
Tutorial de ML.NET: comience en 10 minutos
Introducción
Propósito
Use ML.NET Model Builder en Visual Studio para entrenar y usar su primer modelo de Machine Learning con ML.NET.
Instale la CLI de ML.NET y, a continuación, entrene y use su primer modelo de Machine Learning con ML.NET.
Requisitos previos
Ninguna.
macOS 12.0 o versiones posteriores.
Tiempo para completar
10 minutos + tiempo de descarga/instalación
Escenario
Una aplicación que puede predecir si el texto de las opiniones de los clientes es negativo o positivo.
Descargar e instalar
Descargar e instalar Visual Studio 2026.
Durante la instalación, se debe seleccionar la carga de trabajo Desarrollo de escritorio de .NET junto con el componente de ML.NET Model Builder opcional. El uso del vínculo anterior debe preseleccionar todos los requisitos previos correctamente, como se muestra en la siguiente imagen:

¿Ya tiene Visual Studio 2026?
Este tutorial está optimizado para la versión más reciente de Visual Studio. Si ya tiene Visual Studio 2026, asegúrese de que esté actualizado y de que tiene instalada la carga de trabajo necesaria:
-
Busque el Instalador Visual Studio en su equipo.
En el menú Inicio de Windows, busque "
installer" y, luego, seleccione Instalador Visual Studio en los resultados. - Si se le solicita, permita que el instalador se actualice a sí mismo.
- En caso de haber actualizaciones disponibles de Visual Studio 2026, se mostrará el botón Actualizar. Selecciónelo para actualizar antes de modificar la instalación. Se recomienda usar la versión más reciente de Visual Studio 2026 para este tutorial.
- Busque la instalación de Visual Studio 2026 y seleccione Modificar.
- Seleccione Desarrollo de escritorio .NET y asegúrese de que ML.NET Model Builder está seleccionado en el panel derecho. Seleccione el botón Modificar.
Actualizar a la versión más reciente de Model Builder
Una vez que haya habilitado ML.NET Model Builder en Visual Studio, descargue e instale la versión más reciente.
Descargar la versión más reciente de Model Builder
Después de descargarla, instale la extensión haciendo doble clic en el archivo .vsix.
Instalar el SDK de .NET
Para compilar aplicaciones .NET, es necesario descargar e instalar el SDK (kit de desarrollo de software) de .NET 8.
Descargar el SDK x64 de .NET 8 (Intel)
Descargar el SDK Arm64 de .NET 8 (Apple Silicon)
Si está en un equipo Mac con un chip M1 o M2 de Apple, debe instalar la versión Arm64 del SDK.
Instalación de la CLI de ML.NET
La interfaz de la línea de comandos (CLI) ML.NET proporciona herramientas para crear modelos de aprendizaje automático con ML.NET.
Nota: actualmente, la CLI de ML.NET está en versión preliminar y solo admite la versión anterior de LTS del SDK de .NET (.NET 8).
Para los pasos de instalación, se recomienda usar una consola de Bash. Dado que el valor predeterminado para macOS es una consola zsh, puede crear una instancia singular abriendo un nuevo terminal y ejecutando el siguiente comando.
bashPARA MÁQUINAS x64: Ejecute el siguiente comando:
dotnet tool install -g mlnet-linux-x64PARA ARQUITECTURAS CIRCUITO INTEGRADO ARM64 : Ejecute el siguiente comando en su lugar:
dotnet tool install -g mlnet-linux-arm64Si la herramienta se instala con éxito, debería ver el siguiente mensaje de salida donde [arch] es la arquitectura del chip:
You can invoke the tool using the following command: mlnet
Tool 'mlnet-linux-[arch]' (version 'X.X.X') was successfully installed.dotnet tool install -g mlnet-osx-x64PARA ARQUITECTURAS CIRCUITO INTEGRADO ARM64 : Ejecute el siguiente comando en su lugar:
dotnet tool install -g mlnet-osx-arm64Si la herramienta se instala con éxito, deberías ver un mensaje de salida donde [arch] es la arquitectura del chip similar al siguiente:
You can invoke the tool using the following command: mlnet
Tool 'mlnet-osx-[arch]' (version 'X.X.X') was successfully installed.
Nota: Si está usando una consola que no sea Bash (por ejemplo, zsh, que es la nueva predeterminada para macOS), entonces necesitará dar permisos de ejecuciónmlnet e incluir mlnet en la ruta del sistema. Las instrucciones sobre cómo hacer esto deberían aparecer en la terminal cuando instala mlnet (o cualquier herramienta global). En general, el siguiente comando debería trabajar en la mayoría de los sistemas: chmod +x [PATH-TO-MLNET-CLI-EXECUTABLE]
Si visualiza instrucciones similares a las siguientes, ejecútelas en su terminal.
cat << \EOF >> ~/.zprofile
#Add .NET Core SDK tools
export PATH="$PATH:~/.dotnet/tools"
EOFComo alternativa, puede intentar usar el siguiente comando para ejecutar la herramienta mlnet:
~/.dotnet/tools/mlnetSi el comando sigue dando un error, utilice el botón Me encontré con un problema que aparece a continuación para informar del problema y obtener ayuda para solucionarlo.
Crear la aplicación
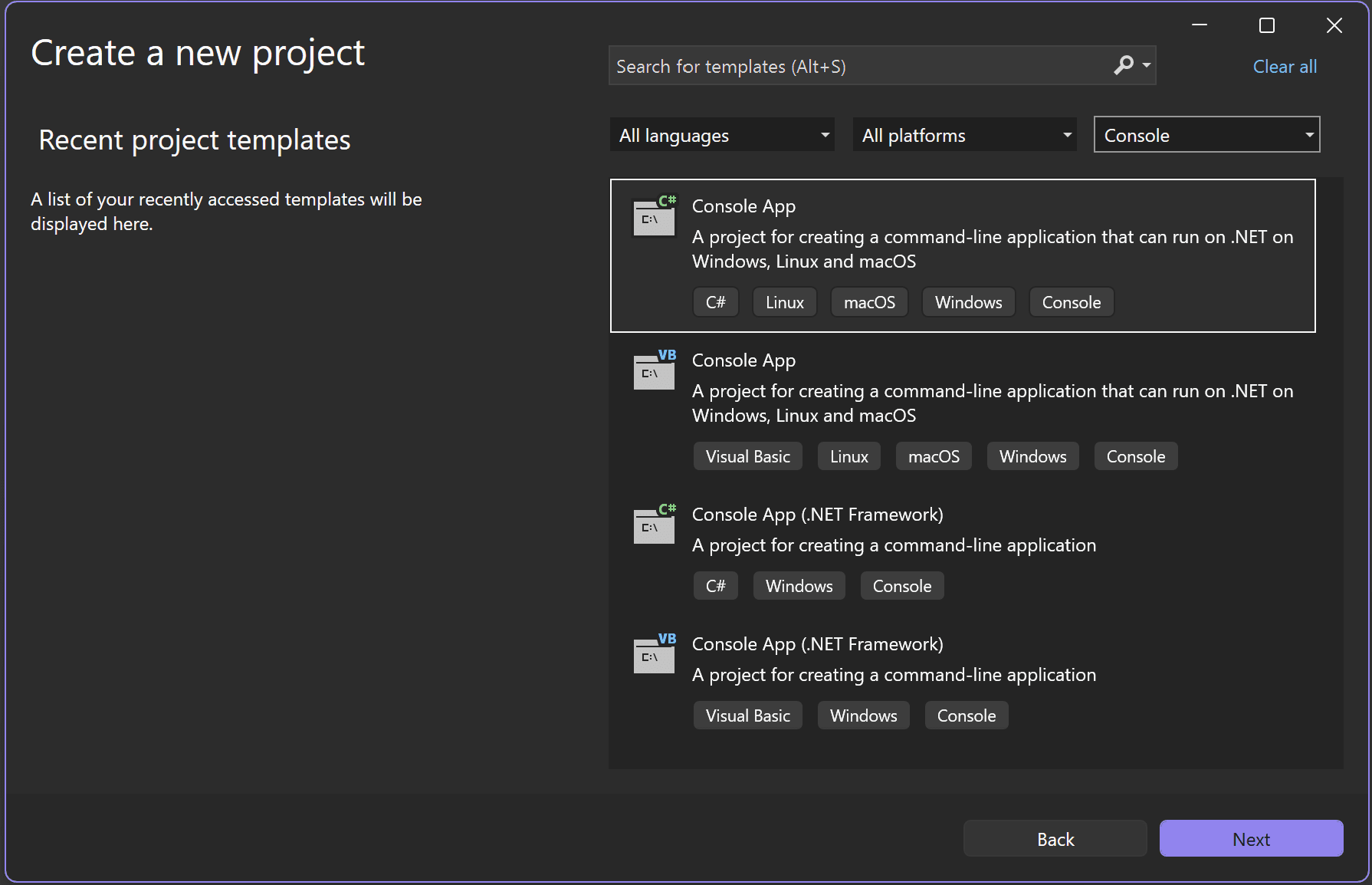
Abra Visual Studio y cree una nueva aplicación de consola .NET:
- Seleccione Crear un nuevo proyecto en la ventana de inicio de Visual Studio 2026.
