

endjin은 ML.NET으로 간단한 작업을 혁신합니다.

업계
정보 기술 및 서비스
조직 규모
소규모(직원 1~100명)
국가/지역
영국
기술
회사
Endjin은 영국에 기반을 둔 부티크 비즈니스, 기술 컨설팅 및 클라우드 플랫폼, 데이터 플랫폼, 데이터 분석 및 DevOps를 위한 Microsoft 골드 파트너입니다. Endjin은 기술의 혁명적인 힘과 그 힘을 활용하여 고객이 어려운 문제를 해결할 수 있도록 하는 데 열정을 가지고 있습니다. 최근에는 기계 학습을 사용하여 평범하지만 가치가 높은 비즈니스 문제를 해결하는 데 집중하고 있습니다. 이는 기계 학습은 참신한 사용 사례를 해결하는 데는 뛰어나지만, 단순하고 일상적인 작업을 혁신하는 데 있어서는 종종 능력이 간과된다는 것을 보여줍니다.
시간이 오래 걸리고 단조로운 작업에 드는 시간을 줄이기 위해 AutoML 및 ML.NET을 쉽게 사용할 수 있다는 것에 놀랐습니다. 이러한 액세스 가능하고 강력한 기술을 사용하여 얻은 자유는 창의적인 사고 주도 분석과 이들이 생성하는 데이터에서 중요한 인사이트를 얻는 데 집중할 수 있게 해줍니다."
비즈니스 문제
2014년에 endjin은 Azure 에코시스템의 금주의 주요 뉴스를 요약한 무료 뉴스레터인 Azure Weekly를 만들었습니다. 처음 25개 문제의 경우 endjin 팀에서 수동으로 뉴스레터를 선별했지만 콘텐츠의 양이 늘어남에 따라 이것이 지속 가능하지 않다는 것을 깨달았습니다. 그들은 "더 똑똑하게"라는 회사의 만트라를 적용하고 300개가 넘는 블로그의 기사들을 AI + Machine Learning, Analytics, DevOps, 사물 인터넷, 네트워킹 및 웹을 포함한 19개의 범주로 분류하는 자체적인 사용자 지정 C# 텍스트 분류기를 개발하여 엔드 투 엔드 프로세스를 자동화했습니다. 이것은 비교적 잘 작동했지만 분류할 키워드 목록을 유지해야 한다는 요구 사항 외에도 매주 수동 수정이 필요했으며 이로 인해 유지 관리 오버헤드가 많이 발생했습니다.
200개 이상의 문제와 수천 명의 구독자가 발생한 후 endjin은 기계 학습 솔루션을 찾기 시작했습니다. 그들은 콘텐츠 플랫폼의 핵심에서 해결해야 할 두 가지 핵심 문제가 있음을 알고 있었습니다. 이진 분류 문제("이 문서는 Azure에 대한 문서입니까?")와 다중 클래스 분류 문제("Azure의 어느 영역에서 이 문서를 수행합니까? 씌우다?"). 따라서 endjin은 이러한 문제를 해결하고 플랫폼을 개선하며 수동 유지 관리 오버헤드를 제거하기 위해 ML.NET을 사용하기로 결정했습니다.
대부분의 조직에서 수행하는 작업/프로세스를 살펴보면 일련의 1초 의사 결정 단계로 세분화할 수 있습니다. 기계 학습, 반응 워크플로 및 API 경제성을 문제 공간에 적용하면 4번째 산업 혁신이 제공할 수 있는 핵심에 도달하게 됩니다.
왜 ML.NET를 사용해야 하나요?
선택한 프로그래밍 언어는 C#이지만 이전에는 .NET용 일류 기계 학습 프레임워크가 없었기 때문에 endjin은 데이터 과학 및 ML 실험에 직면한 일상적인 고객에게 R 및 Python을 사용하고 있었습니다. 그러나 R과 Python으로 작성된 기계 학습 모델을 생산하는 것은 제한된 호스팅 옵션으로 인해 문제가 있었습니다. endjin의 나머지 콘텐츠 플랫폼은 PaaS 및 Serverless 구성 요소를 사용하여 구축되므로 ML.NET과 Azure Functions의 조합이 회사에 매우 매력적이었습니다. //build 2018에서 ML.NET이 발표되자마자 그들은 앱에 기계 학습 프레임워크를 사용하기 시작했습니다.
