
ML.NET 教學課程 - 10 分鐘入門
入門
目的
在 Visual Studio 中使用 ML.NET Model Builder,透過 ML.NET 訓練及使用您的第一個機器學習模型。
安裝 ML.NET CLI,然後使用 ML.NET 定型並使用您的第一個機器學習模型。
必要條件
無。
macOS 12.0 或更新版本。
完成時間
10分鐘 + 下載/安裝時間
情節
可預測客戶評論的文字是負面或正面情緒的應用程式。
下載並安裝
下載並安裝 Visual Studio 2026。
在安裝期間,.NET 桌面開發工作負載應該與選擇性的 ML.NET Model Builder 元件一起選取。使用上述連結應正確預先選擇所有必要條件,如下圖所示:

已經有 Visual Studio 2026?
本教學課程已針對最新版本的 Visual Studio 進行最佳化。如果您已經有 Visual Studio 2026,請確認它是最新的,並已安裝必要的工作負載:
-
在您的電腦上尋找 Visual Studio 安裝程式。
在 Windows 的 [開始] 功能表中,搜尋「
installer」,然後從結果中選取 [Visual Studio 安裝程式]。 - 如有提示,請允許安裝程式自行更新。
- 如果有 Visual Studio 2026 的更新,則會顯示 [更新] 按鈕。選取它以在修改安裝之前更新。建議您在此教學課程中,使用最新的 Visual Studio 2026 版本。
- 尋找您的 Visual Studio 2026 安裝,然後選取 [修改]。
- 選取 .NET 桌面開發,並確定已在右窗格選取 ML.NET Model Builder。選取 [修改] 按鈕。
升級至最新版本的 Model Builder
在 Visual Studio 中啟用 ML.NET Model Builder 後,請下載並安裝最新版本。
下載之後,請按兩下 .vsix 檔案來安裝延伸模組。
安裝 .NET SDK
若要建置 .NET 應用程式,您必須下載並安裝 .NET 8 SDK (軟體開發套件)。
下載 .NET 8 SDK x64 (Intel)
下載 .NET 8 SDK Arm64 (Apple Silicon)
如果您使用的 Mac 上有 Apple M1 或 M2 晶片,則必須安裝 Arm64 版本的 SDK。