-
Seleccione la plantilla de proyecto Aplicación de consola C#.
![Captura de pantalla de inicio de Visual Studio.]()
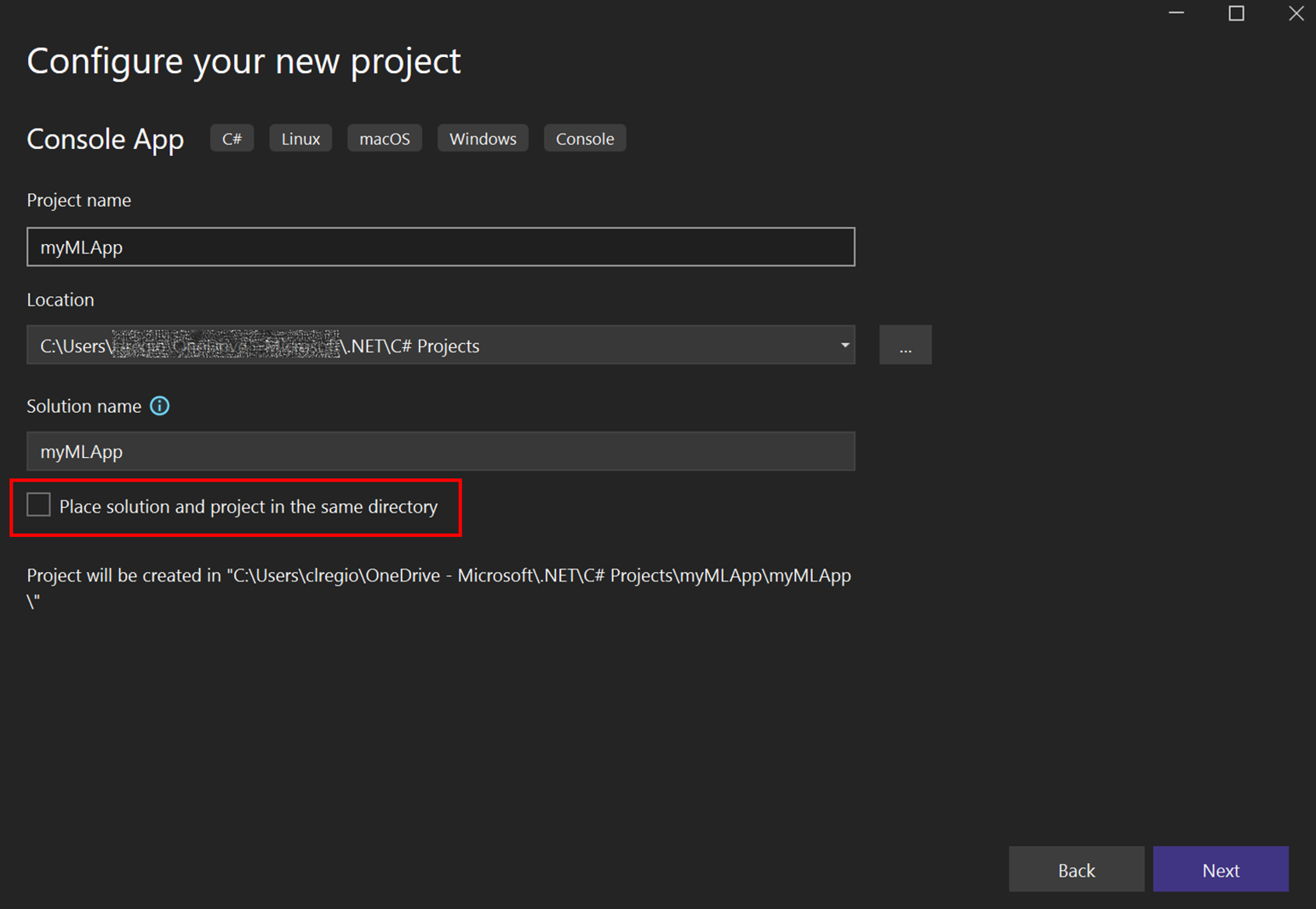
- Cambiar el nombre del proyecto a
myMLApp. -
Asegúrese de que Establecer solución y proyecto en el mismo directorio esté desactivado.
![Recorte de la pantalla de configuración del proyecto de Visual Studio.]()
- Seleccione el botón Siguiente.
- Seleccione .NET 10.0 (compatibilidad con términos estándar) como el marco.
- Seleccione el botón Create. Visual Studio crea el proyecto y carga el archivo
Program.cs.
