

O HMRI construiu uma estrutura de ML Human-In-The-Loop para pesquisa médica usando ML.NET

Setor
Serviços de saúde
Tamanho da Organização
Grande (1.000 a 9.999 funcionários)
País/região
Austrália
Tecnologia
Empresa
O Hunter Medical Research Institute (HMRI) é uma organização cujo objetivo é melhorar a saúde e o bem-estar de suas comunidades. Ele faz isso reunindo cientistas, médicos e profissionais de saúde pública para acelerar o fornecimento de novas e melhores soluções de saúde.
O Hunter Medical Research Institute (HMRI) é uma organização cujo objetivo é melhorar a saúde e o bem-estar de suas comunidades. Ele faz isso reunindo cientistas, médicos e profissionais de saúde pública para acelerar o fornecimento de novas e melhores soluções de saúde.
Os detalhes da pesquisa podem ser encontrados no artigo,"Um método para desenvolvimento rápido de aprendizado de máquina para mineração de dados com Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, Simon Quilty.
Problema de negócios
As instituições de saúde têm grandes quantidades de dados. Normalmente, esses dados estão no formato de texto não estruturado. Mesmo quando digitalizados, muitas vezes é difícil extrair insights significativos e acionáveis dos dados. Técnicas como expressões regulares, consultas SQL e software de processamento de linguagem natural "pronto para uso" têm sucesso limitado.
Nesses casos, o aprendizado de máquina pode ajudar a analisar e extrair informações valiosas dos dados. Ferramentas de aprendizado de máquina foram usadas anteriormente para classificar notas clínicas em categorias para uma variedade de propósitos clínicos e de pesquisa. No entanto, o uso dessas ferramentas de aprendizado de máquina geralmente exige habilidades de desenvolvimento de software ou ciência de dados. Habilidades que muitas vezes estão além do escopo dos profissionais médicos.
Mesmo em cenários em que um modelo é treinado, quando deixado sem supervisão, os modelos alcançam resultados abaixo do ideal quando usados no mundo real. Com os altos riscos envolvidos nas decisões médicas, é importante que os profissionais médicos possam confiar em seus modelos e, nos casos em que um modelo está errado, usar sua experiência para fornecer comentários.
É por isso que os pesquisadores do HMRI usaram o ML.NET para desenvolver uma estrutura de desenvolvimento de aprendizado de máquina human-in-the-loop (HITL) para facilitar que profissionais médicos rotulem dados, treinem modelos e usem esses modelos para inferência sem necessidade de programação ou experiência com aprendizado de máquina. O mais importante é que eles criaram um mecanismo de comentários para que especialistas médicos possam incorporar suas habilidades e experiência no processo de aprendizado de máquina. Como resultado, esse alto nível de supervisão obtém melhores resultados em casos de uso do mundo real com menos pontos de dados.
Por que ML.NET?
O HMRI usou o Model Builder para começar a usar o ML.NET. O Model Builder forneceu uma maneira de validar rapidamente se o problema pode ser resolvido usando o aprendizado de máquina. Depois de validar a eficácia do uso do aprendizado de máquina para o seu problema, eles aproveitaram a API de machine learning automatizado (AutoML) do ML.NET. A API de AutoML do ML.NET automatizou a escolha um algoritmo, bem como a otimização de pipeline e hiperparâmetro dentro da sua estrutura de desenvolvimento de machine learning HITL personalizada.
Impacto do ML.NET
HMRI usou Model Builder para começar a usar o ML.NET. O Model Builder forneceu uma maneira de validar rapidamente se o problema pode ser resolvido usando o aprendizado de máquina. Depois de validar a eficácia do uso do aprendizado de máquina para o seu problema, eles aproveitaram a API de machine learning automatizado (AutoML) do ML.NET. A API de AutoML do ML.NET automatizou a escolha um algoritmo, bem como a otimização de pipeline e hiperparâmetro dentro da sua estrutura de desenvolvimento de machine learning HITL personalizada.
Ao usar o ML.NET, o HMRI removeu a necessidade de terceirizar os esforços de desenvolvimento e pôde usar as habilidades e os recursos existentes para construir tudo internamente.
Além disso, aproveitando o ML.NET como parte de sua solução, eles foram capazes de fornecer uma interface para especialistas médicos treinarem e consumirem modelos de machine learning que não exigiam nenhuma experiência de programação ou aprendizado de máquina.
Arquitetura da solução
A interface com a qual os usuários interagem é um aplicativo Web que suporta várias tarefas nas fases de treinamento e consumo do modelo.
Dados
Para as implementações iniciais, os dados usados para treinar os modelos vieram de registros médicos históricos. Um conjunto de dados utilizado foi um banco de dados de mortalidade de 40 anos contendo cerca de 30.000 registros e o outro um conjunto de dados de recuperação aeromédica contendo cerca de 13.000 registros.
Os dados são armazenados em um banco de dados do SQL Server. Antes do treinamento, os especialistas médicos usam o aplicativo Web para rotular um conjunto de testes em categorias predefinidas para calcular as métricas de precisão durante o ciclo de treinamento. Em seguida, um pequeno conjunto de dados escolhidos aleatoriamente é usado para a primeira rodada de treinamento.
Fluxo de trabalho de treinamento, avaliação e consumo