安裝 ML.NET CLI
ML.NET 命令列介面 (CLI) ,提供使用 ML.NET 建置機器學習模型的工具。
注意: 目前,ML.NET CLI 處於預覽狀態,且只支援 .NET SDK (.NET 8) 的先前 LTS 版本。
如需安裝步驟,建議您使用 Bash 主控台。由於 macOS 的預設值是 zsh 主控台,因此您可以透過開啟新的終端並執行下列命令來建立單一執行個體。
bashx64 電腦 - 請執行下列命令:
dotnet tool install -g mlnet-linux-x64ARM64 積體電路架構 - 請改為執行下列命令:
dotnet tool install -g mlnet-linux-arm64如果工具安裝成功,您應該會看到下列輸出訊息,其中 [arch] 是積體電路架構:
You can invoke the tool using the following command: mlnet
Tool 'mlnet-linux-[arch]' (version 'X.X.X') was successfully installed.dotnet tool install -g mlnet-osx-x64ARM64 積體電路架構 - 請改為執行下列命令:
dotnet tool install -g mlnet-osx-arm64如果工具安裝成功,您應該會看到輸出訊息,其中 [arch] 是類似下列的積體電路架構:
You can invoke the tool using the following command: mlnet
Tool 'mlnet-osx-[arch]' (version 'X.X.X') was successfully installed.
注意: 如果您使用的主控台不是 Bash (例如 zsh,這是 macOS 新的預設值),則您必須將可執行檔權限授與 mlnet,並將 mlnet 包含在系統路徑中。當您安裝 mlnet (或任何全域工具) 時,終端中應會顯示如何執行此動作的指示。一般而言,下列命令應該適用於大多數系統: chmod +x [PATH-TO-MLNET-CLI-EXECUTABLE]
如果您看到如下所示的指示,請在終端中執行這些指示。