Agregar aprendizaje automático
-
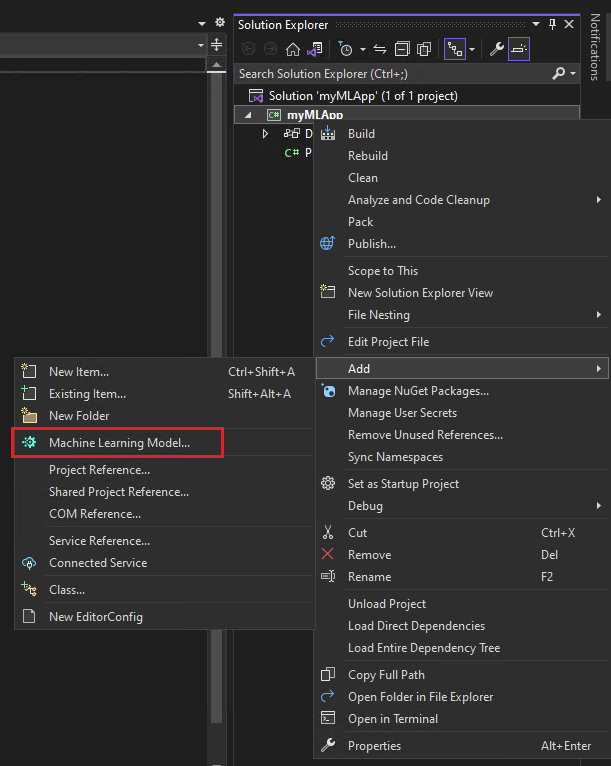
Haga clic con el botón derecho en el proyecto
myMLAppen el Explorador de soluciones y seleccione Agregar > Modelo de aprendizaje automático.![Captura de pantalla de Visual Studio que muestra el modelo de Machine Learning seleccionado.]()
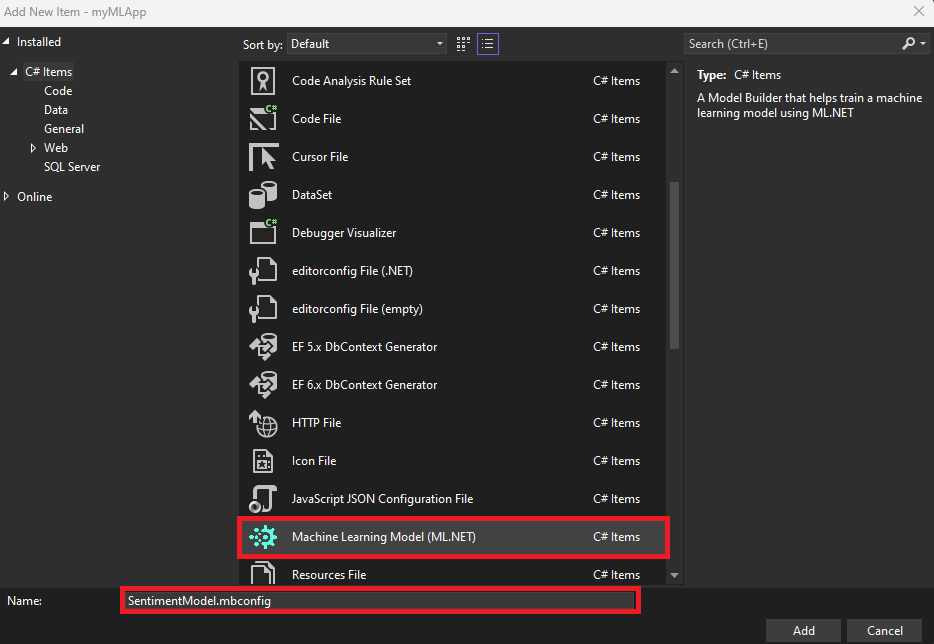
- En e cuadro del diálogo Agregar nuevo elemento, asegúrese de que Modelo de Machine Learning (ML.NET) está seleccionado.
-
Cambie el campo Nombre a
SentimentModel.mbconfigy seleccione el botón Agregar.![Cuadro de diálogo Agregar nuevo elemento que muestra el modelo de Machine Learning (ML.NET) seleccionado y SentimentModel.mbconfig como nombre de archivo.]()
Un nuevo archivo denominado SentimentModel.mbconfig se agrega a la solución y la interfaz de usuario de Model Builder se abre en una nueva ventana de herramienta acoplada en Visual Studio. mbconfig es simplemente un archivo JSON que realiza un seguimiento del estado de la interfaz de usuario.
Model Builder le guiará por el proceso de creación de un modelo de aprendizaje automático en los pasos siguientes.
En el terminal, ejecute los siguientes comandos:
mkdir myMLApp
cd myMLAppEl comando mkdir crea un nuevo directorio llamado myMLApp, y el comando cd myMLApp le permite un directorio de aplicaciones recién creado.
El código de entrenamiento del modelo se generará en los próximos pasos.
Seleccionar un escenario
Para generar el modelo, primero debe seleccionar el escenario de aprendizaje automático. Model Builder admite varios escenarios:
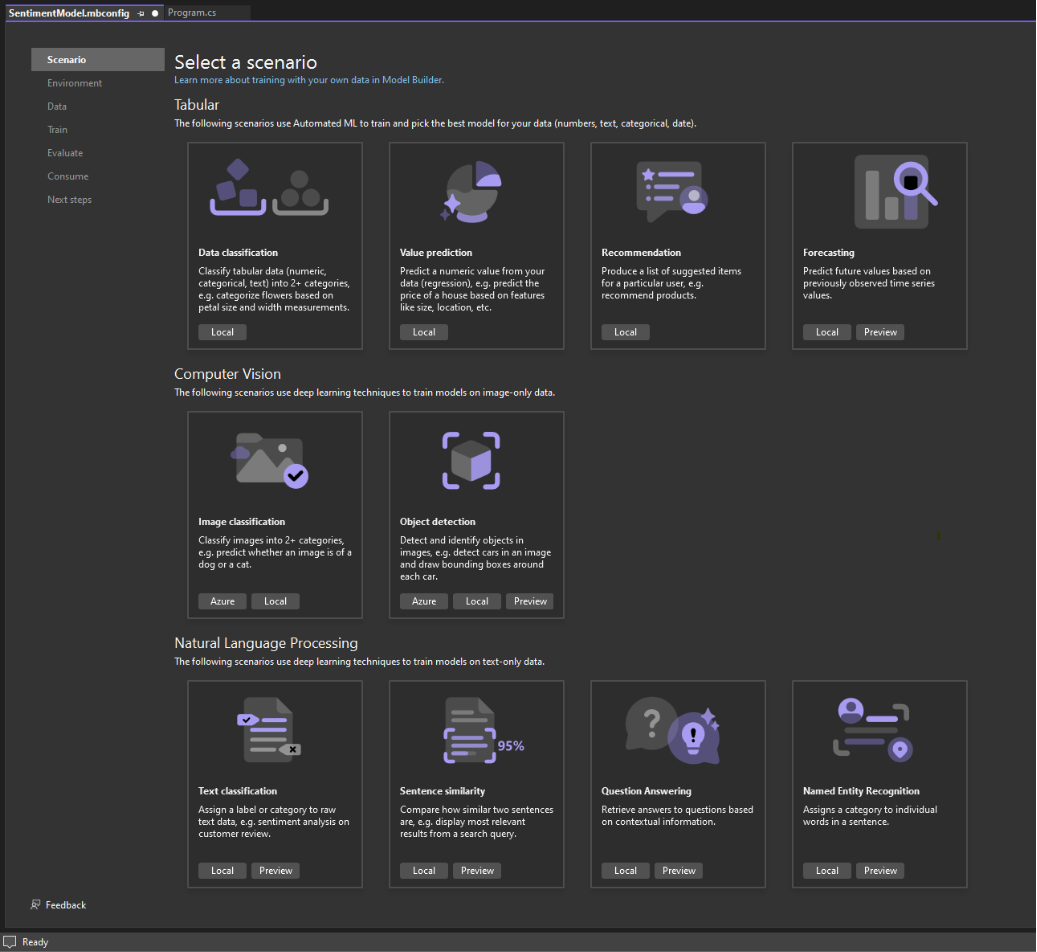
Nota: Si las capturas de pantalla del tutorial no coinciden con lo que ve, es posible que necesite actualizar su versión de Model Builder. Vaya a Extensiones > Administrar extensiones para asegurarse de que no hay actualizaciones disponibles para Model Builder. La versión usada en este tutorial es 17.18.2.
En este caso, predecirá su opinión en función del contenido (texto) de las opiniones de los clientes.
-
En la pantalla de Escenario del Model Builder, seleccione el escenario Clasificación de datos, ya que está prediciendo en qué categoría cae un comentario (positivo o negativo).
