

HMRI a construit un framework ML Human-In-The-Loop pour la recherche médicale à l'aide de ML.NET

Secteur
Santé
Taille de l’organisation
Grand (1 000-9 999 employés)
Pays/région
Australie
Technologie
Entreprise
Hunter Medical Research Institute (HMRI) est une organisation dont le but est d'améliorer la santé et le bien-être de leurs communautés. Il le fait en réunissant des scientifiques, des cliniciens et des professionnels de la santé publique pour accélérer la fourniture de solutions de santé nouvelles et meilleures.
Hunter Medical Research Institute (HMRI) est une organisation dont le but est d'améliorer la santé et le bien-être de leurs communautés. Il le fait en réunissant des scientifiques, des cliniciens et des professionnels de la santé publique pour accélérer la fourniture de solutions de santé nouvelles et meilleures.
Les détails de la recherche peuvent être trouvés dans l’article, "A method for rapid machine learning development for data exploitation minière avec Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, Simon Quilty.
Problème d’entreprise
Les établissements de santé disposent de grandes quantités de données. Habituellement, ces données sont au format texte non structuré. Même lorsqu'elles sont numérisées, il est souvent difficile d'extraire des informations significatives et exploitables des données. Des techniques telles que les expressions régulières, les requêtes SQL et les logiciels de traitement du langage naturel « prêts à l'emploi » ont un succès limité.
Dans de tels cas, l'apprentissage automatique peut aider à analyser et à extraire des informations précieuses des données. Les outils d'apprentissage automatique ont déjà été utilisés pour classer les notes cliniques en catégories à diverses fins cliniques et de recherche. Cependant, l'utilisation de ces outils d'apprentissage automatique nécessite souvent des compétences en développement de logiciels ou en science des données. Des compétences qui dépassent souvent le cadre des professionnels de la santé.
Même dans les scénarios où un modèle est formé, lorsqu'il n'est pas supervisé, les modèles obtiennent des résultats sous-optimaux lorsqu'ils sont utilisés dans le monde réel. Avec les enjeux élevés impliqués dans les décisions médicales, il est important que les professionnels de la santé puissent faire confiance à leurs modèles et, dans les cas où un modèle est erroné, utiliser leur expertise pour fournir des commentaires.
C'est pourquoi les chercheurs du HMRI ont utilisé ML.NET pour développer un cadre de développement d'apprentissage automatique Human-In-The-Loop (HITL) afin de permettre aux professionnels de la santé d'étiqueter plus facilement les données, de former des modèles et d'utiliser ces modèles pour l'inférence sans aucune expérience en programmation ou en apprentissage automatique requise. Plus important encore, ils ont mis en place un mécanisme de rétroaction permettant aux experts médicaux d’intégrer leurs compétences et leur expertise dans le processus d’apprentissage automatique. Par conséquent, ce niveau élevé de supervision permet d’obtenir de meilleurs résultats dans des cas d’utilisation réels avec moins de points de données.
Pourquoi ML.NET ?
HMRI a utilisé Model Builder pour démarrer avec ML.NET. Model Builder a fourni un moyen de valider rapidement si leur problème pouvait être résolu à l’aide de l’apprentissage automatique. Une fois qu’ils ont validé l’efficacité de l’utilisation de l’apprentissage automatique pour leur problème, ils ont exploité l’API ML.NET Automated Machine Learning (AutoML). L'API ML.NET AutoML a automatisé le choix d'un algorithme ainsi que l'optimisation du pipeline et des hyperparamètres dans leur cadre de développement d'apprentissage automatique HITL personnalisé.
Impact de ML.NET
HMRI a utilisé Model Builder pour démarrer avec ML.NET. Model Builder a fourni un moyen de valider rapidement si leur problème pouvait être résolu à l’aide de l’apprentissage automatique. Une fois qu’ils ont validé l’efficacité de l’utilisation de l’apprentissage automatique pour leur problème, ils ont exploité l’API ML.NET Automated Machine Learning (AutoML). L'API ML.NET AutoML a automatisé le choix d'un algorithme ainsi que l'optimisation du pipeline et des hyperparamètres dans leur cadre de développement d'apprentissage automatique HITL personnalisé.
En utilisant ML.NET, HMRI a supprimé le besoin d'externaliser les efforts de développement et a pu utiliser les compétences et les ressources existantes pour tout construire en interne.
De plus, en tirant parti de ML.NET dans le cadre de leur solution, ils ont pu fournir une interface permettant aux experts médicaux de former et d'utiliser des modèles d'apprentissage automatique qui ne nécessitaient aucune expérience en programmation ou en apprentissage automatique.
Architecture de la solution
L'interface avec laquelle les utilisateurs interagissent est une application Web qui prend en charge plusieurs tâches dans les phases de formation et de consommation du modèle.
Données
Pour les implémentations initiales, les données utilisées pour former les modèles provenaient de dossiers médicaux historiques. Un ensemble de données utilisé était une base de données de mortalité sur 40 ans contenant environ 30 000 enregistrements et l'autre un ensemble de données de récupération aéromédicale contenant environ 13 000 enregistrements.
Les données sont stockées dans une base de données SQL Server. Avant la formation, les experts médicaux utilisent l'application Web pour étiqueter un ensemble de tests dans des catégories prédéfinies afin de calculer des mesures de précision pendant la boucle de formation. Ensuite, un petit ensemble de données choisies au hasard est utilisé pour le premier cycle de formation.
Flux de travail de formation, d'évaluation et de consommation

