

HMRI ha creato un framework di Machine Learning human-in-the-loop per la ricerca medica usando ML.NET

Settore
Sanità
Dimensioni dell'organizzazione
Grande (1.000-9.999 dipendenti)
Paese/area geografica
Australia
Tecnologia
Azienda
Hunter Medical Research Institute (HMRI) è un'organizzazione il cui scopo è migliorare la salute e il benessere delle loro community. Lo fa raggruppando gli ingegneri, i medici e i professionisti della salute pubblica per monitorare rapidamente la fornitura di soluzioni per la salute nuove e migliori.
Hunter Medical Research Institute (HMRI) è un'organizzazione il cui scopo è migliorare la salute e il benessere delle loro community. Lo fa raggruppando gli ingegneri, i medici e i professionisti della salute pubblica per monitorare rapidamente la fornitura di soluzioni per la salute nuove e migliori.
I dettagli della ricerca sono disponibili nel documento, "A method for rapid machine learning development for data mining with Doctor-In-The-Loop", Neva J Bull, Bridget Honan, Neil J. Spratt, James Quilty.
Problema aziendale
Gli istituti sanitari hanno grandi quantità di dati. In genere, questi dati sono nel formato di testo non strutturato. Anche se digitalizzato, è spesso difficile estrarre informazioni dettagliate significative e interattive dai dati. Le tecniche come espressioni regolari, query SQL e software di elaborazione in linguaggio naturale 'predefinito' hanno esito positivo limitato.
In questi casi, Machine Learning può aiutare ad analizzare ed estrarre informazioni preziose dai dati. Gli strumenti di Machine Learning sono stati usati in precedenza per classificare le note cliniche in categorie per diversi scopi clinici e di ricerca. Tuttavia, l'uso di questi strumenti di Machine Learning richiede spesso competenze di sviluppo software o data science, competenze che spesso non rientrano nell'ambito dei professionisti medici.
Anche negli scenari in cui viene eseguito il training di un modello, quando non sono supervisionati, i modelli ottengono risultati non ottimali se usati nel mondo reale. Con i grandi interessi coinvolti nelle decisioni mediche, è importante che i professionisti medici possano fidarsi dei propri modelli e, nei casi in cui un modello sia errato, usare le proprie competenze per fornire feedback.
Ecco perché i ricercatori di HMRI hanno usato ML.NET per sviluppare un framework di sviluppo di Machine Learning Human-In-The-Loop (HITL) per semplificare ai professionisti medici l'etichettatura dei dati, il training dei modelli e l'uso di questi modelli per l'inferenza senza che sia necessaria alcuna esperienza di programmazione o apprendimento automatico. Ancora più importante, hanno creato un meccanismo di feedback in modo che gli esperti medici possano incorporare le proprie competenze e abilità nel processo di apprendimento automatico. Di conseguenza, questo elevato livello di supervisione consente di ottenere risultati migliori in casi d'uso reali con un minor numero di punti dati.
Perché ML.NET?
HMRI ha usato Model Builder per iniziare a usare ML.NET. Model Builder ha fornito un modo per verificare rapidamente se il problema può essere risolto usando apprendimento automatico. Dopo aver convalidato l'efficacia dell'uso dell’apprendimento automatico per il problema, ha usato l'API ML.NET Automated Machine Learning (AutoML). L'API ML.NET AutoML ha automatizzato la scelta di un algoritmo ed ha effettuato l'ottimizzazione di pipeline e iperparametri all'interno del framework di sviluppo di apprendimento automatico HITL personalizzato.
Impatto di ML.NET
HMRI ha usato Model Builder per iniziare a usare ML.NET. Model Builder ha fornito un modo per verificare rapidamente se il problema può essere risolto usando l'apprendimento automatico. Dopo aver convalidato l'efficacia dell'uso dell’apprendimento automatico per la risoluzione del problema, ha usato l'API ML.NET AutoML (Automated Machine Learning). L'API ML.NET AutoML ha automatizzato la scelta di un algoritmo ed ha effettuato l'ottimizzazione di pipeline e iperparametri all'interno del framework di sviluppo di apprendimento automatico HITL personalizzato.
Usando ML.NET, HMRI ha rimosso la necessità di esternalizzare le attività di sviluppo ed è stato in grado di usare le competenze e le risorse esistenti per creare tutto internamente.
Inoltre, sfruttando ML.NET come parte della propria soluzione, sono stati in grado di fornire agli esperti medici un'interfaccia per eseguire il training e utilizzare modelli di apprendimento automatico che non richiedevano alcuna esperienza di programmazione o apprendimento automatico.
Architettura della soluzione
L'interfaccia con cui gli utenti interagiscono è un'applicazione Web che supporta diverse attività nelle fasi di training e utilizzo del modello.
Dati
Per le implementazioni iniziali, i dati usati per eseguire il training dei modelli provengono da cartelle mediche Di periodi stabiliti. Un set di dati usato è un database di 40 anni relativo alla mortalità contenente circa 30.000 record e l'altro un set di dati per il recupero aeromedico contenente circa 13.000 record.
I dati sono archiviati in un database SQL Server. Prima del training, gli esperti medici usano l'applicazione Web per etichettare un set di test in categorie predefinite per calcolare le metriche di accuratezza durante il ciclo di training. Quindi, per il primo ciclo di training viene usato un piccolo set di dati scelti in modo casuale.
Flusso di lavoro di training, valutazione e consumo