cat << \EOF >> ~/.zprofile
#Add .NET Core SDK tools
export PATH="$PATH:~/.dotnet/tools"
EOF或者,您可以嘗試使用下列命令執行 ML.NET 工具:
~/.dotnet/tools/mlnet如果該命令仍顯示錯誤,請使用下方的 [我遇到了問題] 按鈕來回報問題並取得解決問題的說明。
建立您自己的應用程式
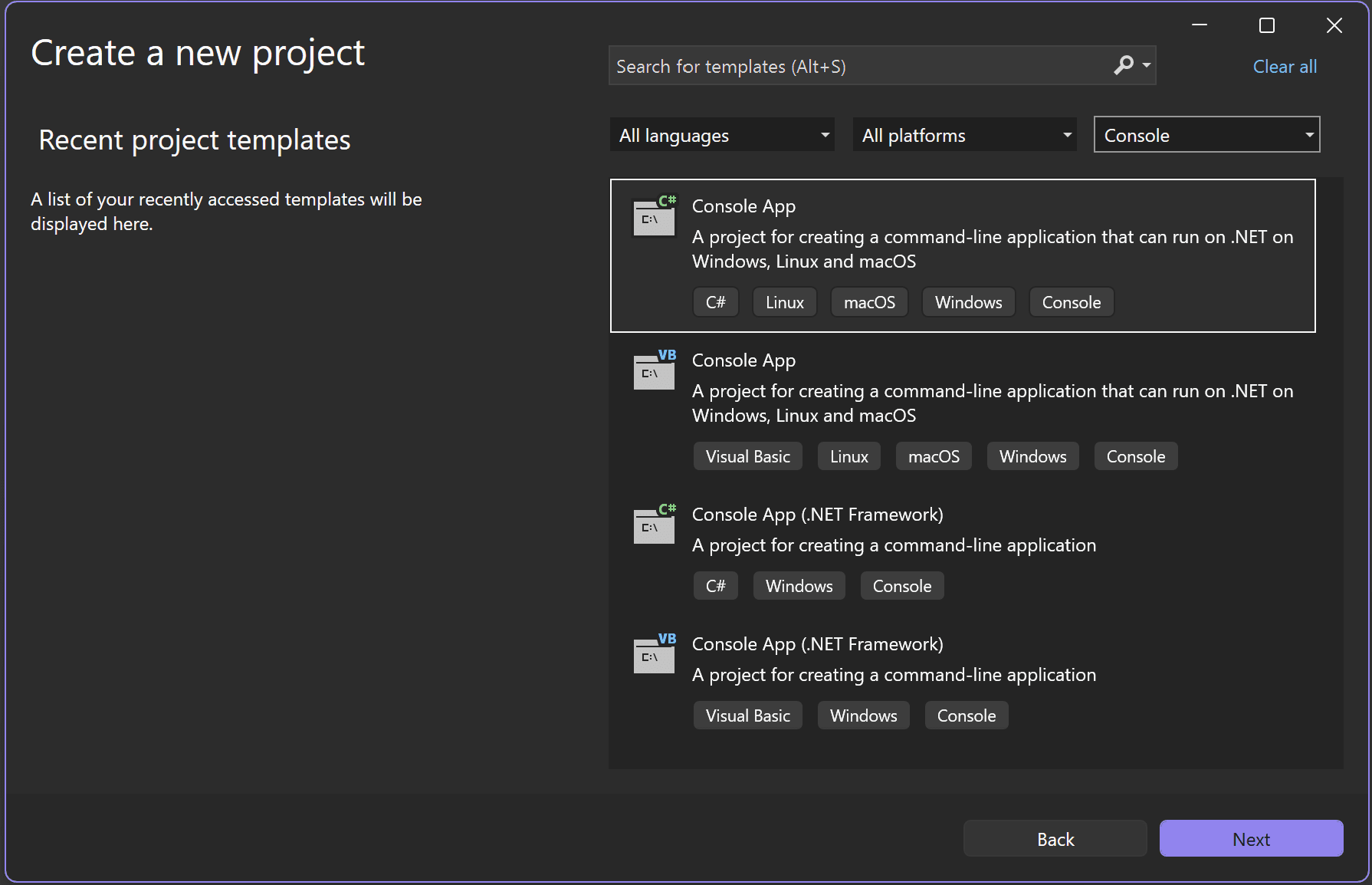
開啟 Visual Studio 並建立新的 .NET 主控台應用程式:
- 從 Visual Studio 2026 開始視窗選取 [建立新專案]。
-
選取 [C# 主機應用程式] 專案範本。
![Visual Studio 開始畫面的螢幕擷取畫面。]()
- 選取 [下一步] 按鈕。
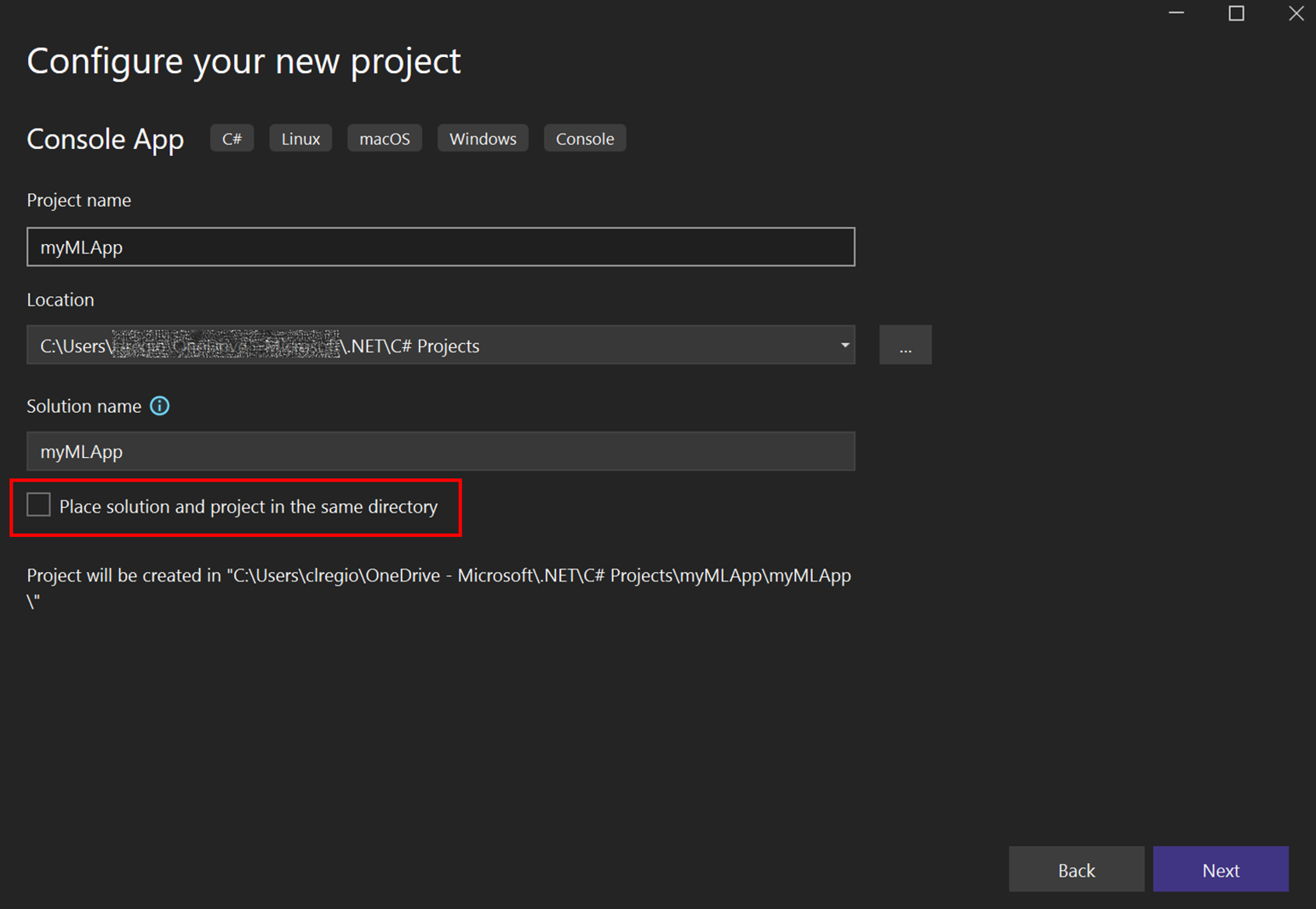
- 將專案名稱變更為
myMLApp。 -
請確定 [將解決方案和專案放置在相同目錄中] 已取消選取。
![Visual Studio 專案設定畫面的螢幕擷取畫面。]()
- 選取 [下一步] 按鈕。
- 選取 .NET 10.0 (長期支援) 做為 Framework。
- 選取 [建立] 按鈕。Visual Studio 會建立您的專案,並載入
Program.cs檔案。
新增機器學習
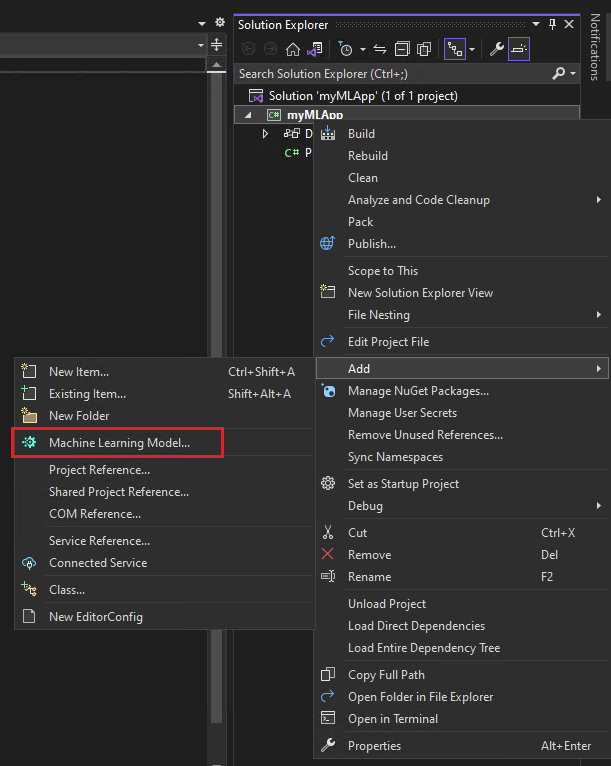
- 按一下 [方案總管] 索引標籤。您可以使用 [檢視] > [方案總管] 功能表,或選取 Ctrl + Alt + L來開啟它。
-
在 方案總管 中的
myMLApp專案上按一下滑鼠右鍵,然後選取 [新增] > [機器學習模型]。![顯示已選取機器學習模型的 Visual Studio 螢幕擷取畫面。]()
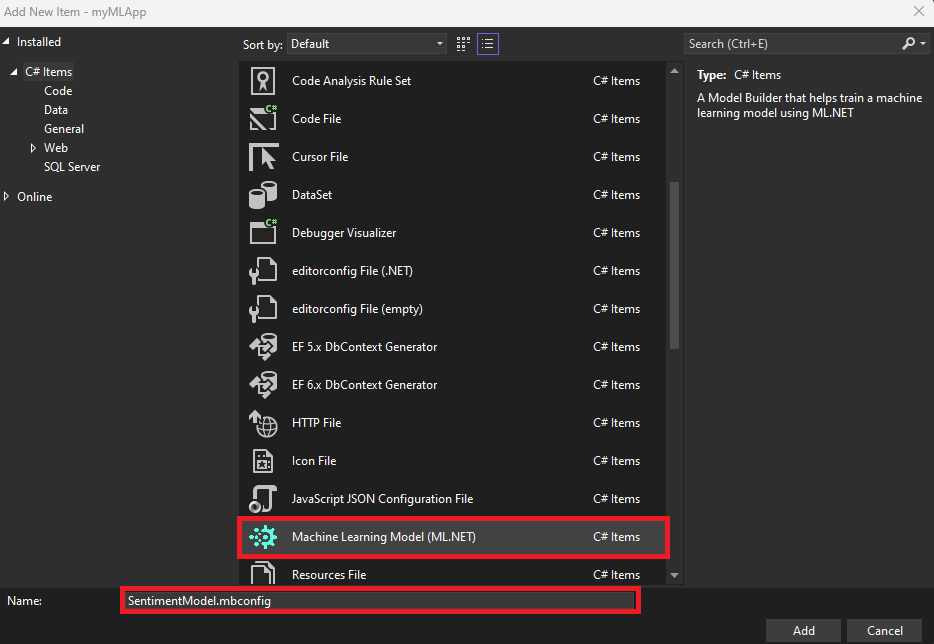
- 在 [新增項目] 對話方塊中,確定已選取[Machine Learning Model (ML.NET)]。
-
將 [名稱] 欄位變更為
SentimentModel.mbconfig,並選取 [新增] 按鈕。![新增項目對話方塊,顯示已選取機器學習模型 (ML.NET) 和以 SentimentModel.mbconfig 做為檔案名。]()