La formation du modèle est déclenchée par les experts médicaux depuis l'application Web. Le code ML.NET côté serveur gère la formation et le recyclage du modèle. Le modèle prédit ensuite toutes les données restantes. Les prédictions et les scores de confiance sont stockés dans la base de données SQL Server. Les procédures stockées SQL Server sont utilisées pour calculer et stocker les métriques de précision par rapport à l'ensemble de test. Ces mesures sont ensuite affichées aux experts médicaux via l'application Web. Tout ce processus se termine en quelques secondes.
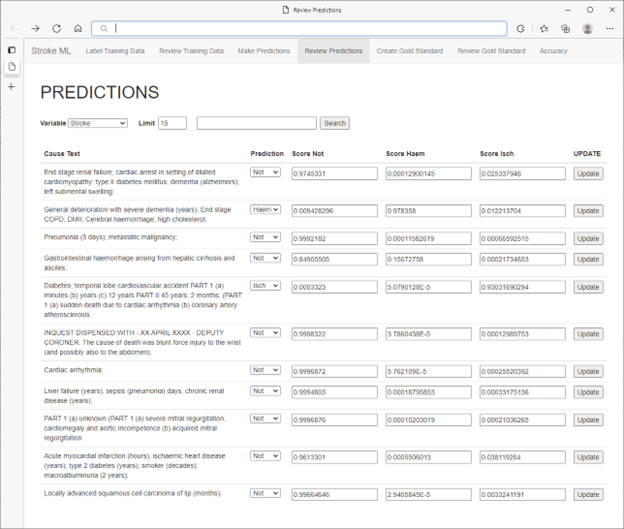
* Pas de données réelles sur les patients
Les experts médicaux ont constaté qu'ils étaient capables d'utiliser intuitivement des mesures de rappel et de spécificité pour guider la sélection de cas supplémentaires à étiqueter, ce qui a entraîné une amélioration à la fois maximale et rapide des performances du modèle. D'autres gains de performances ont été réalisés en ciblant sélectivement l'étiquetage en fonction du tri par scores de confiance. Ce faisant, les experts médicaux se sont engagés dans un apprentissage actif non seulement en confirmant les prédictions avec des scores faibles, mais aussi en corrigeant les prédictions erronées avec des scores élevés.
À ce stade, les experts médicaux peuvent lancer un travail pour recycler le modèle en utilisant les étiquettes de données corrigées. Cette boucle label, formation, évaluation se poursuit jusqu'à ce que les experts médicaux soient satisfaits des performances de leur modèle. Les horodatages des événements de formation, les indicateurs de performance d'évaluation et d'autres informations sont enregistrées dans la base de données SQL Server pour une inspection et une auditabilité ultérieures.
Une fois la boucle étiqueter, former, évaluer terminée, un ensemble de prédictions de validation est sélectionné dans la base de données SQL Server à l'aide du générateur de nombres aléatoires intégré de SQL Server. Ces points de données ont été étiquetés par un panel d'experts médicaux ignorant les prédictions du modèle.
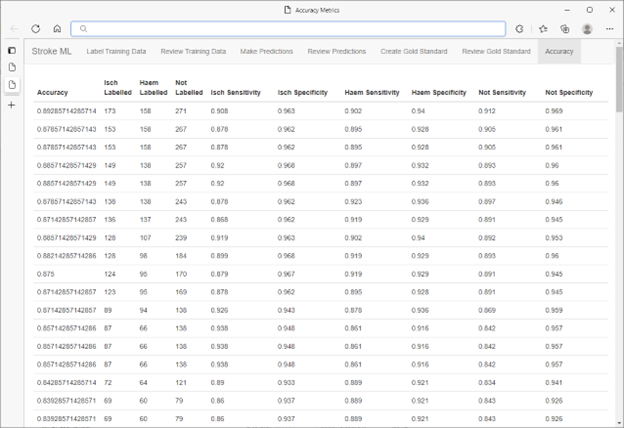
La précision résultante du modèle se situait entre le milieu et le haut des années 90. Ce résultat a donné aux chercheurs la confiance nécessaire pour utiliser les catégorisations produites par le modèle dans leurs recherches médicales en cours. La vitesse de ML.NET combinée au flux de travail HITL signifiait qu'il pouvait être répété pour différentes tâches de catégorisation et/ou différents ensembles de données de manière très efficace et rentable sans compromettre la précision.
Plans futurs
Le flux de travail Doctor-In-The-Loop développé par les chercheurs de HMRI s'avérera inestimable pour les recherches futures qui dépendent d'une catégorisation rapide et précise du texte libre médical.