

endlique les tâches simples à l’aide de ML.NET

Secteur
Technologies et services de l'information
Taille de l’organisation
Petite (1-100 employés)
Pays/région
Royaume-Uni
Technologie
Entreprise
Endjin est une entreprise de boutique, une société technologique et un partenaire Microsoft Gold pour la plateforme cloud, la plateforme de données, l’analytique de données et DevOps basé au Royaume-Uni. Endjin a un enthousiasme infectieux pour la puissance révolutionnaire de la technologie et permet à ses clients d’aider les clients à résoudre les problèmes matériels. Récemment, ils ont concentré sur l’utilisation de machine learning pour résoudre les problèmes d’entreprise banals, mais d’une valeur élevée. Cela a montré que la machine learning est idéale pour résoudre de nouveaux cas d’usage : sa capacité à révolutionner les tâches quotidiennes est souvent négligée.
Nous avons été étonnés de la facilité avec laquelle AutoML et ML.NET peuvent être utilisés pour réduire le temps passé sur des tâches chronophages et monotones. La liberté acquise grâce à l’utilisation de ces technologies accessibles et puissantes nous permet de consacrer notre temps à une analytique axée sur la pensée créative et l’obtention d’informations précieuses issues des données qu’ils produisent.\ »
Problème d’entreprise
En 2014, endjin a créé Azure Weekly, une newsletter gratuite qui résume les principales actualités de la semaine dans l'écosystème Azure. Pour les 25 premiers numéros, l'équipe d'endjin a organisé manuellement la newsletter, mais à mesure que le volume de contenu augmentait, ils ont réalisé que ce n'était pas durable. Ils ont appliqué le mantra de leur entreprise : "travaillez plus intelligemment" et automatisé le processus de bout en bout en créant leur propre classificateur de texte C# personnalisé pour classer les articles de plus de 300 blogs dans 19 catégories, y compris l'IA + l'apprentissage automatique, l'analyse, le DevOps, Internet des objets, réseaux et Web. Cela a relativement bien fonctionné, mais en plus de l'obligation de conserver une liste active de mots clés à classer, des corrections manuelles étaient nécessaires chaque semaine, ce qui entraînait d'importants frais de maintenance.
Plus de 200 numéros et plusieurs milliers d'abonnés plus tard, endjin a décidé de commencer à rechercher une solution d'apprentissage automatique. Ils savaient au cœur de la plate-forme de contenu qu'ils avaient deux problèmes principaux à résoudre : un problème de classification binaire ("est-ce un article sur Azure ?") et un problème de classification multiclasse ("quel domaine d'Azure cet article couverture?"). Ainsi, endjin a décidé d'utiliser ML.NET afin de résoudre ces problèmes, d'améliorer leur plate-forme et de supprimer les frais de maintenance manuelle.
Lorsque vous examinez le travail/les processus effectués par la plupart des organisations, vous pouvez les décomposer en une série d’étapes de décision d’une seconde. Si vous appliquez le machine learning, les workflows réactifs et l’économie des API dans le domaine des problèmes, nous commençons à entrer dans le cœur de ce que la 4e révolution industrielle pourrait apporter"
Pourquoi ML.NET ?
Bien que leur langage de programmation de prédilection soit C #, l'absence précédente d'un cadre d'apprentissage automatique de première classe pour .NET signifiait qu'endjin utilisait R et Python au quotidien pour ses clients confrontés à des expériences de science des données et de ML. Cependant, la production de modèles d'apprentissage automatique écrits en R et Python posait problème en raison des options d'hébergement limitées. Le reste de la plate-forme de contenu d'endjin est construit à l'aide de composants PaaS et Serverless, de sorte que la combinaison de ML.NET et Azure Functions était incroyablement attrayante pour l'entreprise ; dès que ML.NET a été annoncé lors de //build 2018, ils ont commencé à utiliser le framework d'apprentissage automatique pour leur application.
Impact de ML.NET et AutoML
Endjin a considérablement tiré parti des performances élevées de ML.NET, non seulement en termes d’amélioration de la vitesse lors de la classification des articles, mais également en termes de précision. Depuis l’adoption de ML.NET, ils ont vu beaucoup moins d’articles mal classés, ce qui se traduit par moins d’intervention manuelle et une production de contenu plus rapide.
L'utilisation de la CLI ML.NET avec AutoML a également rendu l'ensemble du processus de formation, d'évaluation et de génération du code pour utiliser ML.NET infaillible. L'utilisation d'AutoML pour choisir le modèle le plus performant et pour générer automatiquement le code d'entraînement et de consommation du modèle pour la classification (par rapport au choix manuel des transformations de données, des algorithmes et des options d'algorithme pour créer un modèle et un code ML.NET) a amélioré la précision du modèle de 68 % à 78 %, et l'exécution de ce modèle par rapport aux données historiques a non seulement mis en évidence de nombreux articles qui avaient été mal classés, mais a également identifié de nombreux articles valides qui avaient été exclus par le modèle de classification d'origine.
