

endjin радикально упрощает задачи с помощью ML.NET

Промышленность
Информационные технологии и услуги
Размер организации
Малый (от 1 до 100 сотрудников)
Страна/регион
Великобритания
Технологии
Компания
Endjin — это бутик-бизнес, консалтинговая компания в области технологий и партнер со статусом Microsoft Gold Partner в области облачной платформы, платформы данных, аналитики данных и DevOps, базирующийся в Соединенном Королевстве. Endjin с заразительным энтузиазмом относится к революционной силе технологий и к использованию этой силы для помощи клиентам в решении сложных проблем. В последнее время они сосредоточились на использовании машинного обучения для решения приземленных, но важных бизнес-задач. Это продемонстрировало следующее: хотя машинное обучение отлично подходит для решения новых задач, его способность революционизировать простые повседневные задачи часто упускается из виду.
Мы были поражены легкостью, с которой AutoML и ML.NET можно использовать для сокращения времени, затрачиваемого на трудоемкие и монотонные задачи. Свобода, полученная благодаря использованию этих доступных и мощных технологий, позволяет нам сосредоточить свое время на творческой аналитике и получении ценной информации на основании данных, которые они производят".
Бизнес-проблема
В 2014 г. компания endjin создала Azure Weekly – бесплатный информационный бюллетень, в котором собраны главные новости экосистемы Azure за неделю. Для первых 25 выпусков команда endjin курировала бюллетень вручную, но по мере роста объема контента они поняли, что это невозможно. Они применили свою корпоративную мантру «работать умнее» и автоматизировали сквозной процесс, создав собственный классификатор текста C# для классификации статей из более чем 300 блогов по 19 категориям, включая AI + машинное обучение, аналитику, DevOps, Интернет вещей, сети и Интернет. Это работало относительно хорошо, но в дополнение к требованию поддерживать активный список ключевых слов для классификации, каждую неделю приходилось вносить ручные исправления, что приводило к значительным накладным расходам на обслуживание.
Спустя более 200 выпусков и много тысяч подписчиков компания Endjin решила начать искать решение для машинного обучения. В основе контент-платформы они знали, что им нужно решить две основные проблемы — проблему двоичной классификации ("это статья об Azure?") и проблему классификации по нескольким классам ("какую область Azure охватывает эта статья?"). Таким образом, компания Endjin решила использовать ML.NET для решения этих проблем, улучшения своей платформы и устранения накладных расходов на обслуживание вручную.
Когда вы смотрите на работу/процессы, выполняемые большинством организаций, вы можете разбить их на серию 1-секундных шагов принятия решений. Если вы примените машинное обучение, реактивные рабочие процессы и экономику API к проблемной области, мы начнем добираться до сути возможностей 4-ой промышленной революции"
Почему ML.NET?
Хотя их предпочтительным языком программирования является C#, ранее отсутствие первоклассной среды машинного обучения для .NET означало, что endjin использовала R и Python в своих повседневных экспериментах с клиентами, сталкивающимися с наукой о данных и машинным обучением. Однако производство моделей машинного обучения, написанных на R и Python, было проблематичным из-за ограниченных возможностей хостинга. Остальная часть контент-платформы endjin построена с использованием компонентов PaaS и Serverless, поэтому сочетание ML.NET и функций Azure было невероятно привлекательным для компании; как только на //build 2018 было объявлено о ML.NET, они начали использовать инфраструктуру машинного обучения в своем приложении.
Влияние ML.NET и AutoML
Endjin значительно выиграл от высокой производительности ML.NET не только с точки зрения повышения скорости при классификации статей, но и с точки зрения точности. С момента внедрения ML.NET они увидели гораздо меньше статей с неправильной классификацией, что приводит к меньшему количеству ручного вмешательства и более быстрому созданию контента.
Использование интерфейса командной строки ML.NET с AutoML также сделало весь процесс обучения, оценки и создания кода для использования ML.NET надежным. Использование AutoML для выбора наиболее эффективной модели и автоматического создания кода обучения и потребления модели для классификации (по сравнению с ручным выбором преобразований данных, алгоритмов и параметров алгоритма для создания модели и кода ML.NET) повысило точность модели с 68 % до 78%, а применение этой модели к историческим данным не только выявило множество статей, которые были классифицированы неправильно, но также выявило много действительных статей, которые были исключены исходной моделью классификации.
