

SigParser는 ML.NET을 사용하여 "사람이 아닌" 전자 메일을 검색합니다.

업계
소프트웨어/통신
조직 규모
소규모(직원 1~49명)
국가/지역
미국
기술
회사
SigParser는 고객 관계 관리(CRM) 시스템을 추가하고 유지하는 번거로운(종종 비용이 많이 드는) 프로세스를 자동화하는 API 및 서비스입니다. SigParser는 전자 메일 서명에서 이름, 전자 메일 주소 및 전화 번호와 같은 연락처 정보를 추출하고 모든 정보를 CRM 시스템 또는 데이터베이스에 연락처로 공급합니다.
비즈니스 문제
SigParser가 회사에 대한 전자 메일을 처리할 때 많은 전자 메일은 비사용자 전자 메일입니다(예: 뉴스레터, 결제 알림, 암호 재설정 등). 이러한 유형의 전자 메일에서 보낸 사람의 정보는 연락처 목록에 표시되거나 CRM 시스템으로 푸시되어서는 안 됩니다. 따라서 SigParser는 기계 학습을 사용하여 전자 메일 메시지가 "스팸으로 보이는지"를 예측하기로 결정했습니다.
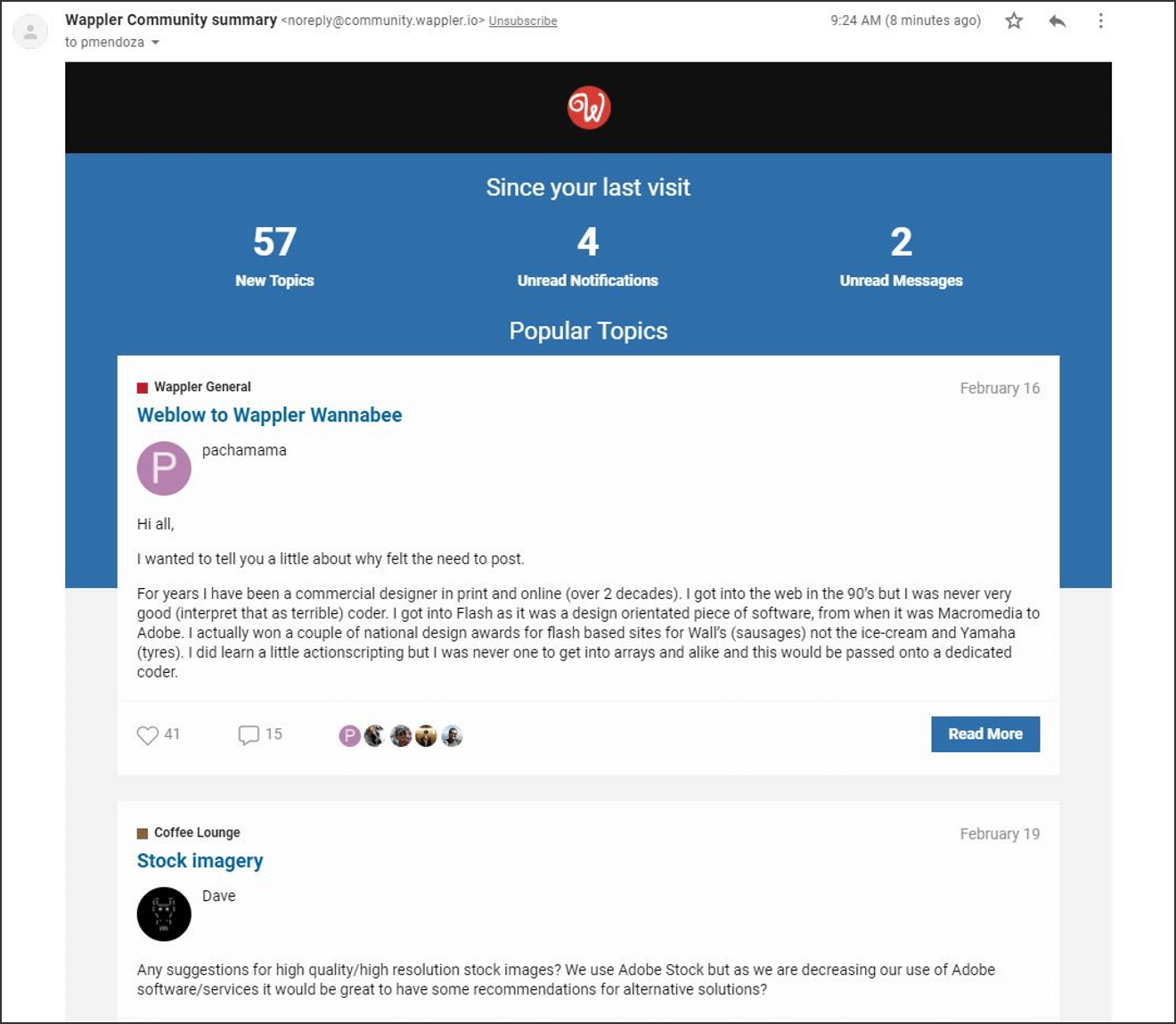
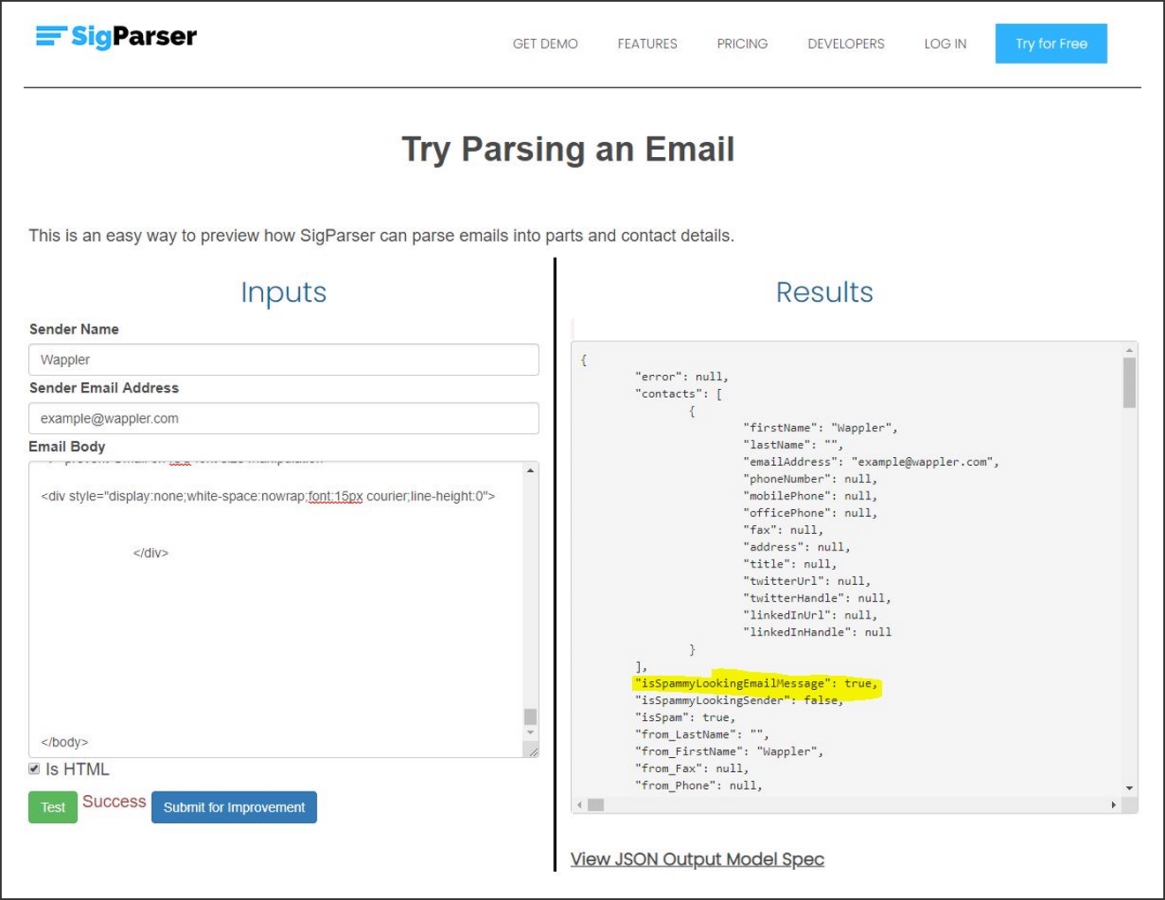
포럼에서 다음 알림 전자 메일을 예제로 사용하세요. 이 전자 메일의 보낸 사람이 CRM에 표시되어야 하는 연락처가 아니므로 기계 학습 모델은 "isSptadataLookingEmailMessage"가 true임을 예측합니다.
왜 ML.NET를 사용해야 하나요?