ML.NET 및 AutoML의 영향
Endjin은 ML.NET의 고성능 덕분에 기사 분류 시 속도 향상뿐 아니라 정확도 면에서도 큰 이점을 얻었습니다. ML.NET을 채택한 이후로 잘못 분류된 기사가 훨씬 줄어들어 수동 개입이 줄어들고 콘텐츠 제작이 빨라집니다.
AutoML과 함께 ML.NET CLI를 사용하면 ML.NET을 사용하기 위한 코드를 교육, 평가 및 생성하는 전체 프로세스도 쉽게 수행할 수 있습니다. AutoML을 사용하여 최고의 성능 모델을 선택하고 분류를 위한 모델 학습 및 소비 코드를 자동으로 생성하면(ML.NET 모델 및 코드를 생성하기 위해 데이터 변환, 알고리즘 및 알고리즘 옵션을 수동으로 선택하는 것과 비교하여) 모델 정확도가 68%에서 78%로 향상되었습니다. 과거 데이터에 대해 이 모델을 실행하면 잘못 분류된 많은 기사가 강조 표시되었을 뿐만 아니라 원래 분류 모델에서 제외되었던 많은 유효한 기사도 식별되었습니다.
솔루션 아키텍처
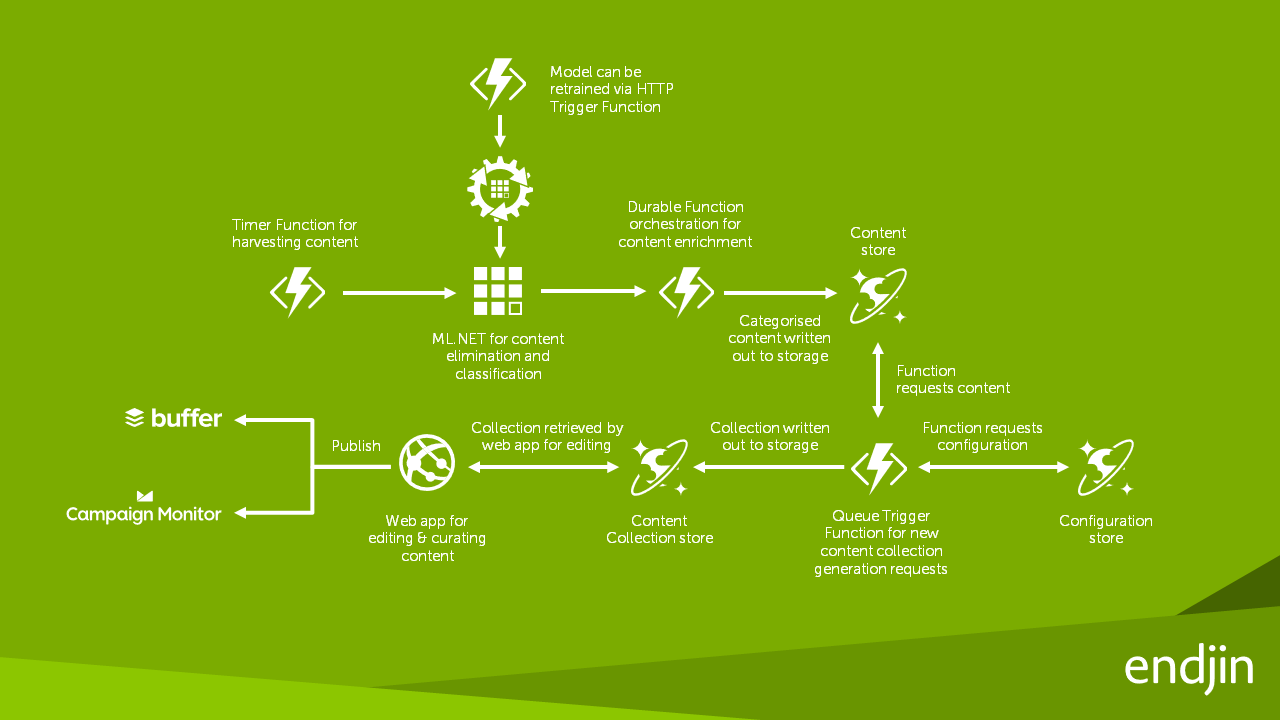
ML.NET을 사용하여 애플리케이션 만들기
endjin은 ML.NET을 처음 사용하기 시작할 때 기록 콘텐츠 플랫폼 데이터를 CSV 데이터 세트로 변환하여 ML.NET 모델을 수동으로 학습시키는 도구를 만들고, 학습 데이터 세트의 20%를 유효성 검사 데이터 세트로 임의로 선택하는 다른 도구를 만들었습니다. 그런 다음 ML.NET 모델을 수동으로 만들어 기사가 속한 범주를 예측했습니다.