![Recorte de pantalla de la opción de clasificación de datos de Model Builder.]()
-
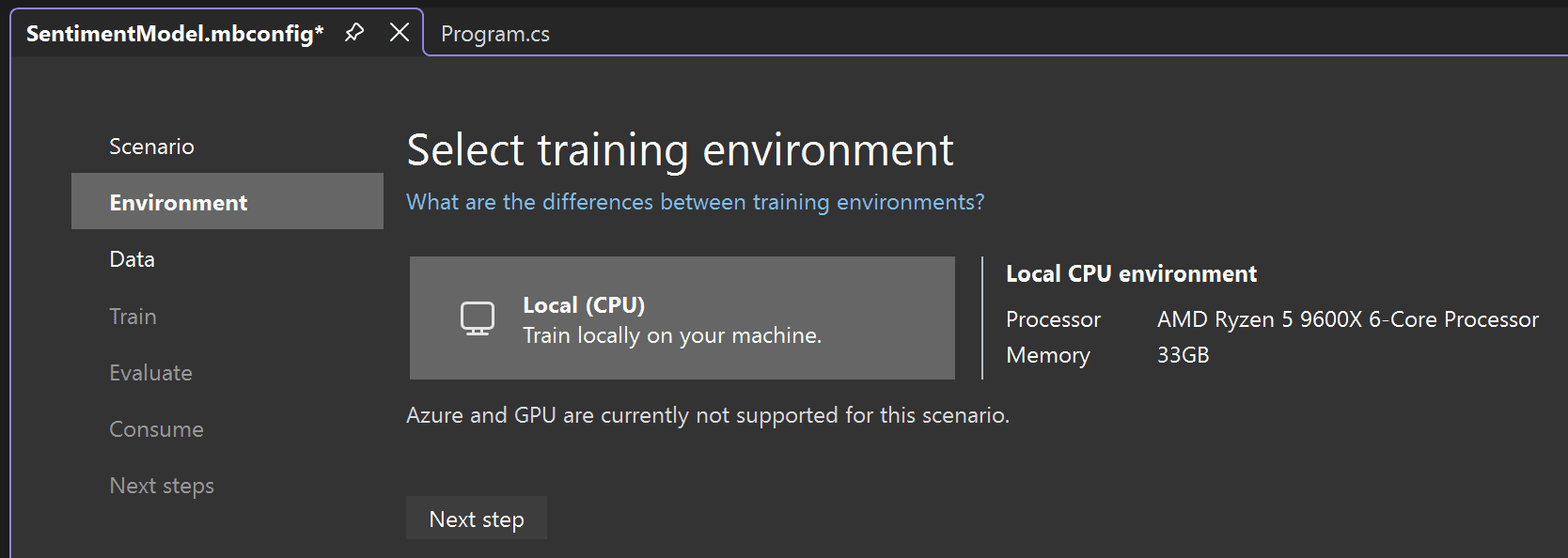
Después de seleccionar el escenario de Clasificación de datos, debe elegir su entorno de entrenamiento. Aunque algunos escenarios admiten la formación en Azure, actualmente la clasificación solo admite la formación local, así que mantenga seleccionado el entorno Local y siga al paso Datos.
![El entorno de formación local se selecciona en Model Builder.]()
Para generar el modelo, debe seleccionar el escenario de aprendizaje automático.
Hay varios escenarios de ML compatibles con la CLI de ML.NET:
- Clasificación: úsela para predecir a qué categoría pertenecen los datos (por ejemplo, analizar la opinión de las opiniones de los clientes como positivas o negativas).
- Clasificación de imágenes - Se usa cuando se quiere predecir a qué categoría pertenece una imagen (por ejemplo, predecir si una imagen es de un gato o de un perro).
- Regresión (por ejemplo, predicción de valores): úselo cuando quiera predecir un valor numérico (por ejemplo, predecir el precio de la vivienda).
- Previsión: utilícelo cuando quiera pronosticar valores futuros en una serie temporal (por ejemplo, prever las ventas trimestrales)
- Recomendación: use esta opción cuando quiera recomendar elementos a los usuarios en función de las clasificaciones históricas (por ejemplo, la recomendación de productos).
En este caso, predecirá la opinión en función del contenido (texto) de las opiniones de los clientes, por lo que usará clasificación.
Descargar y agregar datos
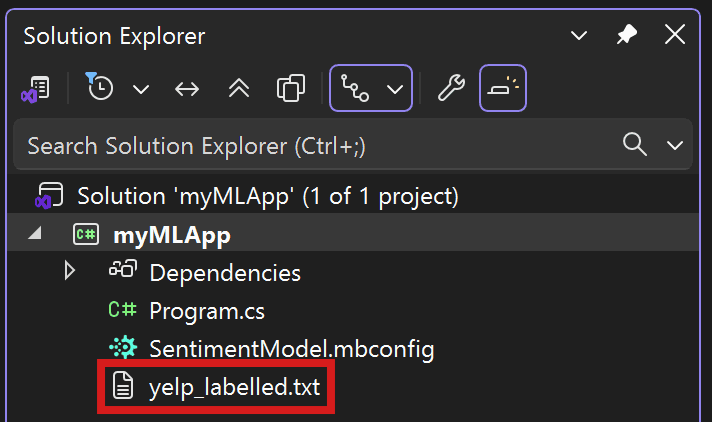
Descargue los conjuntos de datos Sentiment Labelled Sentences del repositorio UCI Machine Learning Repository. Descomprima sentiment labelled sentences.zip y guarde el archivo yelp_labelled.txt en el directorio myMLApp.
