

endjin 使用 ML.NET 來改革簡單的工作

產業
資訊技術與服務
組織規模
小型 (1-100 名員工)
國家/地區
英國
技術
公司
Endjin 是一家位於英國的精品公司、技術諮詢及適用於雲端平台、資料平台、資料分析及 DevOps 的 Microsoft 金級合作夥伴。Endjin 對技術的革命性力量以及利用這種力量幫助客戶解決難題充滿了滿腔熱情。他們近期已致力於使用機器學習來解決日常、但商務價值很高的問題。這表明,機器學習除了非常適合用來解決新穎的使用案例,我們也常忽略了它可以使簡單、日常工作產生變革的能力。
我們對於可以如此輕鬆使用 AutoML 與 ML.NET 來減少耗時與單調工作的花費時間而感到驚異。透過使用這些可存取及功能強大的技術,我們可以獲得空閒來將時間專注在創造思維導向的分析上,並從其所產生的資料獲取寶貴的深入解析。」
商務問題
在 2014 年,endjin 建立了 Azure Weekly,這是一份免費電子報,彙總了 Azure 生態系統中本週的熱門新聞。針對前 25 期,endjin 的小組手動策劃了該電子報,但隨著內容量增加,他們發現這不是長久之計。他們運用了公司管理「更聰明地工作」口號並將端對端程序自動化,方法是建立其自己自訂的 C# 文字分類器,將超過 300 個部落格的文章分類為 19 個類別,包括 AI + 機器學習、Analytics、DevOps、物聯網、網路和 Web。此作法運作相當好,但除了需要保留要分類的作用中關鍵字清單之外,每週還需要手動修正,這導致主要的維護負荷。
出現 200 個以上的問題和數千名訂閱者之後,endjin 因此決定開始研究機器學習解決方案。他們知道在內容平台的核心有兩個關鍵問題需要解決 - 二進位分類問題 (\「這是否為關於 Azure 的文章?\」) 和 multiclass 分類問題 (\「這篇文章會介紹 Azure 的哪個領域?\」)。因此,endjin 決定使用 ML.NET 來解決這些問題、改善其平台,並免除手動維護的開銷。
當您查看大部分組織所執行的工作/程式時,您可以將它們分成一系列的 1 秒決策步驟。如果您將機器學習、反應性工作流程及 API 經濟性應用於問題空間,我們將開始觸及第四次工業革命可提供的核心內容」