Il training del modello viene attivato dagli esperti medici dell'applicazione Web. Il codice ML.NET lato server gestisce il training e il training del modello. Il modello stima quindi tutti i dati rimanenti. Le stime e i punteggi di attendibilità vengono archiviati nel database SQL Server. Le procedure SQL Server stored procedure vengono usate per calcolare e archiviare le metriche di accuratezza rispetto al set di test. Queste metriche vengono quindi visualizzate nuovamente agli esperti medici tramite l'applicazione Web. L'intero processo viene completato in pochi secondi.
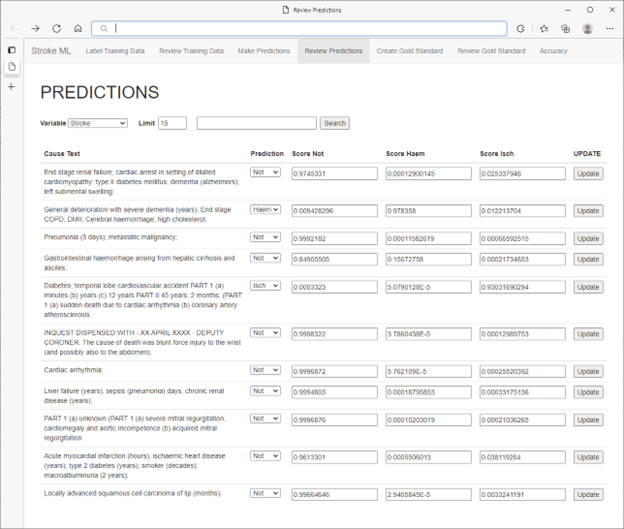
* Dati non effettivi dei pazienti
Gli esperti medici hanno scoperto di essere in grado di usare in modo intuitivo le metriche di richiamo e di specificità per guidare la selezione di casi aggiuntivi da etichettare, con conseguente miglioramento rapido e massimo delle prestazioni del modello. Ulteriori miglioramenti delle prestazioni sono stati realizzati puntando in modo selettivo all'etichettatura in base all'ordinamento in base ai punteggi di attendibilità. In questo modo, gli esperti medici si sono impegnati nell'apprendimento attivo non solo confermando le stime con punteggi bassi, ma correggendo anche stime errate con punteggi elevati.
A questo punto, gli esperti medici possono avviare un processo per ripetere il training del modello usando le etichette dati corrette. Questo ciclo con etichetta, training, e valutazione continua fino a quando gli esperti medici non saranno soddisfatti delle prestazioni del modello. I timestamp degli eventi di training, le metriche di valutazione e altre informazioni vengono registrati nel database SQL Server per un'ispezione e un controllo successivi.
Al termine del training del ciclo di valutazione dell'etichetta, viene selezionato un set di convalida di stime dal database di SQL Server usando il generatore di numeri casuali predefinito di SQL Server. Questi punti dati sono stati etichettati da un gruppo di esperti medici legati alle previsioni del modello.
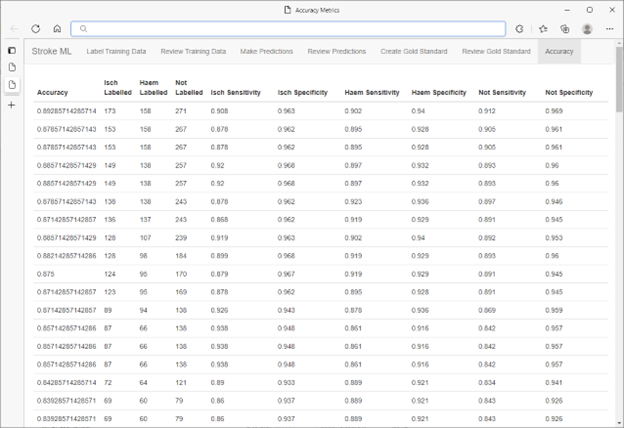
L'accuratezza risultante del modello era tra il 95 e il 99%. Questo risultato ha concesso ai medici la fiducia nell'uso delle categorizzazioni prodotti dal modello nella ricerca medica in corso. La velocità di ML.NET combinata con il flusso di lavoro HITL ha fatto sì che fosse ripetuta per diverse attività di categorizzazione e/o set di dati diversi in modo estremamente efficiente e conveniente senza compromettere l'accuratezza.
Piani futuri
Il flusso di lavoro Doctor-In-The-Loop sviluppato dai medici HMRI si dimostrerà importante per ricerche future che dipendono dalla categorizzazione rapida e accurata del testo libero medico.