AutoML이 포함된 ML.NET CLI를 사용할 수 있게 되면 프로세스가 간소화되고 훨씬 더 나은 결과가 생성됩니다. 첫째, AutoML은 훈련 데이터 세트에서 검증 데이터 세트를 자동으로 생성하므로 endjin의 두 번째 사용자 지정 도구가 더 이상 필요하지 않았습니다. 둘째, 최대 탐색 시간을 1시간으로 설정하면 AutoML이 여러 분류 모델을 훈련, 조정 및 평가하고 상위 5개 성능 모델을 표시할 수 있습니다.
endjin은 AutoML에 의해 생성된 훈련된 ML.NET 모델을 갖고 나면 기존 사용자 지정 분류 알고리즘을 교체하기만 하면 기존 콘텐츠 플랫폼에 모델을 통합했습니다. ML.NET 모델은 모델 평가의 탄력적 확장을 가능하게 하기 위해 Azure Function 내에서 호스팅되었습니다. 새로운 내구성 기능을 사용하여 요청 시 모델을 재학습할 수 있습니다.
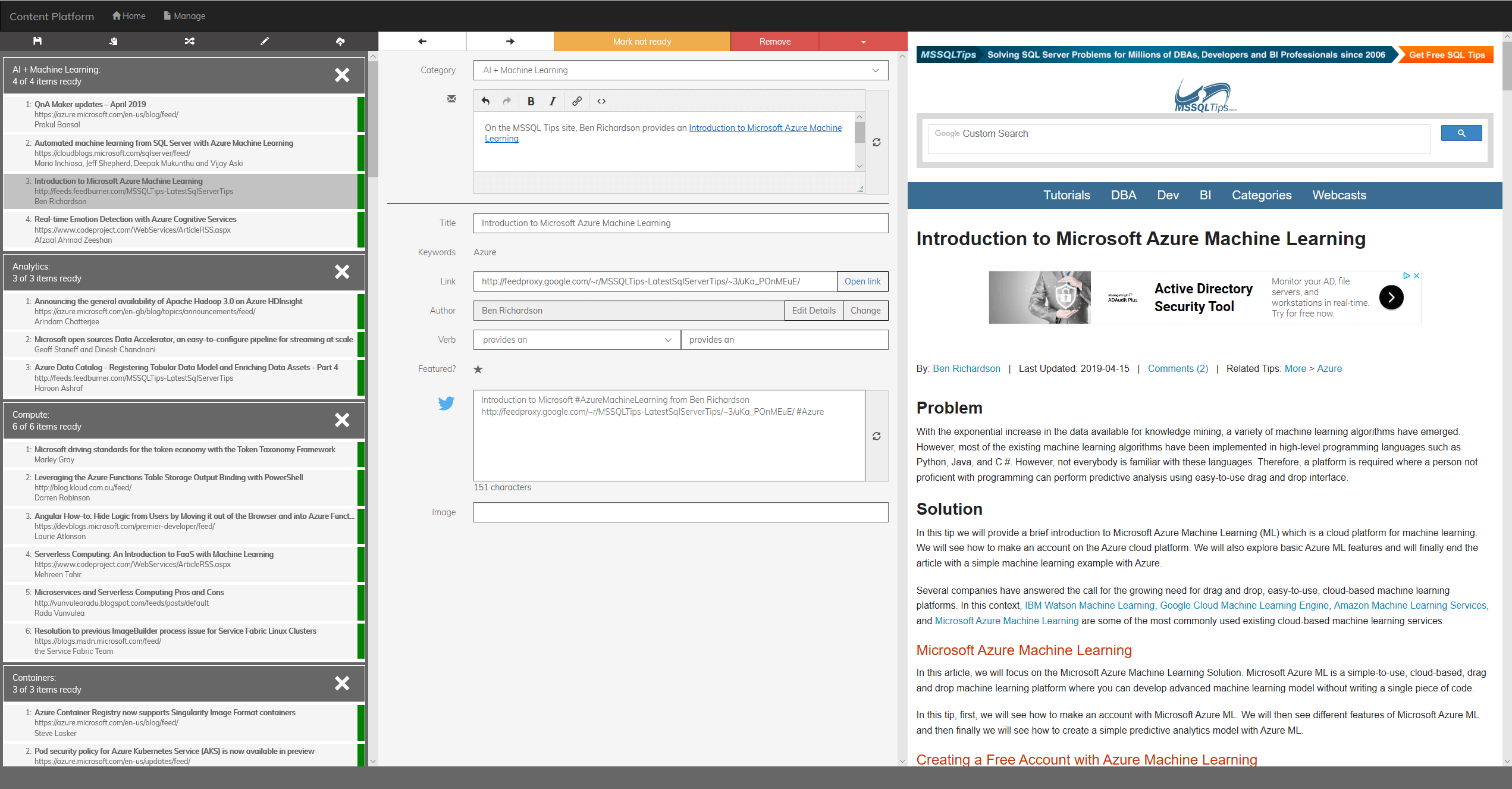
데이터 처리
다행스럽게도 endjin 팀은 콘텐츠 플랫폼의 원본 버전을 구축할 때 언젠가는 기계 학습을 사용하여 개선하고 싶다는 것을 알았고 뉴스레터를 생성하는 데 사용된 모든 데이터를 원시 형식과 처리 형식(총 크기가 약 3GB인 JSON 파일 4,000개 이상)으로 유지했습니다. 이 데이터 세트는 이진 분류를 위한 28MB .CSV 파일과 다중 클래스 분류를 위한 9MB .CSV 파일의 두 가지 교육 데이터 세트로 변환되었습니다.