名為 SentimentModel.mbconfig 的新檔案已新增至您的解決方案,且 Model Builder UI 會在 Visual Studio 中的新停駐工具視窗中開啟。mbconfig 檔案只是一個可追蹤 UI 狀態的 JSON 檔案。
Model Builder 會在下列步驟中引導您完成建立機器學習模型的流程。
在終端中,執行下列命令:
mkdir myMLApp
cd myMLAppmkdir 命令會建立名為 myMLApp 的新目錄,而 cd myMLApp 命令會將您放入新建的應用程式目錄。
您的模型定型程式碼將會在近期步驟中產生。
挑選案例
若要產生您的模型,您需要先選取機器學習案例。Model Builder 可支援數種案例:
![在 [選取案例] 索引標籤的螢幕擷取畫面 Visual Studio 顯示 Model Builder 中支援的不同案例。](https://dotnet.microsoft.com/blob-assets/images/tutorials/machine-learning/model-builder-scenario.png)
注意: 如果教學課程的螢幕擷取畫面與所看到的畫面不相符,您可能需要更新 Model Builder 的版本。前往 [延伸模組] > [管理延伸模組],以確保 Model Builder 沒有可用的更新。本教學課程中使用的版本為 17.19.2。
在此情況下,您會依據客戶評論的內容 (文字) 預測情緒。
-
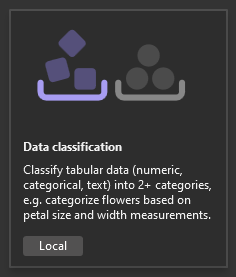
在 Model Builder 情節畫面中,選取 [資料分類] 情節,因為您正在預測註解屬於哪個類別 (正或負)。
![Model Builder 資料分類選項的螢幕擷取畫面。]()
-
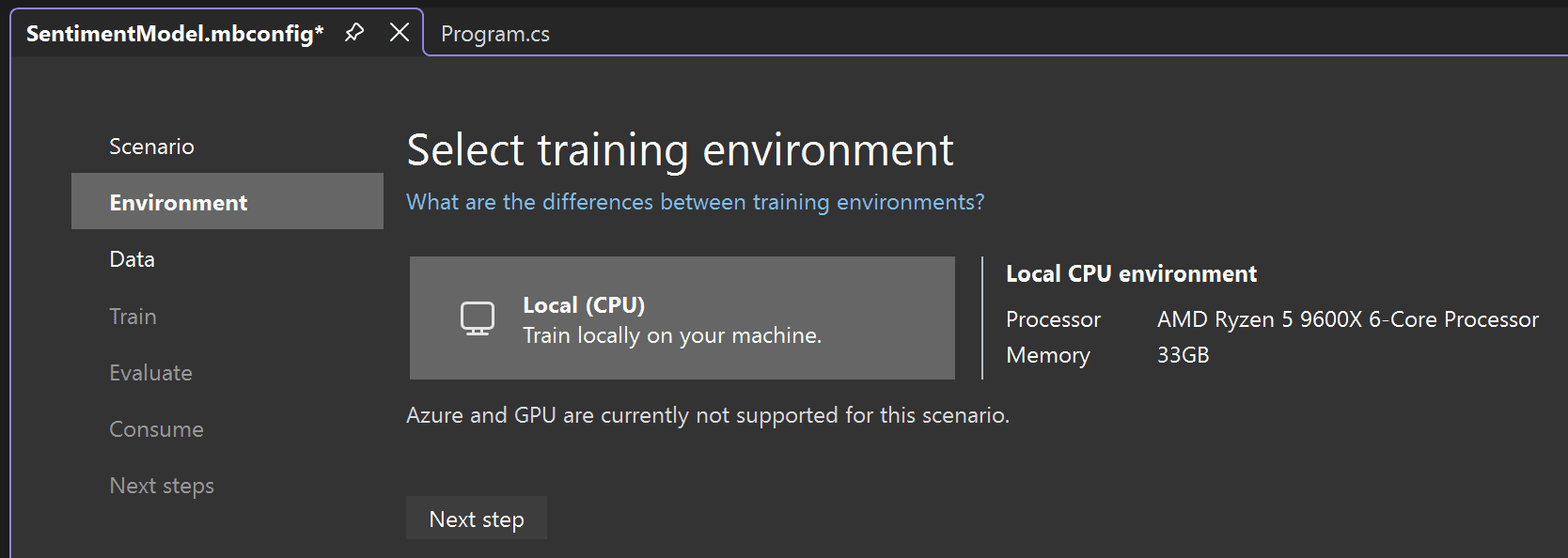
選取 [資料分類] 情節之後,您必須選擇定型環境。雖然某些情節支援在 Azure 中進行定型,但分類目前僅支援本機定型,因此請保持選取 [本機] 環境,並繼續進行 [資料] 步驟。
![在 Model Builder 中選取了本機定型環境。]()
若要產生您的模型,您必須選您的取機器學習案例。
