

SigParser usa ML.NET per rilevare i messaggi di posta elettronica "non umani"

Settore
Software/Telecomunicazioni
Dimensioni dell'organizzazione
Piccole dimensioni (1-49 dipendenti)
Paese/area geografica
Stati Uniti
Tecnologia
Azienda
SigParser è un'API e un servizio che automatizza il processo noioso (e spesso costoso) di aggiunta e manutenzione dei sistemi CRM (Customer Relationship Management). SigParser estrae le informazioni di contatto, ad esempio nomi, indirizzi di posta elettronica e numeri di telefono, dalle firme di posta elettronica e invia tutte le informazioni come contatti nei sistemi o nei database CRM.
Problema aziendale
Quando SigParser elabora i messaggi di posta elettronica per un'azienda, molti messaggi non sono umani, ad esempio newsletter, notifiche di pagamento, reimpostazioni delle password e così via. Le informazioni del mittente da questi tipi di messaggi di posta elettronica non devono essere visualizzate negli elenchi di contatti o non devono essere inserite in un sistema CRM. SigParser ha quindi deciso di usare l'apprendimento automatico per prevedere se i messaggi di posta elettronica sono "apparentemente posta indesiderata."
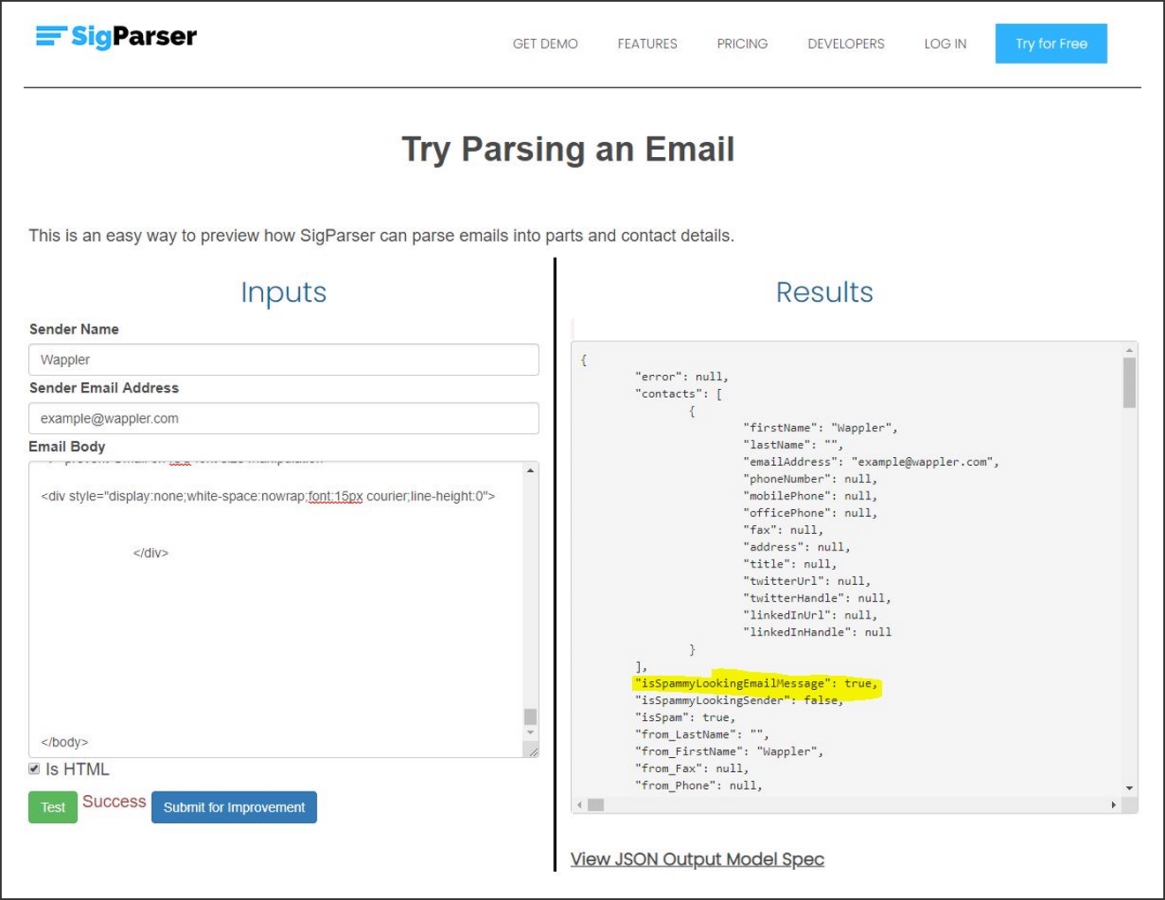
Come esempio, prendere il messaggio di posta elettronica di notifica seguente da un forum. Il mittente di questo messaggio di posta elettronica non è un contatto che dovrebbe essere visualizzato in un CRM, quindi un modello di Machine Learning prevede che "isSpammyLookingEmailMessage" sia true:
Perché ML.NET?