데이터 변환 및 기계 학습 알고리즘
분류되는 블로그 게시물의 제목과 콘텐츠는 자유 텍스트이므로 Featureize Text 데이터 변환을 사용하여 둘 다 변환해야 합니다. 그런 다음 연결 데이터 변환을 사용하여 제목과 내용을 단일 필드로 결합했습니다.
endjin이 수동으로 생성한 원래 모델은 SdcaMaximumEntropy 다중 클래스 분류 알고리즘을 사용했습니다. 그러나 endjin이 AutoML과 함께 ML.NET CLI를 사용했을 때 시나리오에 대해 훨씬 더 높은 성능의 모델을 발견했습니다.
첫 번째 시나리오("Azure에 대한 문서인가요?") AutoML이 최적의 성능 알고리즘으로 AveragedPerceptronBinary를 선택했습니다. 두 번째 시나리오("이 아티클에서 다루는 영역은 무엇인가요?") AutoML이 LightGbmMulti를 최고 성능 알고리즘으로 선택하고 다음 코드를 생성하여 다중 클래스 분류자를 학습시킵니다.
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin은 ML.NET을 사용하여 Azure 뉴스레터에 대한 기사를 선택하고 분류하는 프로세스를 개선했습니다. ML.NET 및 AutoML을 사용하여 기계 학습 모델을 생성함으로써 회사는 모델 매개 변수를 미세 조정하는 대신 비즈니스 가치를 제공하는 데 더 집중할 수 있었습니다.