O treinamento do modelo é acionado pelos especialistas médicos do aplicativo Web. O código do ML.NET do lado do servidor lida com treinamento e reciclagem de modelos. O modelo então prevê todos os dados restantes. As previsões e pontuações de confiança são armazenadas no banco de dados do SQL Server. Os procedimentos armazenados do SQL Server são usados para calcular e armazenar métricas de precisão em relação ao conjunto de testes. Essas métricas são exibidas de volta aos especialistas médicos por meio do aplicativo Web. Todo esse processo é concluído em segundos.
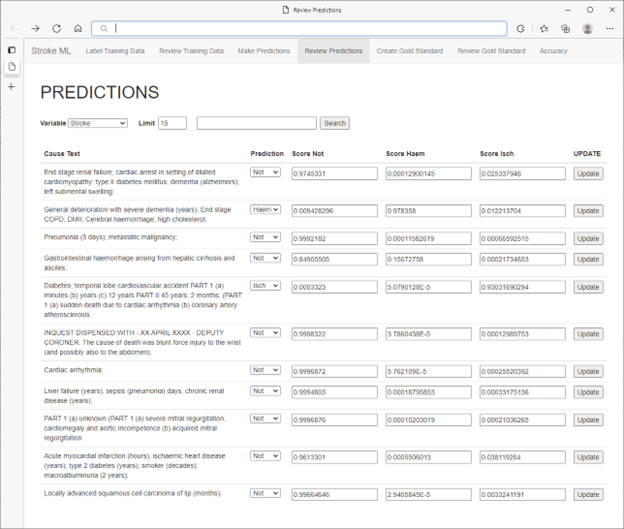
* Dados de pacientes não reais
Os especialistas médicos descobriram que foram capazes de usar intuitivamente métricas de recall e especificidade para orientar a seleção de casos adicionais para rotulagem, resultando em melhoria máxima e rápida no desempenho do modelo. Outros ganhos de desempenho foram realizados direcionando seletivamente a rotulagem com base na classificação por pontuações de confiança. Ao fazer isso, os especialistas médicos se envolveram na aprendizagem ativa, não apenas confirmando previsões com pontuações baixas, mas também corrigindo previsões erradas com pontuações altas.
Nesse ponto, os especialistas médicos podem iniciar um trabalho para treinar novamente o modelo usando os rótulos de dados corrigidos. Este rótulo, treinamento, ciclo de avaliação continua até que os especialistas médicos estejam satisfeitos com o desempenho do seu modelo. Os carimbos de data e hora do evento de treinamento, métricas de avaliação e outras informações são registrados no banco de dados do SQL Server para inspeção e auditabilidade posteriores.
Depois que o ciclo rotulagem, treinamento e avaliação são concluídos, um conjunto de previsões de validação é selecionado do banco de dados do SQL Server usando um gerador de números aleatórios interno do SQL Server. Esses pontos de dados foram rotulados por um painel de especialistas médicos cegados para as previsões do modelo.
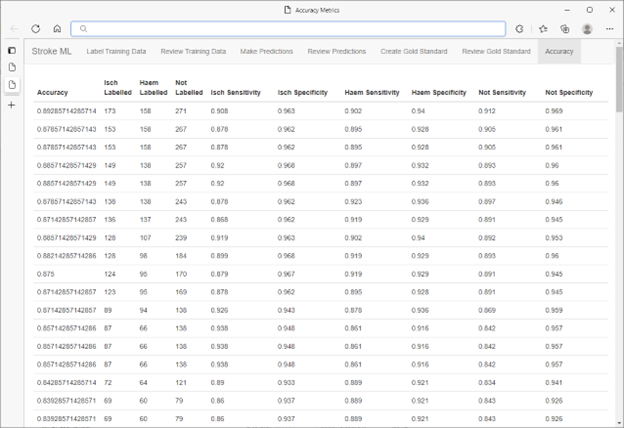
A precisão resultante do modelo foi de meados a 90, o que deu aos pesquisadores confiança para usar as categorizações produzidas pelo modelo em suas pesquisas médicas em andamento. A velocidade do ML.NET combinada com o fluxo de trabalho HITL significava que ele poderia ser repetido para diferentes tarefas de categorização e/ou diferentes conjuntos de dados de uma maneira altamente eficiente e econômica, sem comprometer a precisão.
Planos Futuros
O fluxo de trabalho Doctor-In-The-Loop desenvolvido por pesquisadores do HMRI será inestimável para futuras pesquisas que dependem da categorização rápida e precisa de textos livres médicos.