Quando il team di SigParser ha deciso di usare l'apprendimento automatico, ha originariamente provato a usare R. La manutenzione e l'integrazione con la rispettiva API; creata con .NET Core, sono tuttavia risultate molto difficili.
Paul Mendoza, CEO e fondatore di SigParser, ha dichiarato che R "era semplicemente troppo disconnesso dal processo di sviluppo. Con R dovevamo generare tutte le costanti e quindi copiarle e incollarle in .NET e infine dovevamo provare il modello in uno scenario concreto e scoprire che non funzionava effettivamente e che era necessario ripetere il processo. Era un approccio troppo lento."
Si sono quindi rivolti a ML.NET per portare tutto in un'unica applicazione.
Grazie a ML.NET, è possibile eseguire il training del modello e quindi eseguirne immediatamente il test all'interno del codice. Questo approccio consente di distribuire nuove modifiche più rapidamente perché tutti gli strumenti si trovano in un'unica posizione."
Impatto di ML.NET
L'impatto del passaggio a ML.NET da R ha comportato un miglioramento della produttività di 10 volte. Inoltre, fino a quando SigParser non è passato a R, ha utilizzato un solo modello di apprendimento automatico. A partire dalla conversione a ML.NET, ora dispongono di 6 modelli di apprendimento automatico per diversi aspetti della posta elettronica. Questo incremento è dovuto al fatto che, grazie a ML.NET, è ora possibile sperimentare rapidamente nuove idee di apprendimento automatico e mostrarne rapidamente i risultati nell'applicazione.
Architettura della soluzione
Elaborazione dati
In SigParser è stato usato prima di tutto il noto set di dati Enron per eseguire il training del modello, ma quando è risultato evidente che era piuttosto obsoleto, si è scelto di etichettare un paio di migliaia di messaggi di posta elettronica nei rispettivi account di posta elettronica (in conformità con il GDPR) come umano o non umano e usare queste informazioni come set di dati di training.
Funzionalità di Machine Learning
Il modello di ML.NET di SigParser ha due funzionalità (usate per eseguire la stima "IsThemE-mail"):
HasUnsubscribes—True se un messaggio di posta elettronica contiene "annulla sottoscrizione" o "rifiuto esplicito" nel corpo del messaggio di posta elettronicaEmailBodyCleaned—Normalizza il corpo del messaggio di posta elettronica HTML per rendere indipendente il linguaggio di posta elettronica e rimuovere eventuali informazioni personali
Algoritmo di Machine Learning
Queste due funzionalità vengono inserite in un algoritmo Binary FastTree, che è un algoritmo per scenari di classificazione. L'output è la previsione che indica se il messaggio di posta elettronica è stato inviato da un "essere umano reale" o da un'origine automatizzata. SigParser sta attualmente elaborando milioni di messaggi di posta elettronica al mese con questo modello di ML.NET.
var mlContext = new MLContext();
var(trainData, testData) = mlContext.BinaryClassification.TrainTestSplit(mlContext.CreateStreamingDataView(totalSampleSet), testFraction:0.2);
var pipeline = mlContext.Transforms.Text.FeaturizeText("EmailBodyCleaned", "EmailHTMLFeaturized")
.Append(mlContext.Transforms.Concatenate("Features", "HasUnsubscribes", "EmailHTMLFeaturized"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumn: "IsHumanEmail", featureColumn: "Features"));
Console.WriteLine("Fitting data");
var fitResult = pipeline.Fit(trainData);
Console.WriteLine("Evaluating metrics");
var metrics = mlContext.BinaryClassification.Evaluate(fitResult.Transform(testData), label: "IsHumanEmail");
Console.WriteLine("Accuracy: " + metrics.Accuracy);
using (var stream = File.Create(emailParsingPath + "EmailHTMLTypeClassifier.zip"))
{
mlContext.Model.Save(fitResult, stream);
}
SigParser usa gli algoritmi e le trasformazioni dei dati di ML.NET per più soluzioni di apprendimento automatico, incluso il modello di rilevamento della posta indesiderata menzionato in precedenza, che ha consentito di esportare automaticamente le informazioni di contatto corrette nei database dei clienti dalle firme di posta elettronica, ignorando la necessità di immissione manuale dei dati di contatto che richiede tempo ed è soggetta a errori.