Архитектура решения
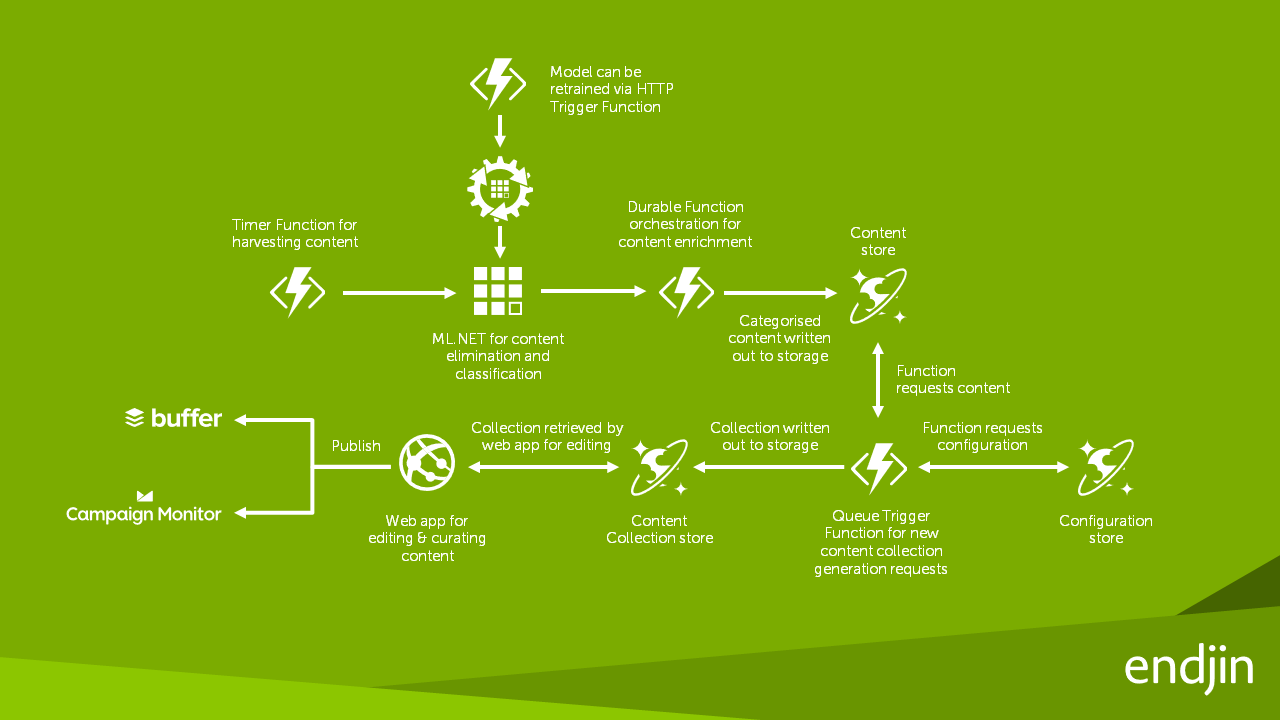
Создание приложения с ML.NET
Когда Endjin впервые начал использовать ML.NET, они создали инструмент для преобразования исторических данных платформы контента в набор данных CSV для ручного обучения модели ML.NET, а также создали другой инструмент для случайного выбора 20% набора обучающих данных в качестве проверки набора данных. Затем они вручную создали модель ML.NET, чтобы предсказать, к какой категории относится статья.
Как только интерфейс командной строки ML.NET с AutoML стал доступен для использования, он упростил процесс и дал значительно лучшие результаты. Во-первых, AutoML автоматически сгенерировал набор данных проверки из набора обучающих данных, поэтому второй пользовательский инструмент endjin больше не нужен. Во-вторых, установив максимальное время исследования на один час, AutoML смог обучить, настроить и оценить несколько моделей классификации и отобразить 5 лучших моделей.
Получив обученные модели ML.NET, сгенерированные с помощью AutoML, endjin интегрировала эти модели в существующую платформу контента, просто заменив существующие пользовательские алгоритмы классификации. Модели ML.NET размещались внутри функции Azure, чтобы обеспечить гибкое масштабирование оценки модели. Была использована новая устойчивая функция, позволяющая переобучать модели по требованию.
Обработка данных
К счастью, еще когда они создавали начальную версию платформы содержимого, сотрудники endjin знали, что в будущем захотят улучшить ее с помощью машинного обучения. Поэтому они сохраняли все данные для создания бюллетеней и в обработанном, и в необработанном форматах (более 4000 файлов JSON общим размером около 3 ГБ). Эти данные были преобразованы в два набора данных для обучения: один CSV-файл размером 28 МБ для двоичной классификации и другой размером 9 МБ для классификации по нескольким классам.
Преобразования данных и алгоритмы машинного обучения
Поскольку заголовок и содержание классифицируемых сообщений блога представляют собой свободный текст, их необходимо преобразовать с помощью преобразования данных Featurize Text. Затем заголовок и содержимое были объединены в одно поле с помощью the Конкатенативного преобразования данных.
Исходная модель, созданная Endjin вручную, использовала алгоритм многоклассовой классификации SdcaMaximumEntropy. Однако когда компания Endjin использовала интерфейс командной строки ML.NET с AutoML, они обнаружили еще более эффективные модели для своих сценариев.
Для первого сценария («это статья об Azure?») AutoML выбрал алгоритм AveragedPerceptronBinary как наиболее эффективный алгоритм. Для второго сценария («Какую область Azure охватывает эта статья?\») AutoML выбрала LightGbmMulti в качестве наиболее эффективного алгоритма и сгенерировала следующий код для обучения мультиклассового классификатора:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Компания Endjin использовала ML.NET для улучшения процесса выбора и категоризации статей для своего информационного бюллетеня Azure. Использование ML.NET и AutoML для создания моделей машинного обучения также позволило компании меньше сосредотачиваться на точной настройке параметров моделей и больше на обеспечении их бизнес-ценности.