

HMRI 已使用 ML.NET 為醫學研究建置「讓真人掌握最新資訊」ML 架構

產業
醫療保健
組織規模
大型 (1,000-9,999 位員工)
國家/地區
澳洲
技術
公司
Hunter Medical Research Institute (HMRI) 是一個旨在改善社區健康和福祉的組織。為了實現這一目標,它將科學家、臨床醫生和公共衛生專業人員匯集在一起,以快速追蹤全新且更好的衛生解決方案佈建。
Hunter Medical Research Institute (HMRI) 是一個旨在改善社區健康和福祉的組織。為了實現這一目標,它將科學家、臨床醫生和公共衛生專業人員匯集在一起,以快速追蹤全新且更好的衛生解決方案佈建。
若要了解該研究的詳細資訊,請參閱論文 "A method for rapid machine learning development for data mining with Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, Simon Quilty。
商務問題
醫療保健機構擁有大量資料。此資料通常採用非結構化文字格式。即使對其進行數位化,也往往難以從資料中擷取有意義且可採取動作的深入解析。正則運算式、SQL 查詢和「現成」自然語言處理軟體等技術僅取得有限的成功。
在此類情況下,機器學習可以幫助分析及擷取資料中有價值的資訊。機器學習工具以前用於對臨床筆記進行分類,以用於各種臨床和研究目的。但使用這些機器學習工具通常需要軟體開發或資料科學技能,而這往往超出了醫療專業人員的範圍。
即使在對模型進行訓練的案例中,如果模型處於非監督狀態,模型在真實世界中使用時也會取得次優結果。由於醫療決策承受高度的風險,醫療專業人員必須信任他們的模型,並且在模型出現錯誤時使用其專業知識提供意見反應。
這就是為什麼 HMRI 的研究人員使用 ML.NET 來開發 Human-In-The-Loop (HITL) 機器學習開發架構,讓醫療專業人員更輕鬆地標記資料、訓練模型,以及在不需要程式設計或機器學習體驗的情況下,使用這些模型推斷。更重要的是,他們建立了意見回饋機制,讓醫療專家可以將他們的技能和專業知識納入機器學習流程。因此,這種高層級監督在具有較少資料點的實際使用案例中獲得更好的結果。
為什麼要使用 ML.NET?
HMRI 使用 Model Builder 來開始使用 ML.NET。Model Builder 提供一種方式,可快速驗證是否可以使用機器學習來解決問題。一旦驗證了使用機器學習解決問題的成效,他們會利用 ML.NET 自動化機器學習 (AutoML) API。AutoML API ML.NET 自動選擇演算法,以及自訂 HITL 機器學習開發架構內的管線和超參數最佳化。
ML.NET 的影響
HMRI 使用 Model Builder 來開始使用 ML.NET。Model Builder 提供一種方式,可快速驗證是否可以使用機器學習來解決問題。一旦驗證了使用機器學習解決問題的成效,他們會利用 ML.NET 自動化機器學習 (AutoML) API。AutoML API ML.NET 自動選擇演算法,以及自訂 HITL 機器學習開發架構內的管線和超參數最佳化。
透過使用 ML.NET,HMRI 消除了將開發工作外包的需求,並且能夠使用現有技能和資源在內部建置所有內容。
此外,藉由將 ML.NET 作為解決方案的一部分加以利用,他們能夠為醫療專家提供介面,以訓練及使用不需要程式設計或機器學習體驗的機器學習模型。
解決方案架構
使用者互動的介面是一個 Web 應用程式,支援在模型訓練和使用階段中執行工作。
資料
針對初始實作,用於訓練模型的資料來自歷史醫療記錄。其中一個使用的資料集是包含大約 30,000 筆記錄的 40 年死亡率資料庫,另一個資料集則是包含約 13,000 筆記錄的航空醫學擷取資料集。
資料儲存在 SQL Server 資料庫中。在訓練之前,醫療專家使用 Web 應用程式將測試集標記為預先定義的類別,以在訓練循環期間計算準確度指標。然後,將使用一小組隨機選擇的資料進行第一輪訓練。
訓練、評估及使用量工作流程