El Explorador de soluciones debe ser similar al siguiente:
Cada fila de yelp_labelled.txt representa una revisión diferente de un restaurante que deja un usuario en Yelp. La primera columna representa el comentario que deja el usuario y la segunda columna representa la sensación expresada por el texto (0 es negativo, 1 es positivo). Las columnas están separadas por tabulaciones y el conjunto de datos no tiene encabezado. Los datos tienen un aspecto similar al siguiente:
Wow... Loved this place. 1
Crust is not good. 0
Not tasty and the texture was just nasty. 0Agregar datos
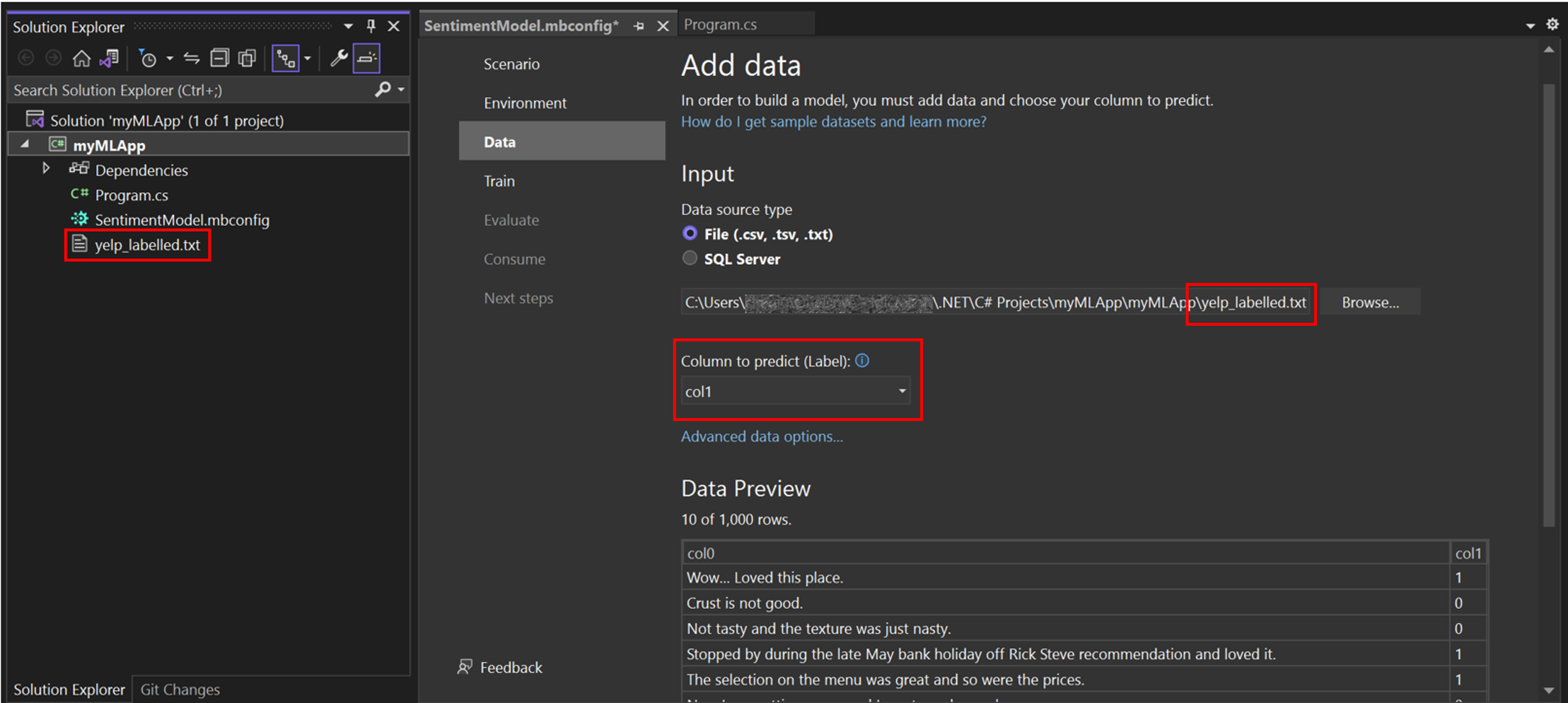
En Model Builder, puede agregar datos de un archivo local o conectarse a una base de datos SQL Server. En este caso, agregará yelp_labelled.txt desde un archivo.
Seleccione Archivo como tipo de origen de datos de entrada.
Busque
yelp_labelled.txt. Una vez que seleccione el conjunto de datos, aparecerá una vista previa de los datos en la sección Vista previa de datos. Dado que el conjunto de datos no tiene un encabezado, los encabezados se generan automáticamente ("col0" y "col1").En Columna para predecir (Etiqueta), seleccione "col1". La etiqueta es lo que está pronosticando, que en este caso es el sentimiento que se encuentra en la segunda columna ("col1") del conjunto de datos.
Las columnas que se usan para ayudar a predecir la etiqueta se denominan Características. Todas las columnas del conjunto de datos además de la etiqueta se seleccionan automáticamente como Características. En este caso, la columna de comentario de revisión ("col0") es la columna Característica. Puede actualizar las columnas de característica y modificar otras opciones de carga de datos en Opciones avanzadas de datos, pero no es necesario para este ejemplo.
Después de agregar sus datos, vaya al paso Entrenar.
Entrenar el modelo
Ahora, entrenará el modelo con el set de datos yelp_labelled.txt.
Model Builder evalúa muchos modelos con distintos algoritmos y configuraciones en función de la cantidad de tiempo de entrenamiento proporcionado para compilar el modelo de mejor rendimiento.
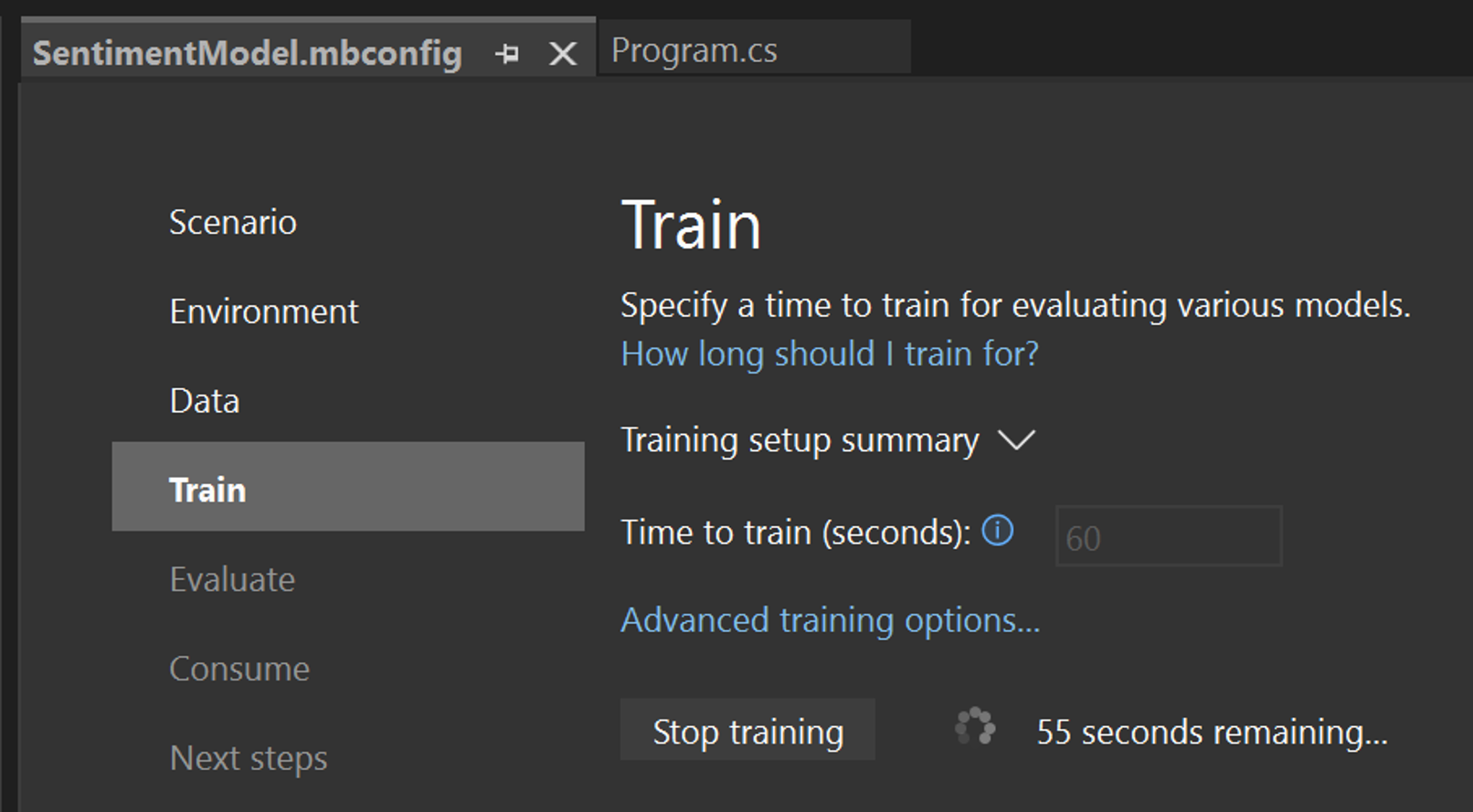
Cambiar el Tiempo de entrenamiento, que es la cantidad de tiempo que le gustaría que Model Builder explore varios modelos, a 60 segundos (puede intentar aumentar este número si no se encuentra ningún modelo después del entrenamiento). Tenga en cuenta que, para conjuntos de datos más grandes, el tiempo de entrenamiento será más largo. Model Builder ajusta automáticamente el tiempo de entrenamiento en función del tamaño del conjunto de datos.
