

endjin rivoluziona le attività semplici con ML.NET

Settore
Informatica e servizi
Dimensioni dell'organizzazione
Piccole dimensioni (1-100 dipendenti)
Paese/area geografica
Regno Unito
Tecnologia
Azienda
Endjin è un'azienda, una società di consulenza tecnologica e Microsoft Gold Partner per piattaforma cloud, piattaforma dati, analisi dei dati e DevOps con sede nel Regno Unito. Endjin ha un enorme entusiasmo per la potenza rivoluzionaria della tecnologia e per sfruttare tale potenza per aiutare i clienti a risolvere problemi complessi. Di recente l’azienda si è concentrata sull'uso di Machine Learning per risolvere problemi aziendali complessi, ma di alto valore. Questo ha dimostrato che, anche se l'apprendimento automatico è ideale per la risoluzione di casi d'uso nuovi, la possibilità di rivoluzionare attività semplici e quotidiane è spesso ignorata.
Siamo rimasti sorpresi dalla facilità con cui AutoML e ML.NET possono essere usati per ridurre il tempo dedicato ad attività lunghe e monotone. La libertà acquisita tramite l'uso di queste tecnologie accessibili e potenti consente di concentrare il nostro tempo su analisi creativi e di ottenere informazioni preziose dai dati che producono."
Problema aziendale
Nel 2014 endjin ha creato Azure Weekly, una newsletter gratuita che riepiloga le principali novità della settimana nell'ecosistema di Azure. Per i primi 25 numeri, il team di endjin ha curato manualmente la newsletter, ma con l'aumento del volume dei contenuti è diventato evidente che questa prassi non era sostenibile. Applicando il mantra aziendale "lavora in modo più intelligente", endjin ha automatizzato il processo end-to-end creando un classificatore di testo C# personalizzato per classificare gli articoli di oltre 300 blog in 19 categorie, tra cui IA e Machine Learning, analisi, DevOps, Internet delle cose, reti e Web. La soluzione funzionava relativamente bene, ma richiedeva di gestire un elenco attivo di parole chiave in base a cui classificare e ogni settimana erano necessarie correzioni manuali. Tutto questo causava notevoli oneri in termini di manutenzione.
Dopo oltre 200 problemi e molte migliaia di abbonati, endjin ha deciso di iniziare a cercare una soluzione di apprendimento automatico. Sapeva che alla base della piattaforma di contenuti aveva due problemi fondamentali da risolvere: un problema di classificazione binaria ("questo è un articolo su Azure?") e un problema di classificazione multiclasse ("quale area di Azure copre questo articolo?"). Endjin ha quindi deciso di usare ML.NET per risolvere questi problemi, migliorare la piattaforma e rimuovere il sovraccarico di manutenzione manuale.
Quando si esaminano le attività o i processi eseguiti dalla maggior parte delle organizzazioni, è possibile suddividerli in una serie di passaggi decisionali di 1 secondo. Se si applicano l'apprendimento automatico, flussi di lavoro reattivi e l'economia basata su API allo spazio del problema, si iniziano a scoprire i vantaggi essenziali che la quarta rivoluzione industriale potrebbe offrire"
Perché ML.NET?
Sebbene il linguaggio di programmazione preferito è C#, la mancanza precedente di un framework di Machine Learning di prima classe per .NET ha fatto sì che endjin abbia usato R e Python negli esperimenti giornalieri di Machine Learning e data science rivolti ai clienti. Tuttavia, la produzione di modelli di Machine Learning scritti in R e Python era problematica a causa di opzioni di hosting limitate. Il resto della piattaforma di contenuti di endjin è stato creato usando componenti PaaS e Serverless, quindi la combinazione di ML.NET e Funzioni di Azure era incredibilmente interessante per l'azienda. Non appena ML.NET è stato annunciato a //build 2018, hanno iniziato a usare il framework di Machine Learning per la propria app.
Impatto di ML.NET e AutoML
Endjin ha tratto grande beneficio dalle prestazioni elevate di ML.NET, non solo in termini di miglioramento della velocità durante la classificazione degli articoli, ma anche in termini di accuratezza. Dal momento dell'adozione di ML.NET, gli articoli classificati in modo errato sono molto meno numerosi, il che si traduce in meno interventi manuali e nella produzione più rapida di contenuti.
L'uso dell'interfaccia della riga di comando (CLI) di ML.NET con AutoML ha anche reso l'intero processo di training, valutazione e generazione del codice da usare ML.NET infallibile. L'uso di AutoML per scegliere il modello con le prestazioni migliori e generare automaticamente il training del modello e il codice di consumo per la classificazione (rispetto alla scelta manuale delle trasformazioni dei dati, degli algoritmi e delle opzioni degli algoritmi per creare un modello e un codice di ML.NET) ha migliorato l'accuratezza del modello dal 68% al 78%, e l'esecuzione di questo modello sui dati storici non solo ha evidenziato molti articoli che sono stati erroneamente classificati, ma ha anche identificato molti articoli validi che erano stati esclusi dal modello di classificazione originale.