ML.NET CLI 支援數個 ML 案例:
- [分類] - 當您想要預測資料屬於哪個類別 (例如,分析客戶評論的正面或負面情緒) 時,請使用此功能。
- 影像分類 - 如果您想要預測影像屬於哪個類別 (例如,預測影像為貓或狗的),不妨使用這個。
- [迴歸] (例如,數值預測) - 當您想要預測數值時,請使用它 (例如,預測房價) 。
- 預測 - 若要預測時間序列的未來值 (例如預測每季銷售額),請使用此方法。
- [建議] - 如果您想依據歷史評分為使用者建議項目時 (例如產品建議),請使用此選項。
在此案例中,您將根據客戶評論的內容 (文字) 預測情緒,因此您將使用 [分類]。
下載並新增資料
下載 Sentiment Labelled Sentences 資料集 (下載來源為 UCI 機器學習存放庫)。將 sentiment labelled sentences.zip 解壓縮,並將 yelp_labelled.txt 檔案儲存到 myMLApp 目錄。
您的方案總管看起來應如下所示:
yelp_labelled.txt 中的每個資料列代表使用者在 Yelp 上對某間餐廳留下的不同評論。第一個資料行代表使用者留下的評論,第二個資料行代表文字的情緒 (0 代表負面,1 代表正面)。資料行會以索引標籤分隔,且資料集沒有標頭。資料會看起來如下所示:
Wow... Loved this place. 1
Crust is not good. 0
Not tasty and the texture was just nasty. 0新增資料
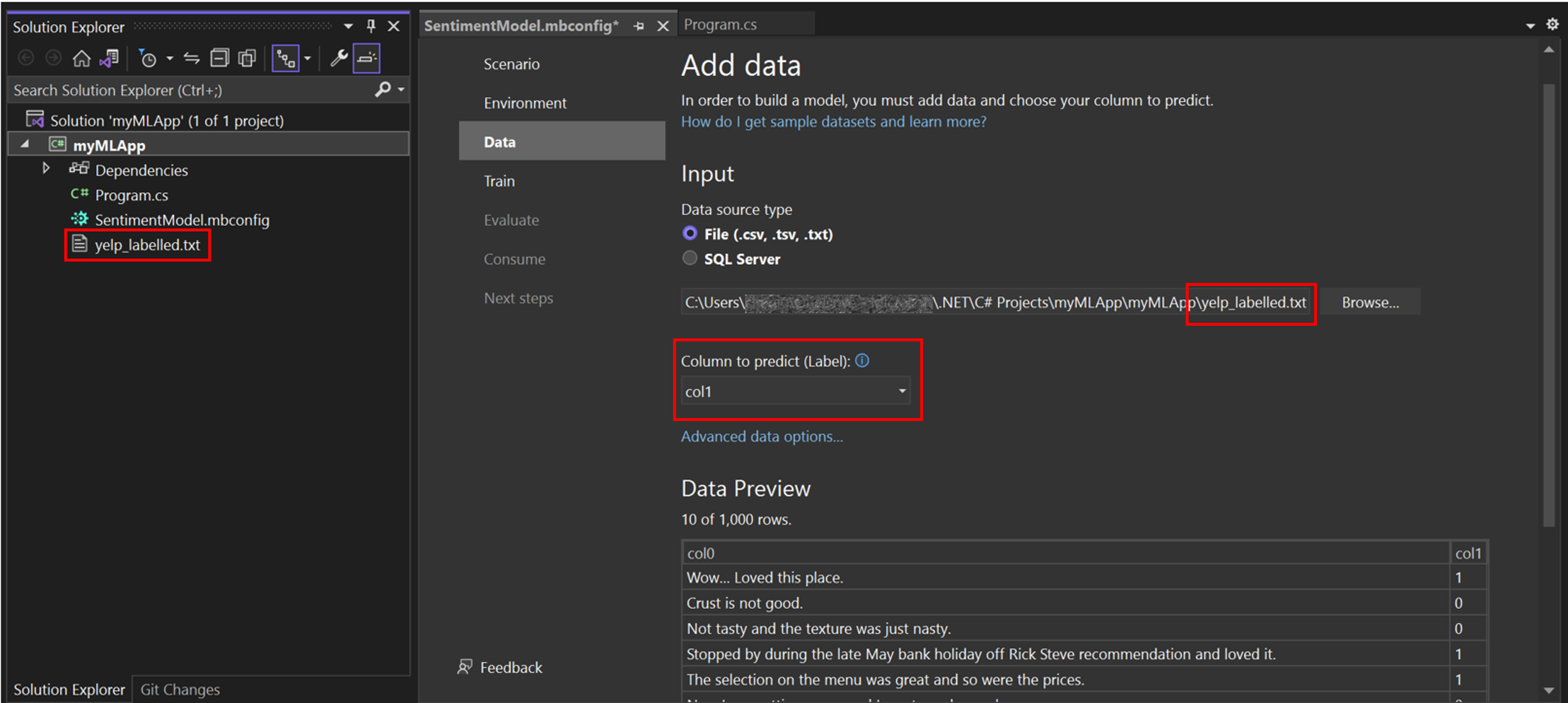
在 Model Builder 中,您可以從本機檔案新增資料,或連線到 SQL Server 資料庫。在此情況下,您將從檔案新增 yelp_labelled.txt。
選取 [檔案] 作為輸入資料來源類型。
瀏覽
yelp_labelled.txt。選取資料集後,資料的預覽會出現在 [資料預覽] 區段。因為資料集沒有標頭,會自動產生標頭 ("col0" 和 "col1")。在 [要預測的資料行 (標籤)] 下,請選取 ["col1"]。[標籤] 是您要預測的項目,在本例中指的是在資料集第二個資料行 ("col1") 中找到的情緒。