Puede actualizar la métrica de optimización y los algoritmos usados en Opciones avanzadas de entrenamiento , pero no es necesario para este ejemplo.
-
Seleccione Iniciar el entrenamiento para iniciar el proceso de entrenamiento. Una vez iniciado el entrenamiento, puede ver el tiempo restante.
![Entrenamiento de Model Builder]()
Resultados del entrenamiento
Una vez finalizado el entrenamiento, puede ver un resumen de los resultados del entrenamiento.
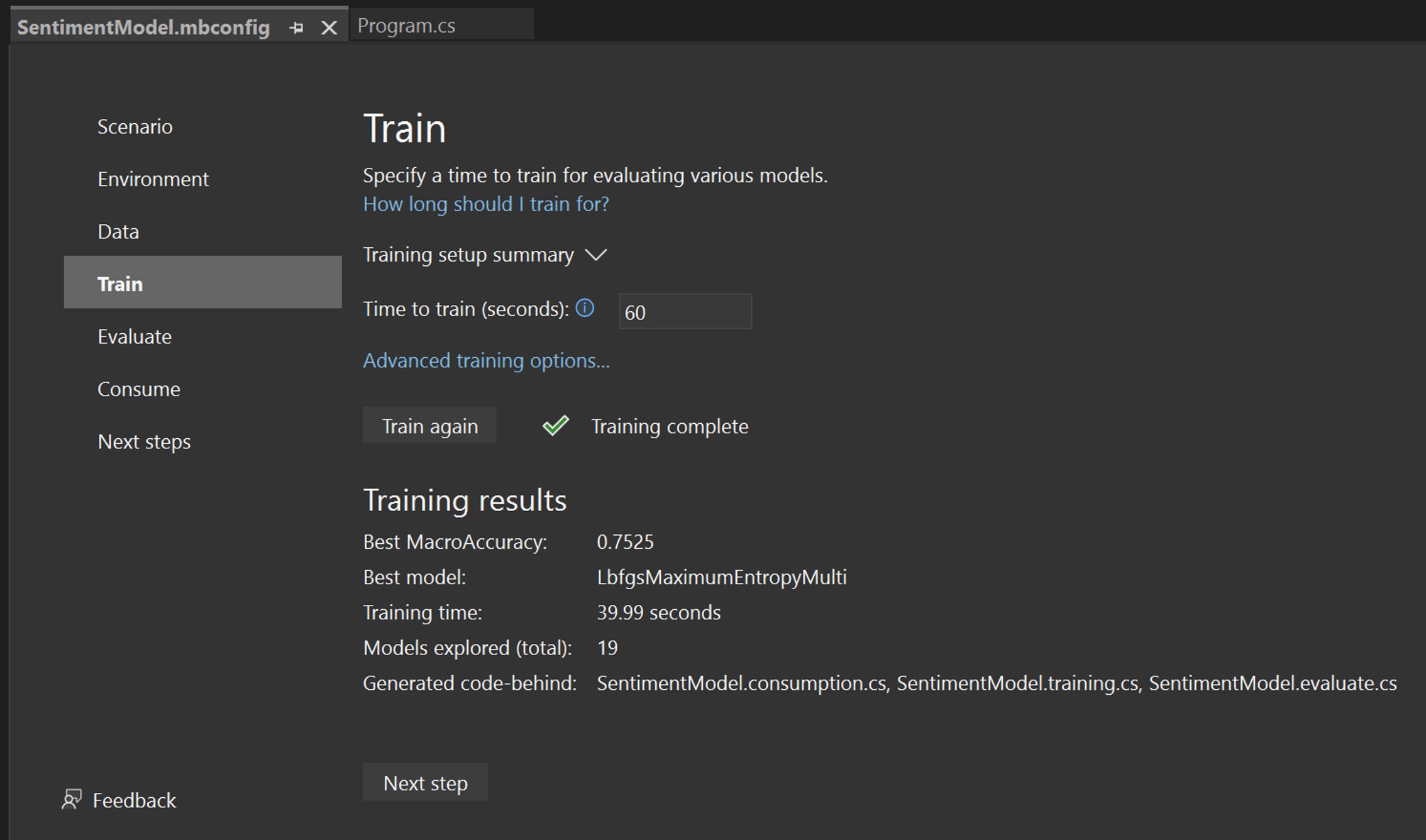
- Best MacroAccuracy : muestra la precisión del mejor modelo que Model Builder encuentra. Una mayor precisión significa que el modelo predijo más correctamente en los datos de prueba.
- Mejor modelo - Esto muestra qué algoritmo realizó mejor durante la exploración de Model Builder.
- Tiempo de entrenamiento: esto muestra la cantidad total de tiempo dedicado a entrenar o explorar modelos.
- Modelos explorados (total) : muestra el número total de modelos explorados por Model Builder en el período de tiempo especificado.
- Código subyacente generado : se programan los nombres de los archivos generados para ayudar a consumir el modelo o entrenar un nuevo modelo.
Si lo desea, puede ver más información sobre la sesión de entrenamiento en la ventana Machine Learning Salida.
Una vez finalizado el entrenamiento del modelo, vaya al paso Evaluar.
En el terminal, ejecute el siguiente comando (en la carpeta myMLApp):
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --name SentimentModel --train-time 60¿Qué significan estos comandos?
El comando mlnet classification se ejecuta ML.NET con AutoML para explorar muchas iteraciones de modelos de clasificación en la cantidad determinada de tiempo de entrenamiento con distintas combinaciones de transformaciones de datos, algoritmos y opciones de algoritmo y, a continuación, elige el modelo de mayor rendimiento.
- --dataset: Ha elegido
yelp_labelled.txtcomo conjunto de datos (internamente, la CLI dividirá el conjunto de datos en conjuntos de datos de entrenamiento y de prueba). - --label-col: Debe especificar la columna objetivo que desea predecir (o la etiqueta). En este caso, quiere predecir el sentimiento de la segunda columna (las columnas con índice cero significan que es la columna "1").
- --has-header: Utilice esta opción para especificar si el conjunto de datos tiene un encabezado. En este caso, el conjunto de datos no tiene encabezado por lo que es falso.
- --name: Utilice esta opción para proporcionar un nombre para su modelo de aprendizaje automático y los activos relacionados. En este caso, todos los activos asociados a este modelo de aprendizaje automático tendrán SentimentModel en el nombre.
- --train-time: También debe especificar la cantidad de tiempo que desea que la CLI de ML.NET explore diferentes modelos. En este caso, 60 segundos (puede intentar aumentar este número si no se encuentran modelos después del entrenamiento). Tenga en cuenta que para conjuntos de datos más grandes, debe establecer un tiempo de entrenamiento más largo.
Progreso
Mientras la CLI de ML.NET está explorando diferentes modelos, muestra los siguientes datos:
- Iniciar el entrenamiento: en esta sección se muestra cada iteración del modelo, incluido el instructor (algoritmo) usado y las métricas de evaluación para esa iteración.
- Tiempo restante este y la barra de progreso indicará cuánto tiempo queda en el proceso de entrenamiento en segundos.
- Mejor algoritmo: muestra qué algoritmo ha funcionado mejor hasta ahora.