Architettura della soluzione
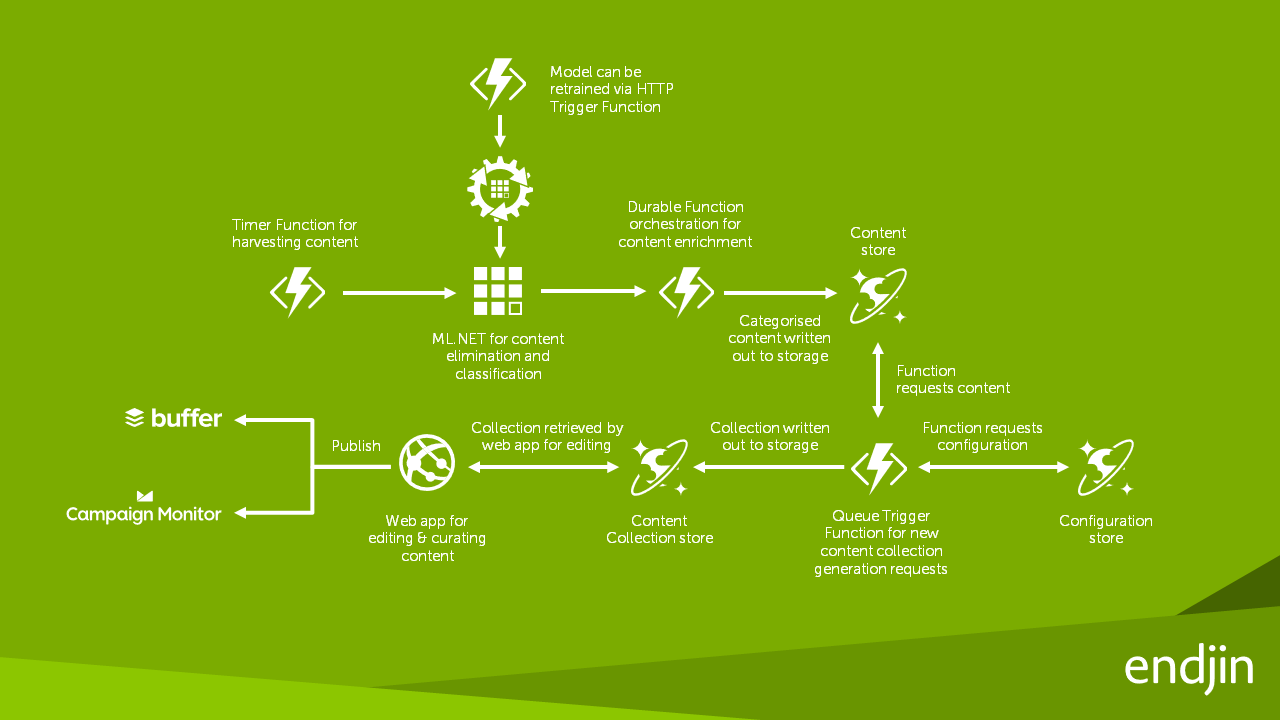
Creazione di un'applicazione con ML.NET
Quando endjin ha iniziato a usare ML.NET, ha creato uno strumento per convertire i dati cronologici della piattaforma di contenuti in un set di dati CSV per eseguire manualmente il training di un modello ML.NET e ha creato un altro strumento per selezionare in modo casuale il 20% del set di dati di training come set di dati di convalida. Ha creato quindi manualmente un modello ML.NET per prevedere la categoria di appartenenza di un articolo.
Quando è stata resa disponibile per l'uso l'interfaccia della riga di comando di ML.NET con AutoML, è stato possibile semplificare il processo e produrre risultati significativamente migliori. In primo luogo, AutoML ha generato automaticamente un set di dati di convalida dal set di dati di training, rendendo quindi superfluo il secondo strumento personalizzato di endjin. In secondo luogo, la configurazione di una durata di esplorazione massima pari a un'ora ha consentito ad AutoML di eseguire il training, ottimizzare e valutare più modelli di classificazione e visualizzare i 5 modelli con le prestazioni migliori.
Dopo che endjin ha creato i modelli con training di ML.NET generati da AutoML, i modelli sono stati integrati nella piattaforma di contenuto esistente, semplicemente scambiando gli algoritmi di classificazione personalizzati esistenti. I modelli ML.NET sono stati ospitati all'interno di una funzione di Azure per abilitare la scalabilità elastica della valutazione del modello. È stata usata una nuova funzione durevole per consentire il nuovo training dei modelli su richiesta.