SigParser의 팀이 기계 학습을 활용하기로 결정했을 때 원래 R을 사용하려고 했습니다. 그러나 .NET Core를 사용하여 빌드된 API를 유지 관리하고 통합하기가 매우 어렵다는 것을 알게되었습니다.
SigParser의 CEO이자 설립자인 Paul Mendoza는 R"이 개발 프로세스와 너무 단절되어 있다고 말했습니다. R을 사용하면 모든 상수가 생성된 다음 해당 상수들을 복사하여 .NET에 붙여넣은 다음, 실제 모델을 사용해 보았고 제대로 작동하지 않아서 반복해야 했습니다. 이 과정이 너무 느렸습니다."
따라서 그들은 모든 것을 하나의 애플리케이션으로 가져오기 위해 ML.NET으로 눈을 돌렸습니다.
ML.NET을 사용하면 모델을 훈련시킨 다음 코드 내에서 즉시 테스트할 수 있습니다. 모든 도구가 한 곳에 함께 있기 때문에 새로운 변경 사항을 더 빨리 전달할 수 있습니다."
ML.NET의 영향
R에서 ML.NET으로 전환하면 생산성이 10배 향상됩니다. 또한 SigParser가 R로 이동할 때까지 하나의 기계 학습 모델만 활용했습니다. ML.NET으로 전환한 이후로 이메일 구문 분석의 다양한 측면을 위한 6개의 기계 학습 모델을 갖게 되었습니다. 이러한 증가는 이제 ML.NET을 통해 새로운 기계 학습 아이디어를 신속하게 실험하고 애플리케이션에 결과를 신속하게 표시할 수 있기 때문에 가능합니다.
솔루션 아키텍처
데이터 처리
SigParser는 먼저 잘 알려진 Enron 데이터 세트를 사용하여 모델을 학습시키는 데 사용했지만, 너무 오래되었다는 것을 알게 되면 자체 전자 메일 계정(GDPR 준수 유지)에 몇 천 개의 전자 메일을 사람 또는 사람이 아닌 것으로 레이블을 지정하고 이를 학습 데이터 세트로 사용했습니다.
기계 학습 기능
SigParser의 ML.NET 모델에는 두 개의 기능이 있습니다("IsHumanE-mail"을 예측하는 데 사용됨).
HasUnsubscribes—이메일 본문에 "unsubscribe" 또는 "opt out"이 있는 경우 TrueEmailBodyCleaned—HTML 이메일 본문을 표준화하여 이메일 언어를 불가지론적으로 만들고 개인 식별 정보를 제거합니다.
기계 학습 알고리즘
이러한 두 기능은 분류 시나리오에 대한 알고리즘인 이진 FastTree 알고리즘에 입력되며, 출력은 전자 메일이 "실제 사람"에서 전송되었는지 또는 자동화된 원본에서 전송되었는지를 예측합니다. 현재 SigParser는 이 ML.NET 모델로 매월 수백만 개의 전자 메일을 처리하고 있습니다.
var mlContext = new MLContext();
var(trainData, testData) = mlContext.BinaryClassification.TrainTestSplit(mlContext.CreateStreamingDataView(totalSampleSet), testFraction:0.2);
var pipeline = mlContext.Transforms.Text.FeaturizeText("EmailBodyCleaned", "EmailHTMLFeaturized")
.Append(mlContext.Transforms.Concatenate("Features", "HasUnsubscribes", "EmailHTMLFeaturized"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumn: "IsHumanEmail", featureColumn: "Features"));
Console.WriteLine("Fitting data");
var fitResult = pipeline.Fit(trainData);
Console.WriteLine("Evaluating metrics");
var metrics = mlContext.BinaryClassification.Evaluate(fitResult.Transform(testData), label: "IsHumanEmail");
Console.WriteLine("Accuracy: " + metrics.Accuracy);
using (var stream = File.Create(emailParsingPath + "EmailHTMLTypeClassifier.zip"))
{
mlContext.Model.Save(fitResult, stream);
}
SigParser는 위에서 언급한 스팸 검색 모델을 포함하여 여러 기계 학습 솔루션에 대해 ML.NET의 데이터 변환 및 알고리즘을 사용하며, 이를 통해 전자 메일 서명에서 고객 데이터베이스로 올바른 연락처 정보를 자동으로 내보낼 수 있으므로 시간이 오래 걸리고 오류가 발생하기 쉬운 수동 연락처 데이터 입력이 필요하지 않습니다.