Architecture de la solution
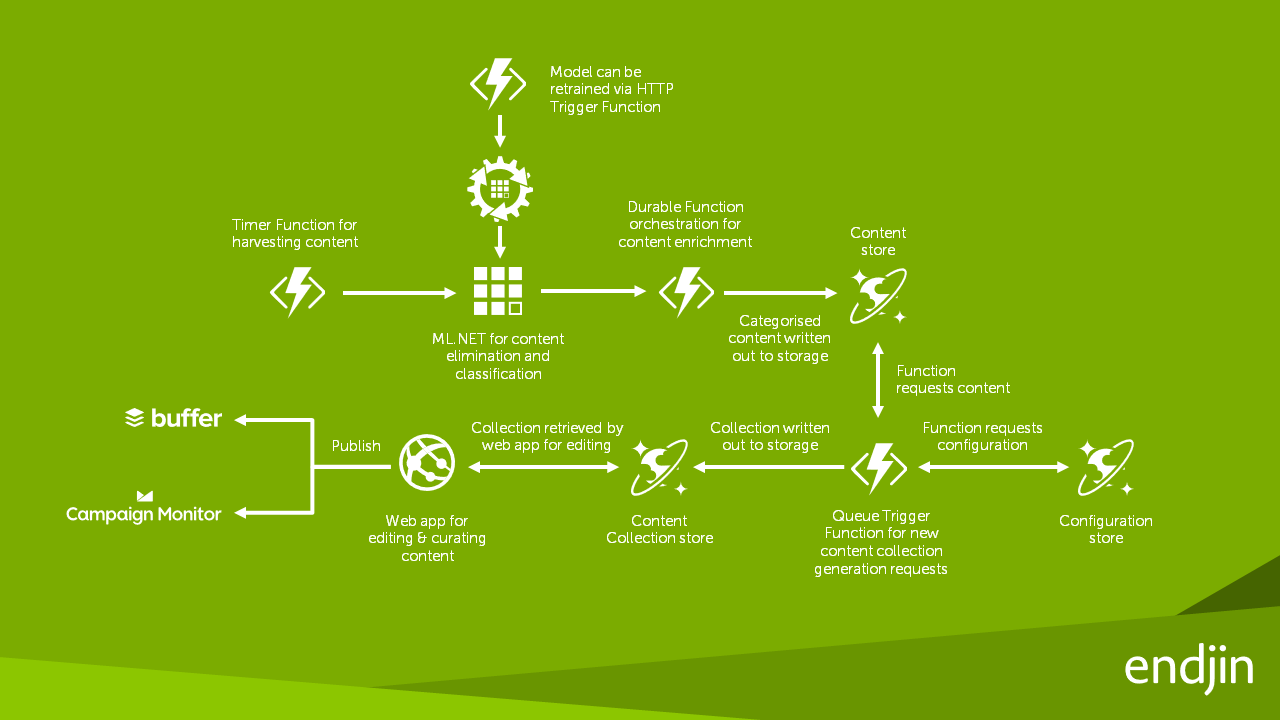
Création d’une application avec ML.NET
Lorsque endjin a commencé à utiliser ML.NET, ils ont créé un outil pour convertir les données historiques de la plate-forme de contenu en un ensemble de données CSV pour former manuellement un modèle ML.NET, et ils ont créé un autre outil pour sélectionner au hasard 20 % de l'ensemble de données de formation comme validation. base de données. Ils ont ensuite créé manuellement un modèle ML.NET pour prédire à quelle catégorie appartient un article.
Une fois que l'interface de programmation ML.NET avec AutoML a été disponible, elle a simplifié le processus et produit des résultats nettement meilleurs. Tout d'abord, AutoML a généré automatiquement un ensemble de données de validation à partir de l'ensemble de données d'entraînement, ce qui a rendu inutile le deuxième outil personnalisé d'endjin. Deuxièmement, en fixant une durée d'exploration maximale d'une heure, AutoML a pu entraîner, régler et évaluer plusieurs modèles de classification et afficher les 5 modèles les plus performants.
Une fois que endjin a obtenu les modèles ML.NET générés par AutoML, ils ont intégré les modèles à la plateforme de contenu existante, en remplaçant simplement les algorithmes de classification personnalisée existants. Les modèles ML.NET ont été hébergés dans une fonction Azure pour activer l’échelle élastique d’évaluation de modèles. Une nouvelle fonction durable a été utilisée pour permettre le réentraînement des modèles à la demande.
Traitement des données
Heureusement, l’équipe d'’endjin savait, lorsqu’elle a créé la version originale de la plateforme de contenu, qu’elle souhaiterait un jour l’améliorer à l'aide de l’apprentissage automatique. Elle a donc conservé toutes les données utilisées pour générer les bulletins d’information dans des formats bruts et traités (plus de 4 000 fichiers JSON d'une taille totale d’environ 3 Go). Ces données ont été transformées en deux ensembles de données d’entraînement : un fichier .CSV de 28 Mo pour la classification binaire et un fichier .CSV de 9 Mo pour la classification multiclasse.
Transformations de données et algorithmes d'apprentissage automatique
Comme le titre et le contenu des publications de blog classées sont des textes libres, vous devez les convertir à l’aide de la transformation de donnéesFeaturize Text. Le titre et le contenu ont ensuite été joints dans un champ unique à l’aide de la transformation de données Concaténer.
Le modèle d’origine que endjin a créé manuellement utilisait l’algorithme de classification multiclasse SdcaMaximumEntropy. Cependant, quand endjin utilisait l’interface CLI ML.NET avec AutoML, il a trouvé des modèles d’exécution plus importants pour leurs scénarios.
Pour le premier scénario ("est-ce un article sur Azure ?"), AutoML a sélectionné AveragedPerceptronBinary comme algorithme le plus performant. Pour le deuxième scénario ("quel domaine d'Azure cet article couvre-t-il ?"), AutoML a sélectionné LightGbmMulti comme algorithme le plus performant et a généré le code suivant pour entraîner le classifieur multiclasse :
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin a utilisé ML.NET pour améliorer son processus de sélection et de catégorisation d’articles pour leur bulletin d’informations Azure. L’utilisation de ML.NET et de AutoML pour générer des modèles machine learning a également permis à l’entreprise de se concentrer sur des paramètres de modèle à réglage fin et plus sur la fourniture de leur valeur métier.