為什麼要使用 ML.NET?
儘管其選擇的程式設計語言是 C#,但之前缺少適用於 .NET 的第一類別機器學習架構即表示,endjin 已在日常和客戶互動的資料科學和 ML 實驗中使用 R 和 Python。然而,由於裝載選項有限,因此生產在 R 和 Python 中撰寫的機器學習模型時出現問題。Endjin 之內容平台的其餘部分是使用 PaaS 及無伺服器元件建置的,所以 ML.NET 與 Azure Functions 的結合對公司極具吸引力; 在 Build2018 大會上宣佈 ML.NET 後,即刻就開始在其應用程式中使用該機器學習架構。
ML.NET 與 AutoML 的影響
Endjin 已大幅受益於 ML.NET 的高效能,而且不僅分類文章的速度變快,正確性也有所提升。自從採用 ML.NET 以來,他們已較少發現分類錯誤的文章,這意味著減少手動操作,以及加快內容製作速度。
將 ML.NET CLI 和 AutoML 搭配使用還可讓訓練、評估及產生程式碼來使用 ML.NET 的整個流程更萬無一失。使用 AutoML 選擇最佳執行模式,並自動產生分類的模型定型和耗用代碼 (相較於手動選擇資料轉換、演算法和演算法選項來建立 ML.NET 模型和程式碼) 可將模型正確性從 68% 提高到 78%,而根據歷程記錄的資料執行此模型不僅可特別標示出許多錯誤分類的文章,而且也可識別出許多已由原始分類模型排除的有效文章。
解決方案架構
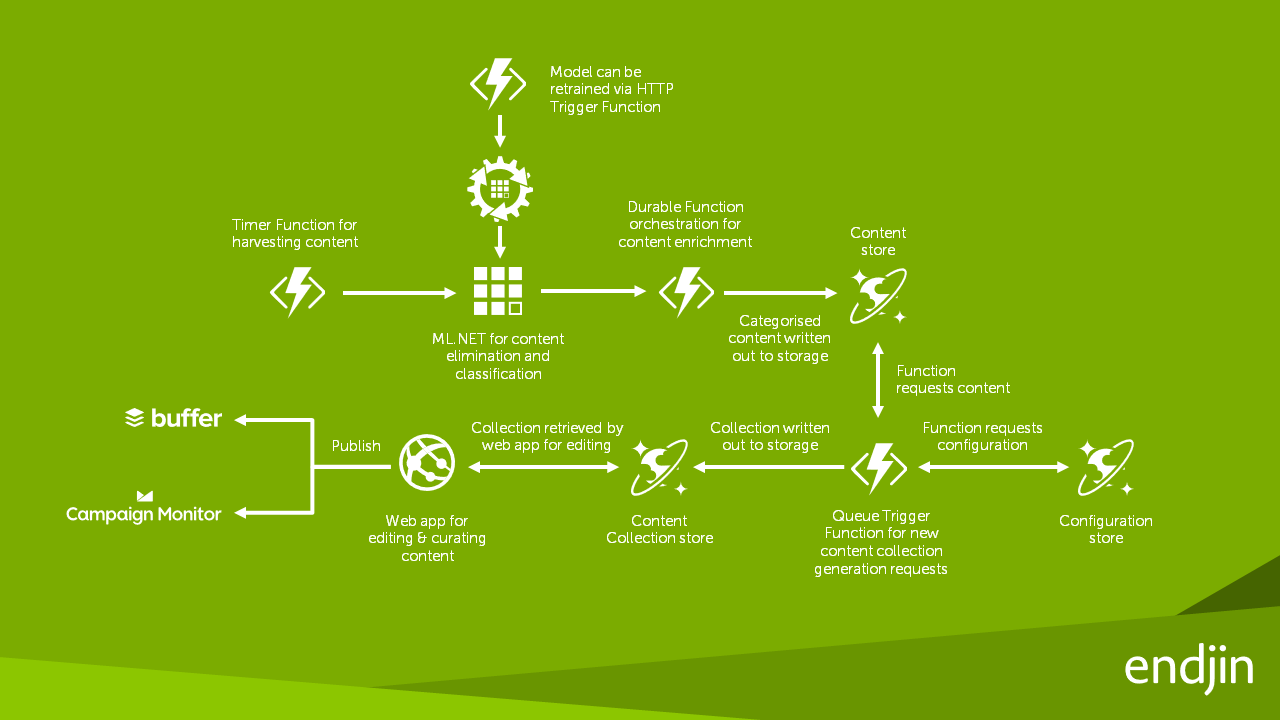
正在使用 ML.NET 建立應用程式
當 endjin 第一次使用 ML.NET 時,它們已建立可將歷史內容平台資料轉換為 CSV 資料集的工具,以手動訓練 ML.NET 模型,它們還建立了另一工具,可隨機選取 20% 的訓練資料集做為驗證資料集。接下來還手動建立了 ML.NET 模型,用來預測發行項所屬的類別。
一旦 ML.NET CLI with AutoML 可供使用,其會簡化程序並產生明顯更好的結果。首先,AutoML 會自動從定型資料集產生驗證資料集,因此不再需要 endjin 的第二個自訂工具。其次,將最大探索時間設定為一小時,使得 AutoML 可以定型、調整及評估多個分類模型,並顯示前 5 大執行中的模型。