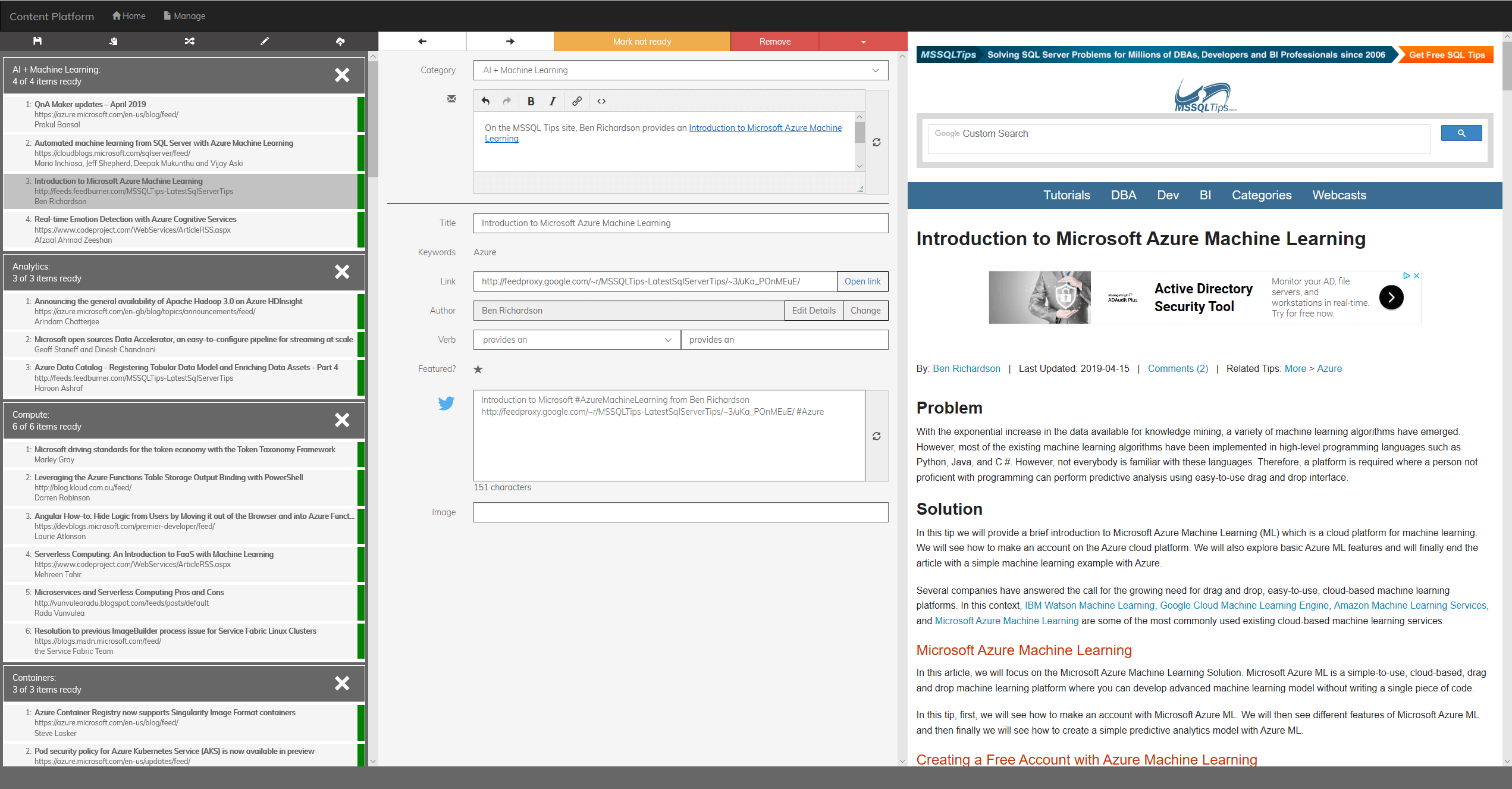
Elaborazione dati
Fortunatamente, quando ha creato la versione originale della piattaforma di contenuto, il team di endjin sapeva che un giorno avrebbe voluto migliorarla usando il Machine Learning, quindi ha conservato tutti i dati usati per generare le newsletter sia in formato non elaborato che in formato elaborato (oltre 4.000 file JSON con dimensioni totali di circa 3 GB). I dati sono stati trasformati in due set di dati di training: un file CSV da 28 MB per la classificazione binaria e un file CVS da 9 MB per la classificazione multiclasse.
Trasformazioni dei dati e algoritmi di Machine Learning
Poiché il titolo e il contenuto dei post di blog da classificare sono in testo libero, vanno entrambi convertiti usando la trasformazione dati Featurize Text. Il titolo e il contenuto sono stati poi uniti in un unico campo usando la trasformazione dati Concatenate.
Il modello originale creato manualmente da endjin ha usato l'algoritmo di classificazione multiclasse SdcaMaximumEntropy. Tuttavia, quando endjin ha usato ML.NET CLI con AutoML, sono stati trovati modelli con prestazioni ancora più elevate per i rispettivi scenari.
Per il primo scenario ("si tratta di un articolo su Azure?") AutoML ha selezionato AveragedPerceptronBinary come algoritmo con le prestazioni migliori. Per il secondo scenario ("di quale area di Azure tratta questo articolo?") AutoML ha selezionato LightGbmMulti come algoritmo con le prestazioni più elevate e ha generato il codice seguente per eseguire il training del classificatore multiclasse:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin ha usato ML.NET per migliorare il processo di selezione e categorizzazione degli articoli per la newsletter di Azure. L'utilizzo di ML.NET e AutoML per la generazione di modelli di Machine Learning ha consentito all'azienda di concentrarsi meno sui parametri dei modelli di ottimizzazione e di fornire il proprio valore aziendale.