- Mejor puntuación: esto muestra el rendimiento del mejor modelo hasta ahora. Una mayor precisión significa que el modelo ha predicho con mayor exactitud en los datos de prueba.
Si lo desea, puede ver más información sobre la sesión de entrenamiento en el archivo de registro generado por la CLI.
Evaluar su modelo
El paso Evaluar muestra el algoritmo de mejor rendimiento y la mejor precisión, y le permite probar el modelo en la interfaz de usuario.
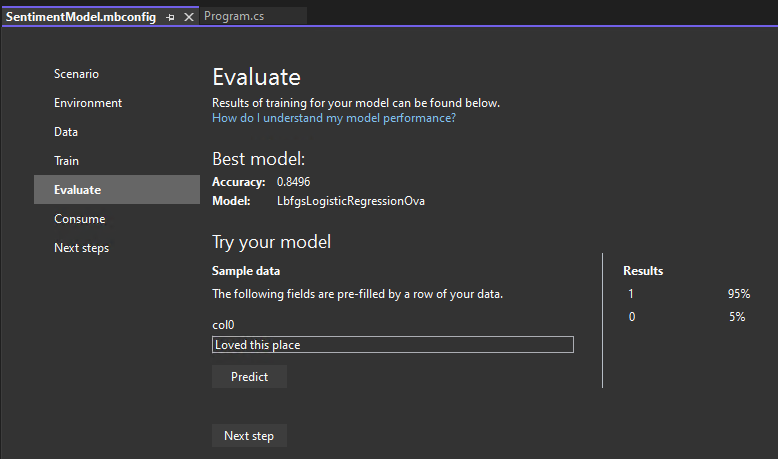
Probar el modelo
Puede realizar predicciones en la entrada de ejemplo en la sección Probar el modelo. El cuadro de texto se rellena previamente con la primera línea de datos del conjunto de datos, pero puede cambiar la entrada y seleccionar Predecir para probar diferentes predicciones de opiniones.
En este caso, 0 significa opinión negativa y 1 significa opinión positiva.
Nota: Si el modelo no está funcionando bien (por ejemplo, si la Precisión es baja o si el modelo solo predice valores "1"), puede intentar agregar más tiempo y entrenar de nuevo. Esta es una muestra que utiliza un conjunto de datos muy pequeño; para los modelos a nivel de producción, querrá agregar muchos más datos y tiempo de entrenamiento.
Después de evaluar y probar el modelo, pase al paso Consumir.
Después de que la CLI de ML.NET seleccione el mejor modelo, mostrará el Resumen de entrenamiento, que le muestra un resumen del proceso de exploración, incluido cuántos modelos se exploraron en el tiempo de entrenamiento dado.
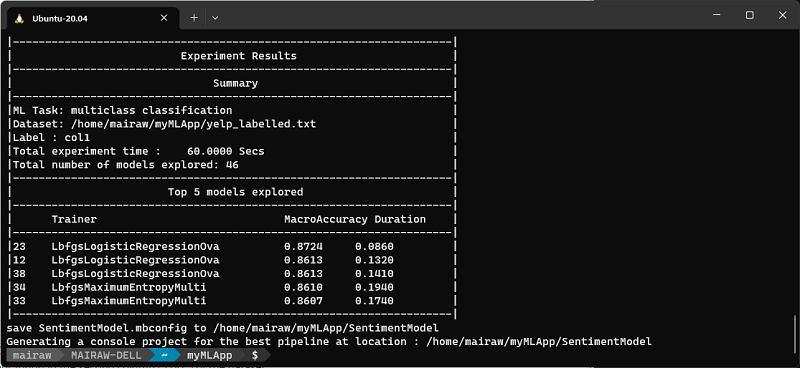
Modelos principales
Si bien la CLI de ML.NET genera código para el modelo de mayor rendimiento, también muestra los mejores modelos (hasta 5) con la mayor precisión que encontró en el tiempo de exploración determinado. Muestra varias métricas de evaluación para esos modelos superiores, incluidos AUC, AUPRC y F1-score. Para obtener más información, consulte Métricas de ML.NET.
Generar código
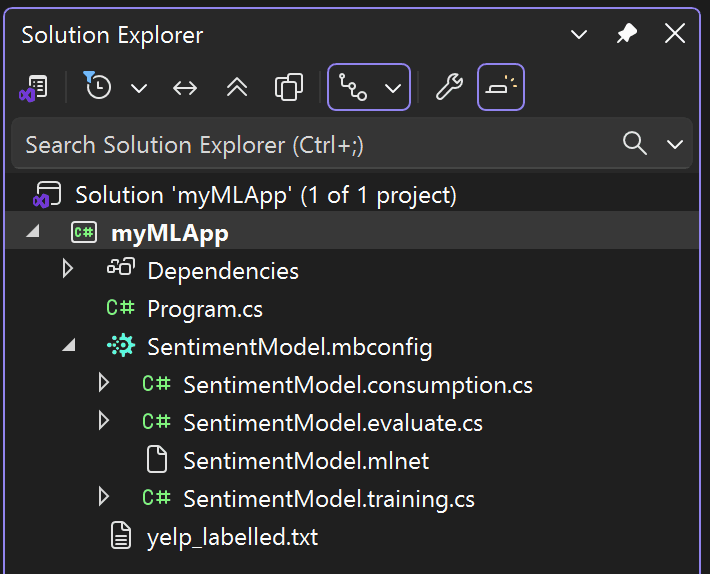
Una vez completado el entrenamiento, se agregan automáticamente cuatro archivos como código subyacente a SentimentModel.mbconfig:
SentimentModel.consumption.cs: este archivo contiene las clases de entrada y salida del modelo y un métodoPredictque se puede usar para el uso del modelo.SentimentModel.evaluate.cs: este archivo contiene un métodoCalculatePFIque usa la técnica de importancia de características de permutación (PFI) para evaluar qué características contribuyen más a las predicciones del modelo.SentimentModel.mlnet: Este archivo es el modelo de ML.NET entrenado, que es un archivo ZIP serializado.SentimentModel.training.cs: Este archivo contiene el código para reconocer la importancia que tienen las columnas de entrada en las predicciones del modelo.