用來協助預測標籤的資料行稱為 [功能]。資料集中除了標籤以外的所有資料行,都會自動選取為功能。在此情況下,[審閱批註資料行] ("col0") 會是 [功能] 資料行。您可以更新功能資料行,並修改 [進階資料選項] 中的其他資料載入選項,但此範例並不需要。
新增資料之後,請前往訓練步驟。
定型您的模型
現在,您將使用 yelp_labelled.txt 資料集來定型您的模型。
Model Builder 會依據指定用於建立最佳執行模型的訓練時間量,評估具有不同演算法和設定的許多模型。
訓練時間是指您希望 Model Builder 探索各種模型的時間,系統會自動將其設為 60 秒。請注意,如果是較大的資料集,定型時間會較長。Model Builder 會根據資料集大小自動調整定型時間。
您可以更新 [進階] 定型選項中所使用的最佳化計量和演算法,但在此範例中不需要這麼做。
-
選取 [定型] 開始定型程序。定型開始之後,您可以看見剩餘的時間。
![Model Builder 定型]()
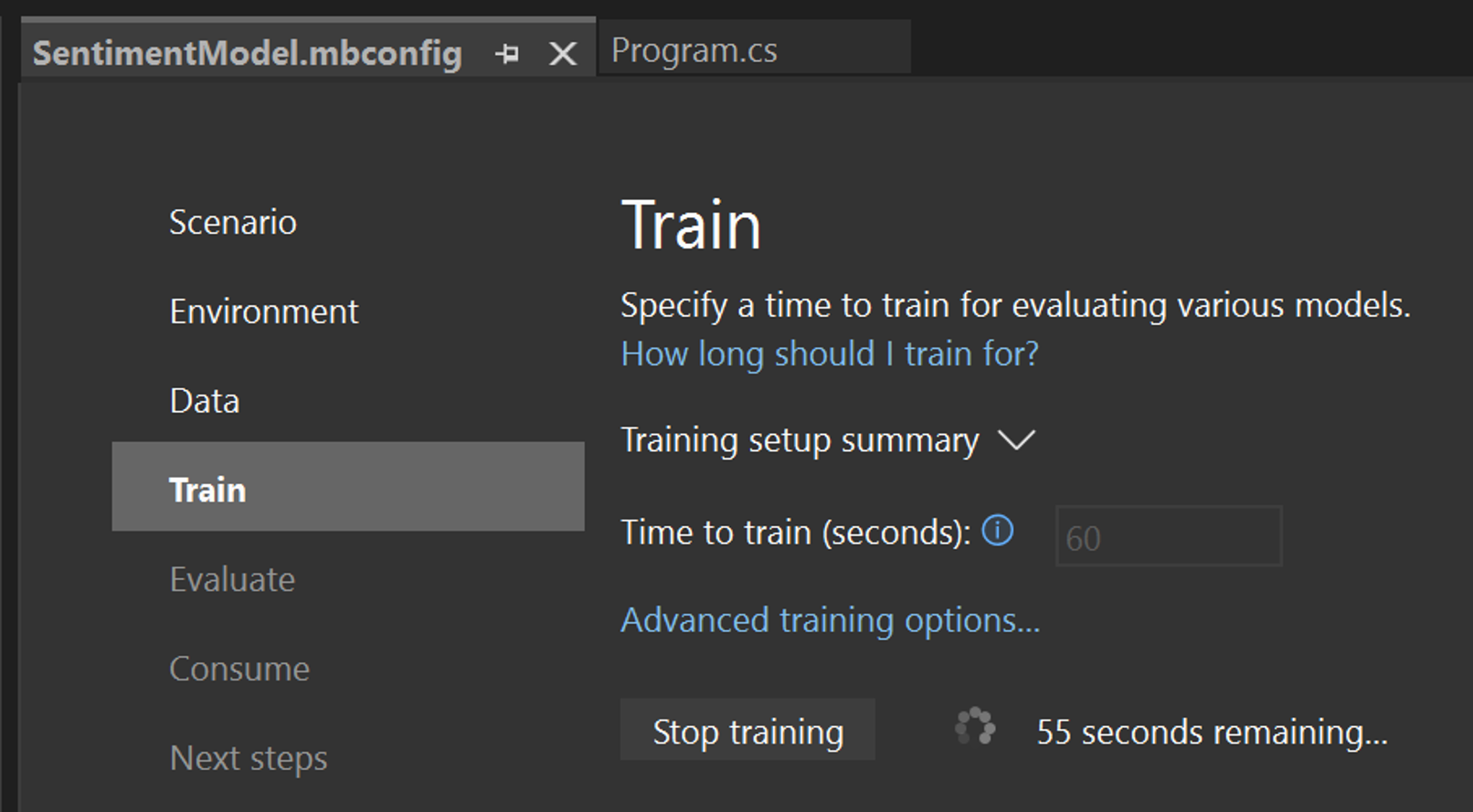
定型結果
訓練完成之後,您就可以看到訓練結果的摘要。
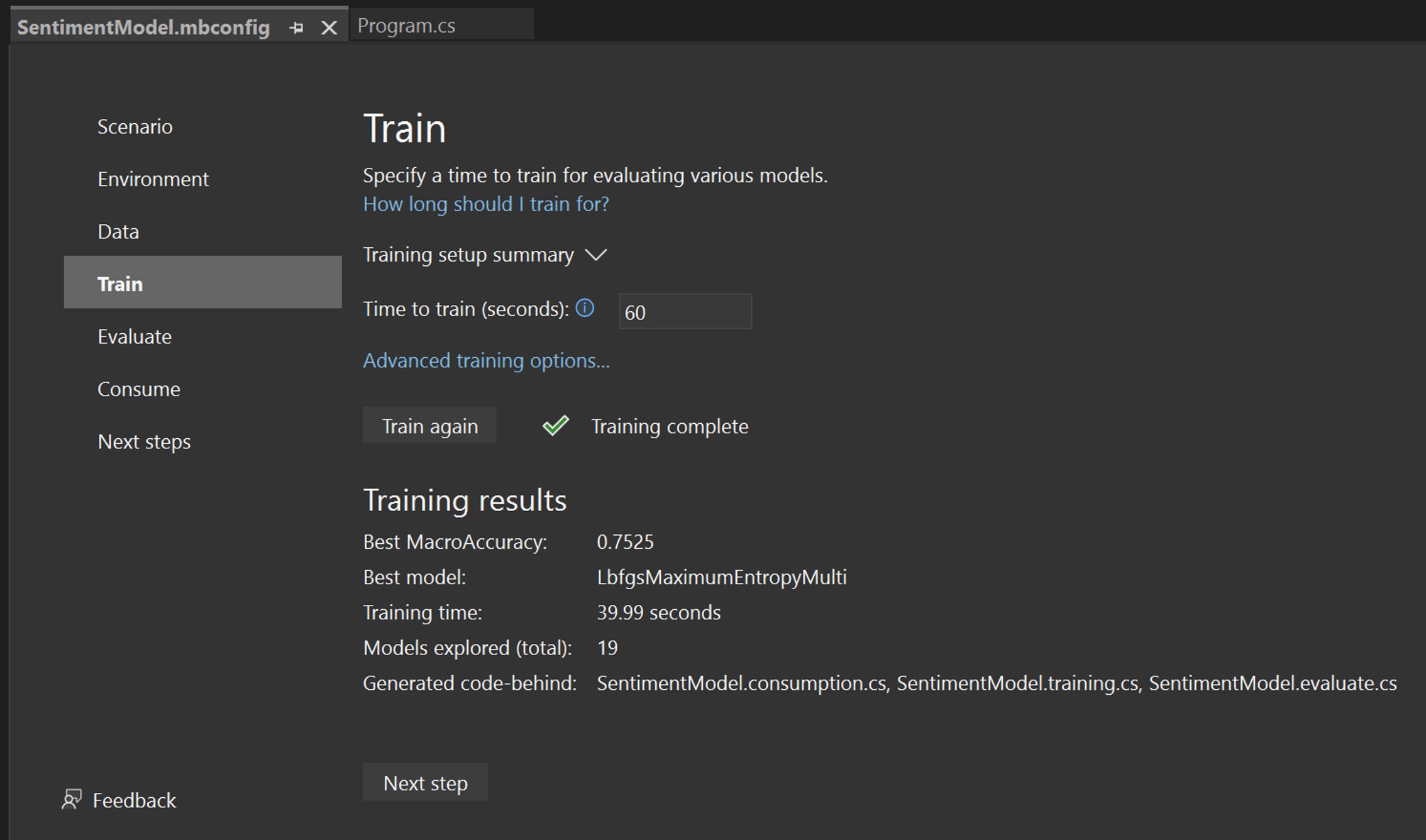
- 最佳宏觀正確性 - 這會向您顯示 Model Builder 所發現之最佳模型的正確性。正確性越高即表示模型對測試資料的預測越正確。
- 最佳模型 - 這會顯示在 Model Builder 探索期間執行最佳的演算法。
- [定型時間] - 這會向您顯示定型/探索模型所花費的總時間。
- 模型探索 (總計) - 這會顯示 ML.NET Model Builder 在給定時間內探索的模型總數。
- 產生的程式碼後置 - 這會顯示為協助取用模型或定型新模型而產生的檔案名稱。
如有需要,您可以在 [Machine Learning 輸出視窗] 中檢視有關訓練時段的詳細資訊。
模型定型完成後,請移至 [評估] 步驟。
在終端中,執行下列命令 (在您的 myMLApp 資料夾中):
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --name SentimentModel --train-time 60這些命令代表什麼?
