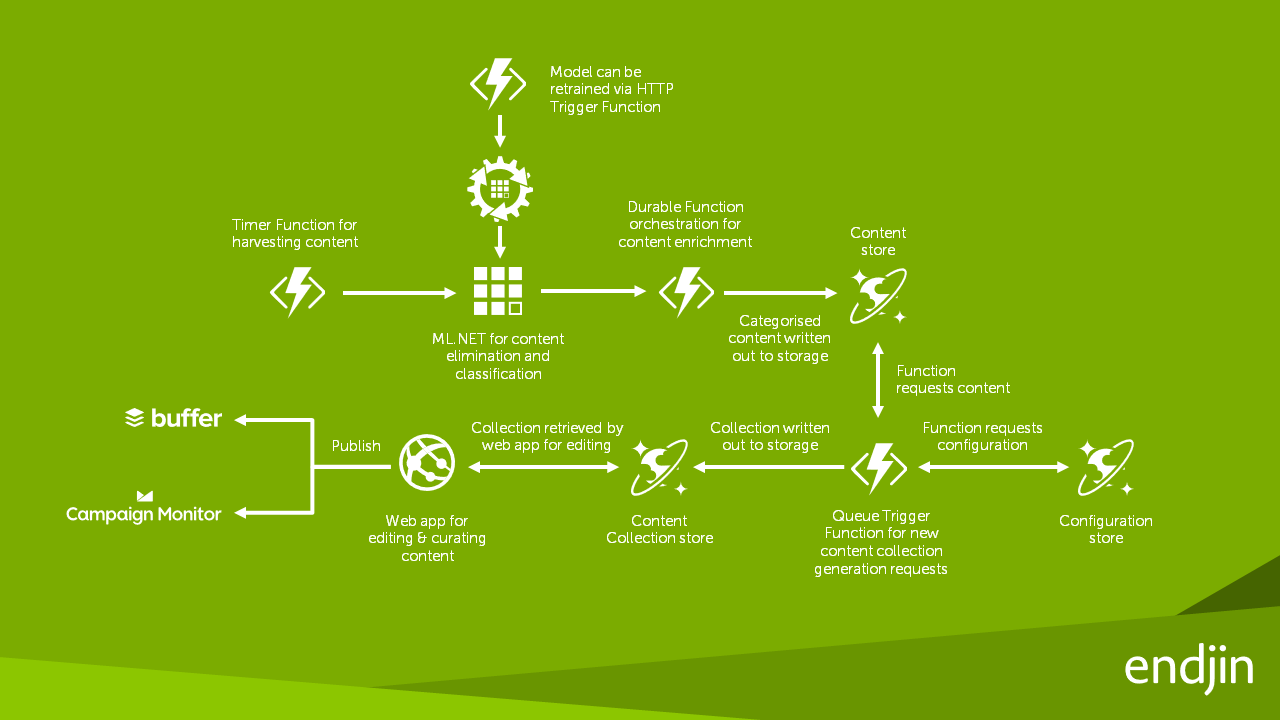
ML.NET を使用してアプリケーションを作成する
endjin が初めて ML.NET の使用を開始したとき、コンテンツ プラットフォームの履歴データを CSV データセットに変換するツールを作成し、ML.NET モデルを手動でトレーニングするツールと、トレーニング データセットの 20% を検証データセットとしてランダムに選択するツールを作成しました。次に、ML.NET モデルを手動で作成して、記事がどのカテゴリに属しているかを予測しました。
AutoML を搭載した ML.NET CLI を使用できるようになると、プロセスが簡素化され、大幅に良い結果が生成されるようになりました。まず、AutoML は学習データセットから検証データセットを自動的に生成するため、endjin の 2 つ目のカスタム ツールは必要なくなります。次に、最大探索時間を 1 時間に設定したところ、AutoML は複数の分類モデルの学習、調整、および評価を行い、パフォーマンスの高い上位 5 つのモデルを表示することができました。
AutoML によって生成された学習済み ML.NET モデルを endjin が所有すると、既存のコンテンツ プラットフォームにモデルを統合し、既存のカスタム分類アルゴリズムを切り替えるだけです。ML.NET モデルは、Azure Function の内部でホストされ、モデル評価を弾力的に拡張することができます。また、新しい Durable Function を使用することで、必要に応じてモデルを再学習できるようになりました。
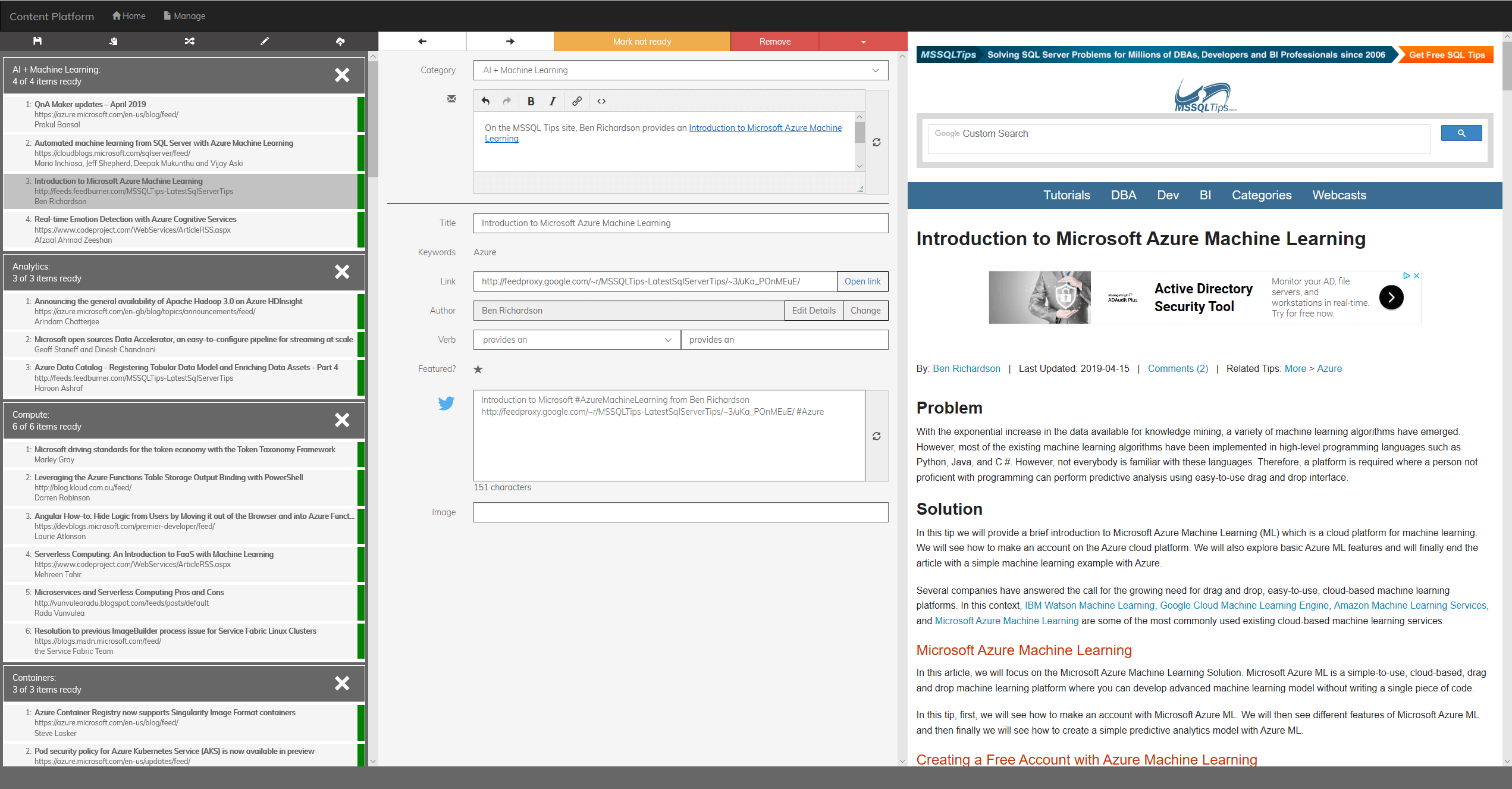
データ処理