一旦 endjin 有 AutoML 產生的定型 ML.NET 模型,他們只要交換出現有的自訂分類演算法,就能將模型整合至現有的內容平台。這些 ML.NET 模型是託管於 Azure 函式內,以啟用模型評估的彈性擴增。新的 Durable Function 是用來允許視需求對模型重新定型。
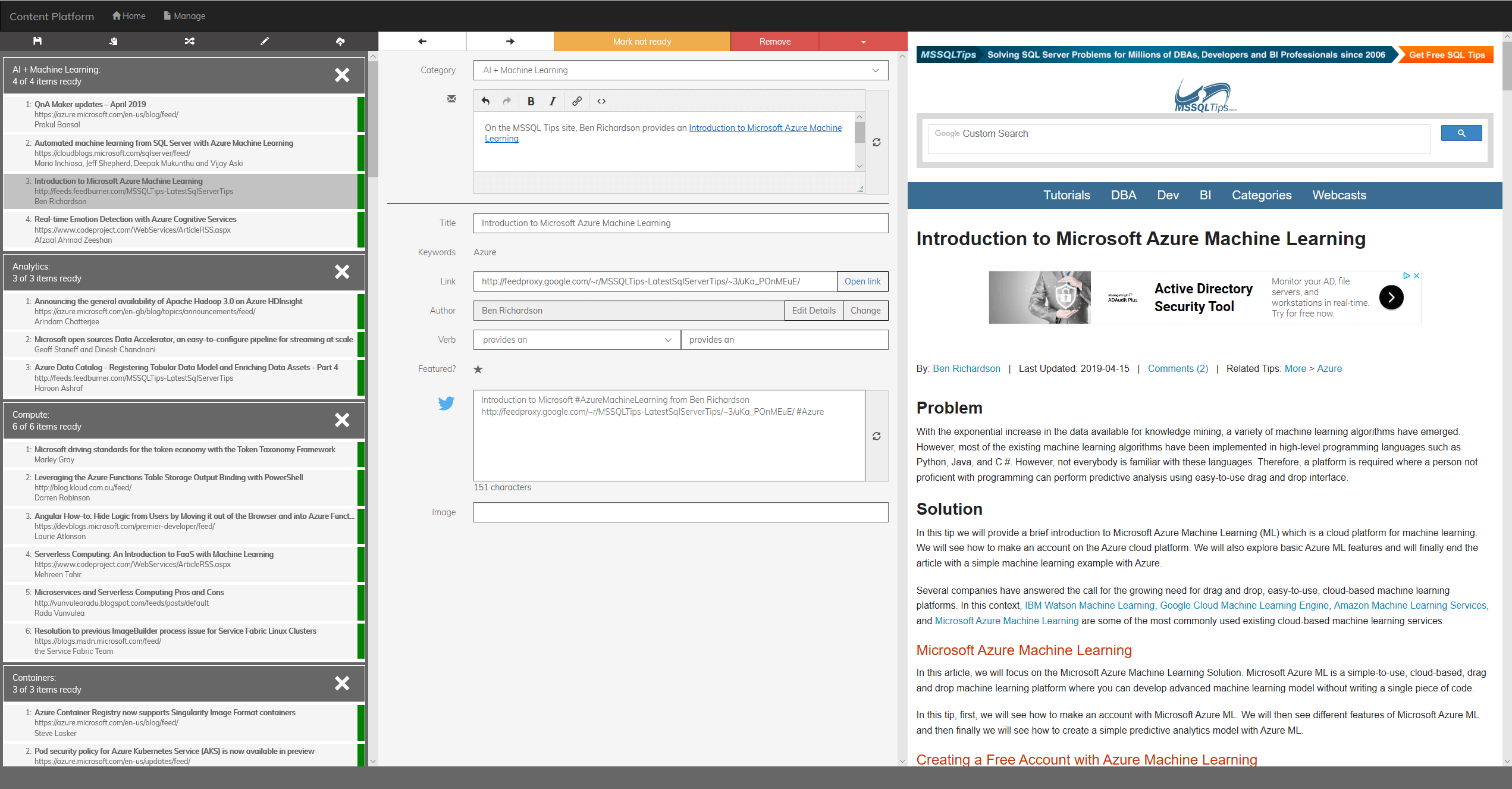
資料處理
幸好,endjin 的小組知道建置原始版本的內容平台之後,有一天他們會想要使用機器學習來改善它,因此他們保留所有用來產生電子報的原始和已處理的格式資料 (超過 4,000 個 JSON 檔案,總大小約 3 GB)。這些已轉換為兩個定型資料集: 一個 28 MB 的 CSV 檔案用於二進位分類,以及一個 9 MB 的 CSV 檔案用於多重類別分類。
資料轉換和機器學習演算法
由於分類的部落格文章標題和內容是任意文字,因此兩者都需要使用 Featurize Text 資料轉換進行轉換。接著再使用 Concatenate 資料轉換,將標題和內容結合成單一欄位。
Endjin 手動建立的原始模型已使用 SdcaMaximumEntropy 多類別分類演算法。不過,當 endjin 結合使用 ML.NET CLI 和 AutoML 時,他們有發現其情節的效能模型更高。
針對第一個案例 (「這是關於 Azure 的文章嗎?」),AutoML 已選取 AveragedPerceptronBinary 做為最佳執行演算法。針對第二個案例 (「本文涵蓋哪個 Azure 區域?」),AutoML 已選取 LightGbmMulti 做為最高執行演算法,並已產生下列程式碼來訓練多類別分類器:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin 已使用 ML.NET 改善為其 Azure 電子報選取及分類文章的流程。使用 ML.NET 及 AutoML 來產生機器學習模型,也允許公司將精力集中在微調模型參數上,以及提供其商務價值。