mlnet classification 命令使用 AutoML 執行 ML.NET,可在指定的訓練時間數量內探索大量分類模型的反覆項目,並使用多種資料轉換、演算法及演算法選項組合,然後選擇表現最好的執行模型。
- --dataset: 您已選擇
yelp_labelled.txt作為資料集 (於內部,CLI 會將一個資料集分割成訓練資料集和測試資料集)。 - --label-col: 您必須指定要預測的目標資料行 (或標籤)。在此情況下,需要預測第二個資料行的情緒 (以零為基底索引的資料行表示這是資料行 "1")。
- --has-header: 使用此選項來指定資料集是否有標頭。在此情況下,資料集沒有標頭,因此其為 false。
- --name: 使用此選項可為機器學習模型及相關資產提供名稱。在此情況下,與此機器學習模型關聯的所有資產名稱中皆具有 SentimentModel。
- --train-time: 您也必須指定要 ML.NET CLI 探索不同模型的時間長度。在此情況下為 60 秒 (若訓練後找不到任何模型,您可以嘗試增加此數字)。請注意,若是較大的資料集,您應該設定較長的訓練時間。
進度
當 ML.NET CLI 探索不同的模型時,它會顯示下列資料:
- 開始定型 - 本節顯示每個模型反覆運算,包括該反覆運算所使用的定型器 (演算法) 和評估計量。
- 剩餘時間 - 此項目與進度列會指出在定型程序中剩餘的時間 (以秒為單位)。
- 最佳演算法 - 這會顯示到目前為止執行最佳的演算法。
- 最佳分數 - 這會顯示目前為止最佳模型的效能。較高的準確度表示模型對於測試資料的預測更正確。
您可以視需要在 CLI 產生的記錄檔案中,檢視有關定型工作階段的詳細資訊。
評估您的模型
[評估] 步驟會向您顯示效能最佳的演算法和最佳的正確性,讓您可以在 UI 中試用模型。
試用您的模型
您可以在 [試用您的模型]區段中的範例輸入上進行預測。文字方塊會預先填入資料集的第一行資料,但您可以變更輸入並選取 [預測] 按鈕來嘗試不同的情緒預測。
在此情況下,0 表示負情緒,1 表示正情緒。
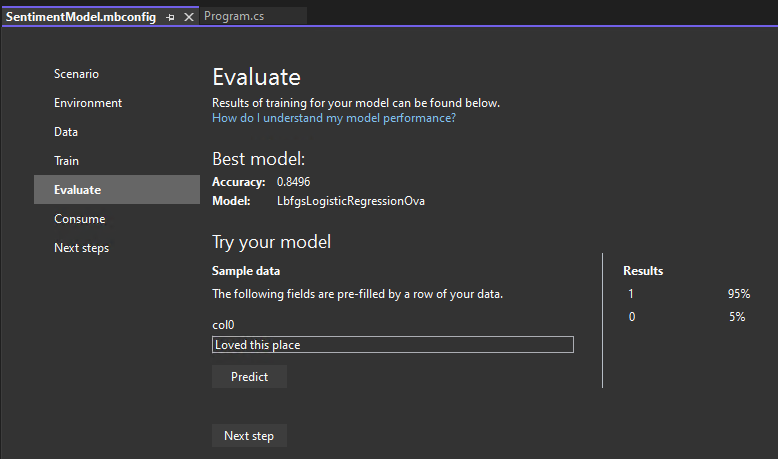
注意: 如果您的模型效能不佳 (例如正確性很低,或者模型只預測 '1' 值),您可以嘗試新增更多時間並再次進行定型。這是使用非常小型資料集的範例; 針對生產等級的模型,您會想要新增更多資料與定型時間。
在評估並試用您的模型之後,移至 [使用] 步驟。
ML.NET CLI 選取最佳模型之後,會顯示 [訓練摘要],其中會顯示探索流程的摘要,包括在指定的訓練時間中探索到的模型數。
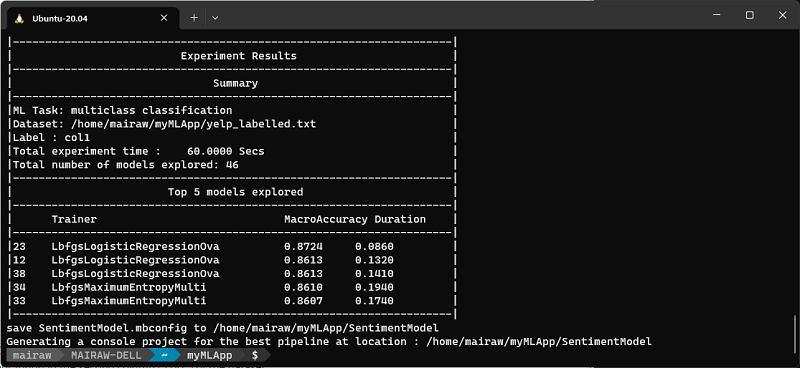
熱門模型
儘管 ML.NET CLI 會產生效能最高模型的程式碼,但它也會在指定的探索時間內找到具備最高正確性的排名在前模型 (最多 5 項)。它會為這些排名在前的模型顯示多項評估計量,包括 AUC、AUPRC 和 F1 分數。如需詳細資訊,請參閱e ML.NET 計量。
產生程式碼
定型完成之後,會自動將四個檔案作為程式碼後置新增至 SentimentModel.mbconfig:
SentimentModel.consumption.cs: 此檔案包含模型輸入和輸出類別,以及可用於模型使用量的Predict方法。SentimentModel.evaluate.cs: 此檔案包含CalculatePFI方法,其使用「排列特徵重要度」(PFI) 技術來評估哪些功能對模型預測的貢獻最大。SentimentModel.mlnet: 這個檔案是已定型的 ML.NET 模型,它是一個序列化的 ZIP 檔案。SentimentModel.training.cs: 這個檔案包含程式碼,以便了解輸入資料行對模型預測的重要性。
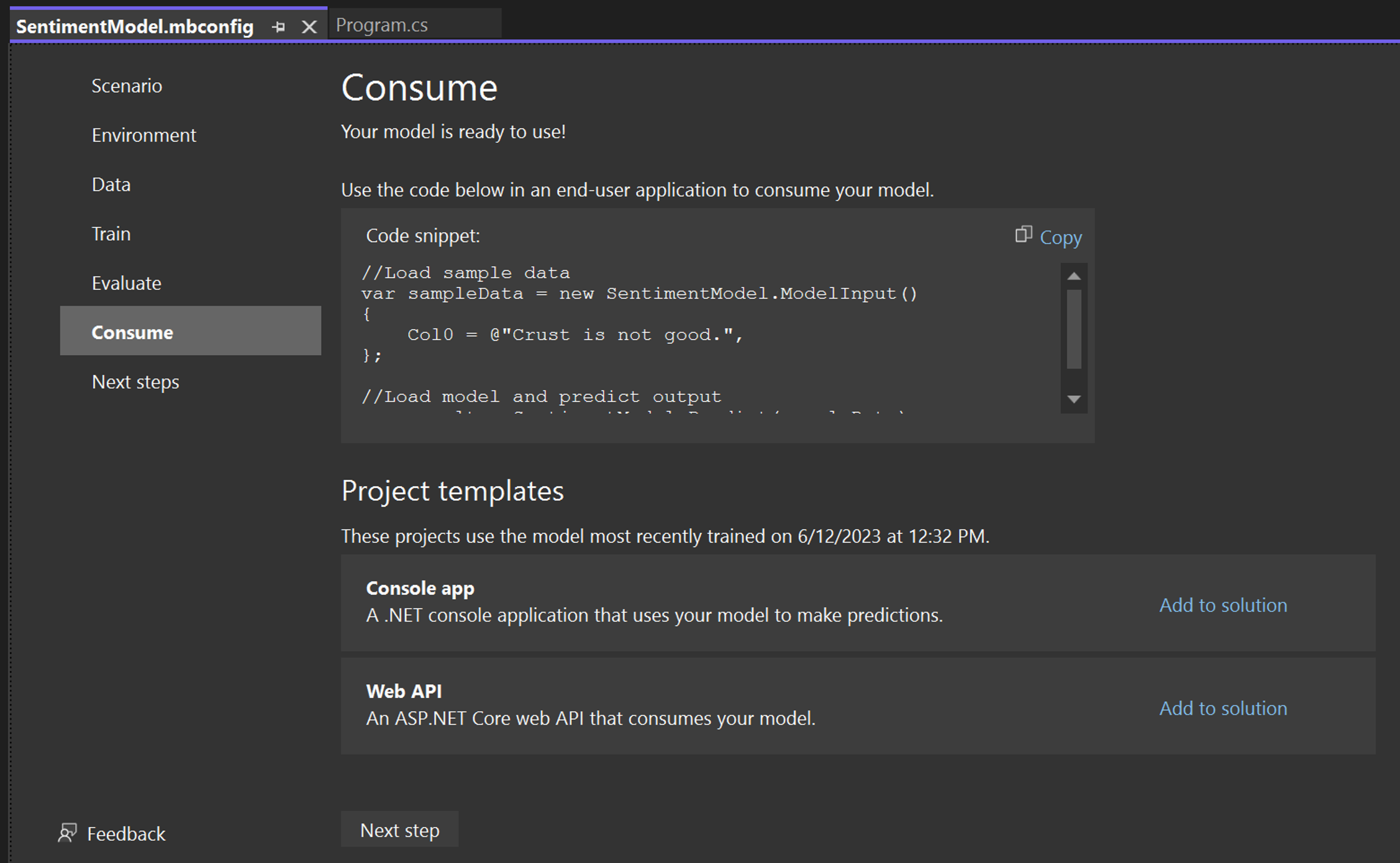
在 Model Builder 的 [取用] 步驟中提供了程式碼片段,該程式碼片段會建立模型的範例輸入,並使用模型對該輸入進行預測。
Model Builder 還會提供專案範本,您可以選擇將範本新增至解決方案。有兩種專案範本 (主控台應用程式和 Web API),兩者皆使用已定型模型。
ML.NET CLI 會同時新增機器學習模型和用於訓練及使用模型的程式碼,其中包括以下內容:
-
已建立名為 SentimentModel 的新目錄,內含包括下列檔案的 .NET 主控台應用程式:
Program.cs: 此檔案包含執行模型的程式碼。SentimentModel.consumption.cs: 此檔案包含模型輸入和輸出類別,以及可用於模型使用量的Predict方法。SentimentModel.mbconfig: 此檔案是 JSON 檔案,可追蹤您訓練的設定和結果。SentimentModel.training.cs: 此檔案包含用來訓練最終模型的訓練管線 (資料轉換、演算法和演算法參數)。SentimentModel.zip: 這個檔案是已定型的 ML.NET 模型,它是一個序列化的 zip 檔案。
若要嘗試模型,您可以執行主控台應用程式,以使用模型預測單一陳述式的情緒。
使用您的模型