幸い、endjin のチームは、コンテンツ プラットフォームの元のバージョンを構築したときに、いつか機械学習を使用してそれを改善したいと考えていました。そのため、ニュースレターの生成に使用されるすべてのデータを生の形式と処理済みの形式の両方で保持しました (合計サイズが約 3 GB の 4,000 を超える JSON ファイル)。 これらは、2 つのトレーニング データセットに変換されました。バイナリ分類用の 28 MB の .CSV ファイルと、マルチクラス分類用の 9 MB の .CSV ファイルです。
データ変換と機械学習アルゴリズム
分類するブログ記事のタイトルとコンテンツは自由記載であるため、テキストの機能化 データ変換で変換します。その後、連結 データ変換を使用して、タイトルとコンテンツを 1 つのフィールドに結合しました。
endjin が手動で作成したオリジナル モデルは、SdcaMaximumEntropy マルチクラス分類アルゴリズムを使用していました。しかし、endjin が AutoML で ML.NET CLI を使用したときに、シナリオ向けにより高いパフォーマンスを行うモデルを見つけました。
最初のシナリオでは ("これは Azure に関する記事ですか?") AutoML は、最適なパフォーマンスアルゴリズムとして AveragedPerceptronBinary を選択しました。2 番目のシナリオ ("この記事で取り上げる Azure の領域はどれですか?") では、AutoML は最もパフォーマンスの高いアルゴリズムとして LightGbmMulti を選択し、次のコードを生成して多クラス分類子をトレーニングしました。
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin は、ML.NET を使用して、Azure ニュースレター向け記事の選択と分類のプロセスを改善しました。また、ML.NET と AutoML を使用して機械学習モデルを生成することで、モデルのパラメーターを微調整するよりも、ビジネス価値を提供することにフォーカスすることができるようになりました。