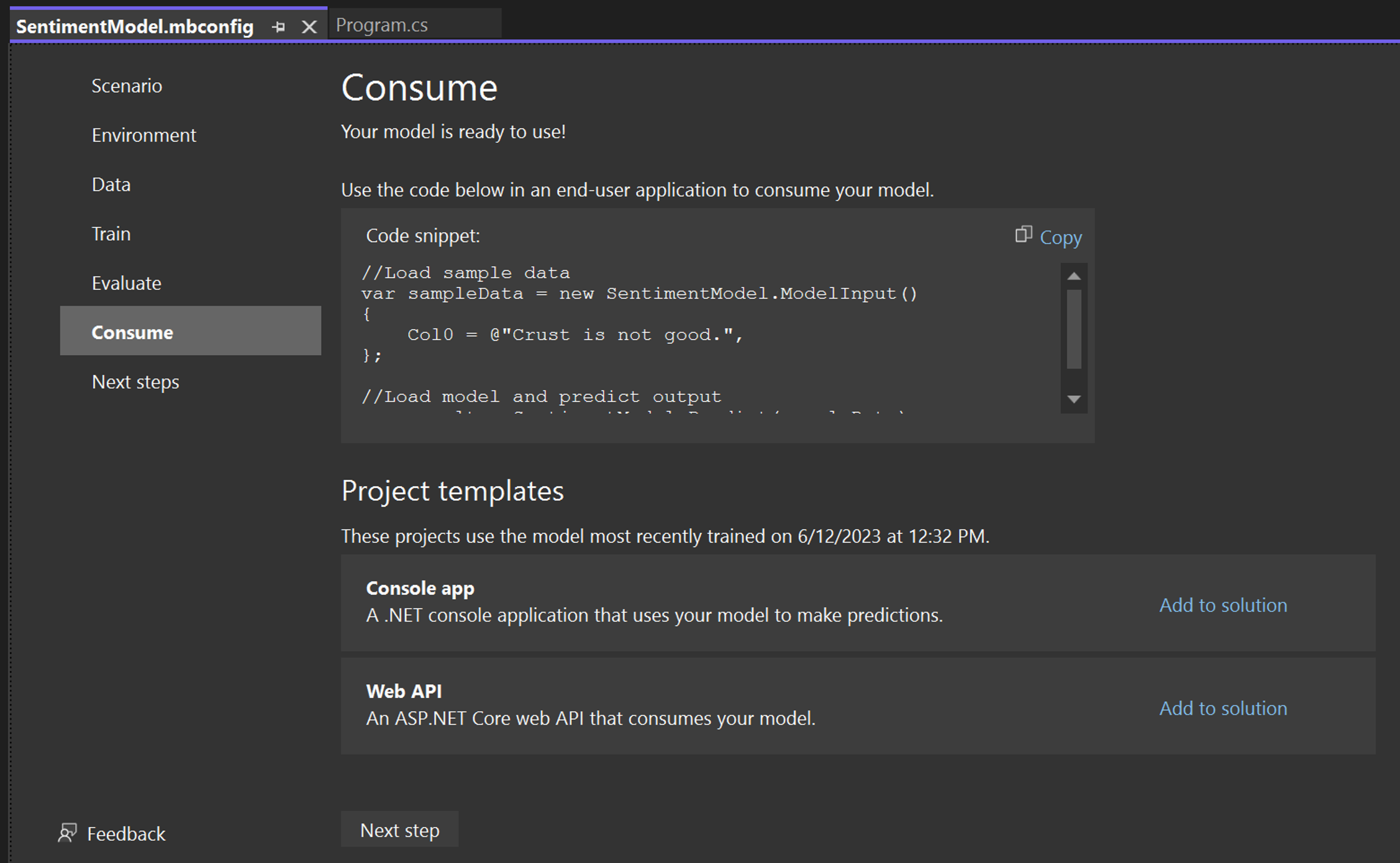
En el paso Consumir de Model Builder, se proporciona un fragmento de código que crea una entrada de ejemplo para el modelo y usa el modelo para realizar una predicción en esa entrada.
Model Builder también ofrece Plantillas de proyecto que puede agregar opcionalmente a su solución. Hay dos plantillas de proyecto (una aplicación de consola y una API web), ambas consumen el modelo entrenado.
La CLI de ML.NET agrega tanto el modelo de aprendizaje automático como el código para entrenar y consumir el modelo, que incluye lo siguiente:
-
Se crea un nuevo directorio llamado SentimentModel que contiene una aplicación de consola .NET que incluye los siguientes archivos:
Program.cs: este archivo contiene código para ejecutar el modelo.SentimentModel.consumption.cs: este archivo contiene las clases de entrada y salida del modelo y un métodoPredictque se puede usar para el uso del modelo.SentimentModel.mbconfig: este archivo es un archivo JSON que mantiene un registro de las configuraciones y resultados de su entrenamiento.SentimentModel.training.cs: este archivo contiene la canalización de entrenamiento (transformaciones de datos, algoritmos y parámetros de algoritmo) usada para entrenar el modelo final.SentimentModel.zip: este archivo es el modelo de ML.NET entrenado, que es un archivo ZIP serializado.
Para probar el modelo, puede ejecutar la aplicación de consola para predecir la opinión de una sola declaración con el modelo.
Consumir el modelo
El último paso es consumir el modelo entrenado en la aplicación del usuario final.
-
Reemplace el código
Program.csen su proyectomyMLAppcon el código siguiente:Program.csusing MyMLApp; // Add input data var sampleData = new SentimentModel.ModelInput() { Col0 = "This restaurant was wonderful." }; // Load model and predict output of sample data var result = SentimentModel.Predict(sampleData); // If Prediction is 1, sentiment is "Positive"; otherwise, sentiment is "Negative" var sentiment = result.PredictedLabel == 1 ? "Positive" : "Negative"; Console.WriteLine($"Text: {sampleData.Col0}\nSentiment: {sentiment}"); -
Ejecutar
myMLApp(seleccionar Ctrl+F5 o Depurar > Iniciar sin depurar). Debería ver la siguiente salida, prediciendo si la declaración de entrada es positiva o negativa.![La salida: Texto: Este restaurante fue fantástico. Opinión: positiva]()

La CLI de ML.NET ha generado el modelo entrenado y el código para usted, por lo que ahora puede utilizar el modelo en aplicaciones .NET (por ejemplo, su aplicación de consola SentimentModel) siguiendo estos pasos:
- En la línea de comandos, vaya al directorio
consumeModelApp.Command promptcd SentimentModel -
Abra el
Program.csen cualquier editor de código e inspeccione el código. El código debe ser similar al siguiente:Program.csusing System; namespace SentimentModel.ConsoleApp { class Program { static void Main(string[] args) { // Add input data SentimentModel.ModelInput sampleData = new SentimentModel.ModelInput() { Col0 = @"Wow... Loved this place." }; // Make a single prediction on the sample data and print results var predictionResult = SentimentModel.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: @{"Wow... Loved this place."}"); Console.WriteLine($"Col1: {1F}"); Console.WriteLine($"\n\nPredicted Col1: {predictionResult.PredictedLabel}\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); } } } -
Ejecute el
SentimentModel.ConsoleApp. Puede hacerlo ejecutando el siguiente comando en la terminal (asegúrese de estar en el directorioSentimentModel):Command promptdotnet runLa salida debe tener un aspecto similar al siguiente:
Command promptUsing model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data... Col0: Wow... Loved this place. Col1: 1 Class Score ----- ----- 1 0.9651076 0 0.034892436 =============== End of process, hit any key to finish ===============
Pasos siguientes
Enhorabuena, ha creado su primer modelo de aprendizaje automático con ML.NET Model Builder.
Ahora que ya tiene los fundamentos, continúe con este módulo de aprendizaje autoguiado en Microsoft Learn, donde utilizará los datos de los sensores para detectar si un dispositivo de fabricación está roto.
Microsoft Learn: entrenar un modelo de mantenimiento predictivo
ML.NET para principiantes
Deje que Luis le presente los conceptos de aprendizaje automático e IA, le explique lo que puede hacer con ellos y le guíe sobre cómo comenzar a usar OpenAI, Servicios de Azure AI y ML.NET:
Es posible que también le interese...



Enhorabuena, ha creado su primer modelo de aprendizaje automático con la CLI de ML.NET.
Ahora que ha usado la CLI de ML.NET para la clasificación (en concreto, el análisis de sentimiento), puede probar otros escenarios. Pruebe un escenario de regresión (específicamente la predicción de precios) mediante el conjunto de datos Taxi Fare para seguir creando modelos de ML.NET con la CLI de ML.NET.
Descarga del conjunto de datos de Taxi Fare
ML.NET para principiantes
Deje que Luis le presente el concepto de aprendizaje automático e IA, le explique lo que puede hacer con ellos y le guíe sobre cómo comenzar a usar OpenAI, Servicios de Azure AI y ML.NET:
Es posible que también le interese...