最後一個步驟是在使用者應用程式中使用您的訓練模型。
-
使用下列程式碼取代您
myMLApp專案中的Program.cs程式碼:Program.csusing MyMLApp; // Add input data var sampleData = new SentimentModel.ModelInput() { Col0 = "This restaurant was wonderful." }; // Load model and predict output of sample data var result = SentimentModel.Predict(sampleData); // If Prediction is 1, sentiment is "Positive"; otherwise, sentiment is "Negative" var sentiment = result.PredictedLabel == 1 ? "Positive" : "Negative"; Console.WriteLine($"Text: {sampleData.Col0}\nSentiment: {sentiment}"); -
執行
myMLApp(選取 Ctrl+F5 或 [偵錯] > [在不偵錯的情況下啟動])。您應該會看到下列輸出,預測輸入語句是正或負。![輸出: 文字: 此餐館非常不錯。情感: 正值]()

ML.NET CLI 已為您產生經過訓練的模型和程式碼,因此您現在可以按照以下步驟在 .NET 應用程式 (例如,SentimentModel 主控台應用程式) 中使用該模型:
- 在命令列中,瀏覽至
consumeModelApp目錄。Command promptcd SentimentModel -
在任何程式碼編輯器中開啟
Program.cs,並檢查程式碼。程式碼應如下所示:Program.csusing System; namespace SentimentModel.ConsoleApp { class Program { static void Main(string[] args) { // Add input data SentimentModel.ModelInput sampleData = new SentimentModel.ModelInput() { Col0 = @"Wow... Loved this place." }; // Make a single prediction on the sample data and print results var predictionResult = SentimentModel.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: @{"Wow... Loved this place."}"); Console.WriteLine($"Col1: {1F}"); Console.WriteLine($"\n\nPredicted Col1: {predictionResult.PredictedLabel}\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); } } } -
執行您的
SentimentModel.ConsoleApp。您可以在終端機中執行下列命令來執行此操作 (請確保您位於SentimentModel目錄中):Command promptdotnet run輸出看起來應該像這樣:
Command promptUsing model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data... Col0: Wow... Loved this place. Col1: 1 Class Score ----- ----- 1 0.9651076 0 0.034892436 =============== End of process, hit any key to finish ===============
後續步驟
恭喜,您已使用 ML.NET Model Builder 建置您的第一個機器學習模型!
現在您已經具備基本知識,請在 Microsoft Learn 上繼續使用自我引導式學習模組,您將使用感應器資料來偵測製造裝置是否已損毀。
適用於初學者的 ML.NET
讓 Luis 向您介紹機器學習與 AI 的概念、說明您可以如何使用它,以及指導您如何開始使用 OpenAI、Azure AI 服務,以及 ML.NET:
您可能也會想了解...



恭喜,您已使用 ML.NET CLI 建置您的第一機器學習模型!
既然您已使用 ML.NET CLI 進行分類 (尤其是情感分析) ,您可以嘗試其他案例。試用回歸案例 (尤其是定價預測),使用計程車車資資料集來組建具有 ML.NET CLI 的 ML.NET 模型。
適用於初學者的 ML.NET
讓 Luis 向您介紹機器學習與 AI 的概念、說明您可以如何使用它,以及指導您如何開始使用 OpenAI、Azure AI 服務,以及 ML.NET:
您可能也會想了解...