該模型的訓練由醫療專家從 Web 應用程式觸發。伺服器端 ML.NET 程式碼將處理模型訓練和重新訓練。然後,模型將預測所有剩餘資料。預測和信賴度分數會儲存在 SQL Server 資料庫中。 SQL Server 儲存程序將用於針對測試集計算及儲存精確度計量。然後,這些計量將透過 Web 應用程式向醫療專家顯示。整個程序在幾秒鐘內即可完成。
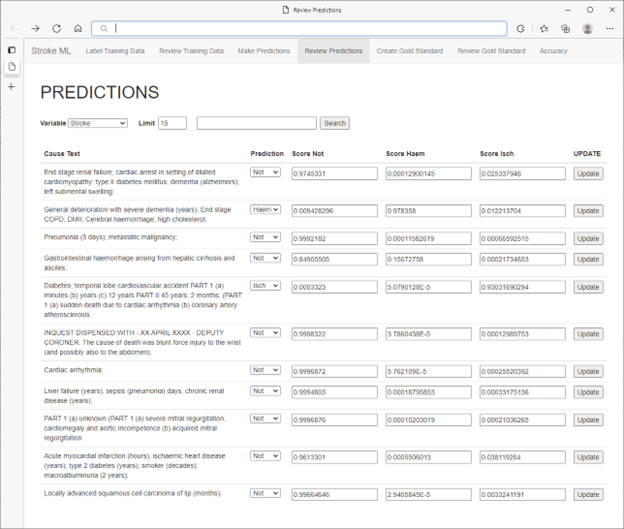
* 非實際病患資料
醫學專家發現,他們能夠直覺地使用重新叫用和特異性指標來指導如何選擇要標記的其他病例,從而最大程度地快速改善模型效能。透過根據信賴分數排序選擇性確定標記,可實現進一步的效能提升。在此過程中,醫學專家不僅可以借助低分確認預測,還可借助高分更改錯誤預測來進行主動學習。
此時,醫療專家可以啟動使用更正的資料標籤重新訓練模型的作業。在醫療專家對其模型效能感到滿意之前,此標籤、訓練、評估循環將一直持續下去。訓練事件時間戳記、評估計量和其他資訊將記錄到 SQL Server 資料庫,以便以後進行檢查及稽核。
在標記、訓練、評估循環完成後,使用 SQL Server 的內建亂數產生器從 SQL Server 資料庫中選取一組驗證預測。這些資料點已由一組對模型預測並不知情的醫學專家進行標記。
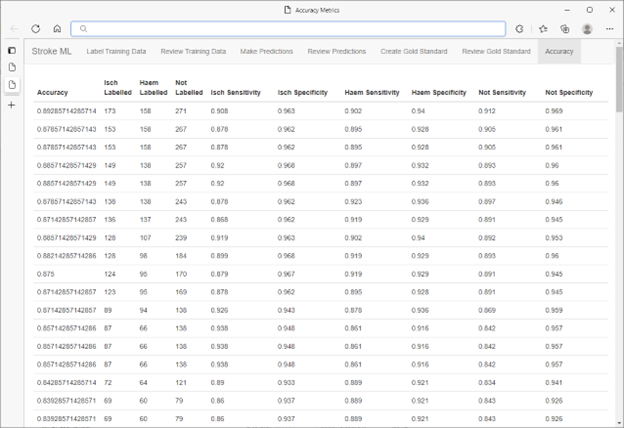
模型的結果正確性在 90 年代時為中到高。此結果使研究人員能夠放心地在其正在進行的醫學研究中使用該模型產生的分類。結合了 HITL 工作流程的 ML.NET 的速度表示能以高效率且具成本效益的方式將其重複用於不同的分類工作和/或不同的資料集,而不會對正確性造成影響。
未來計畫
對依賴快速和準確分類醫療自由文字的未來研究而言,由 HMRI 研究人員開發的「讓醫生掌握最新資訊」(Doctor-In-The-Loop) 工作流程將表現出重要價值。