

SigParser usa ML.NET para detectar correos electrónicos "no humanos"

Sector
Software o telecomunicaciones
Tamaño de la organización
Pequeño (1-49 empleados)
País o región
Estados Unidos
Tecnología
Empresa
SigParser es una API y un servicio que automatiza el tedioso (y a menudo costoso) proceso de agregar y mantener sistemas de administración de relaciones con clientes (CRM). SigParser extrae información de contacto, como nombres, direcciones de correo electrónico y números de teléfono, de las firmas de correo electrónico y alimenta toda esa información como contactos en sistemas o bases de datos CRM.
Problema empresarial
Cuando SigParser procesa los correos electrónicos de una empresa, muchos de los correos electrónicos no son humanos (por ejemplo, boletines, notificaciones de pago, restablecimiento de contraseñas, etc.). La información del remitente de estos tipos de correos electrónicos no debe aparecer en las listas de contactos ni insertarse en un sistema CRM. Por lo tanto, SigParser decidió usar el aprendizaje automático para predecir si los mensajes de correo electrónico son "spammy looking."
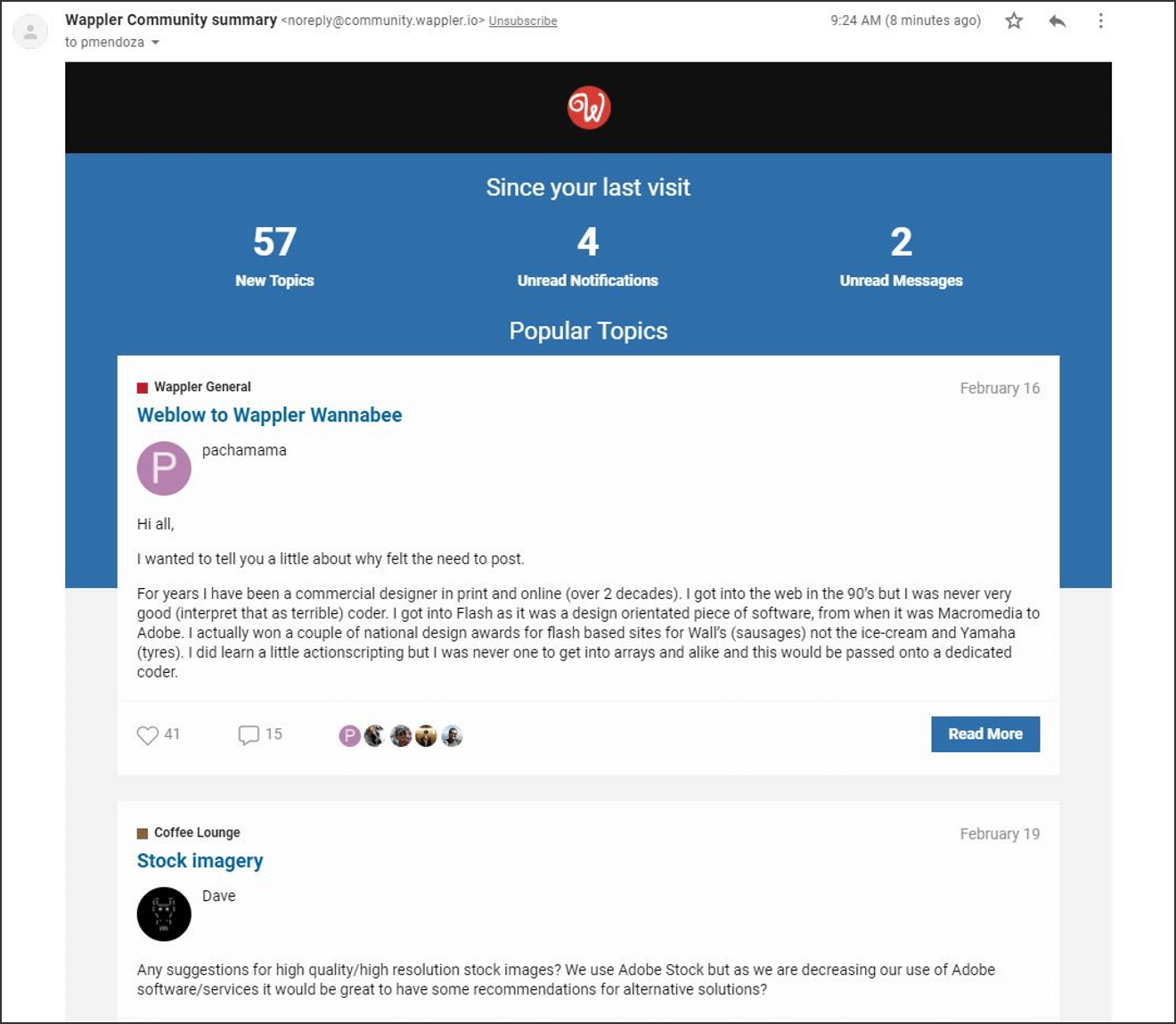
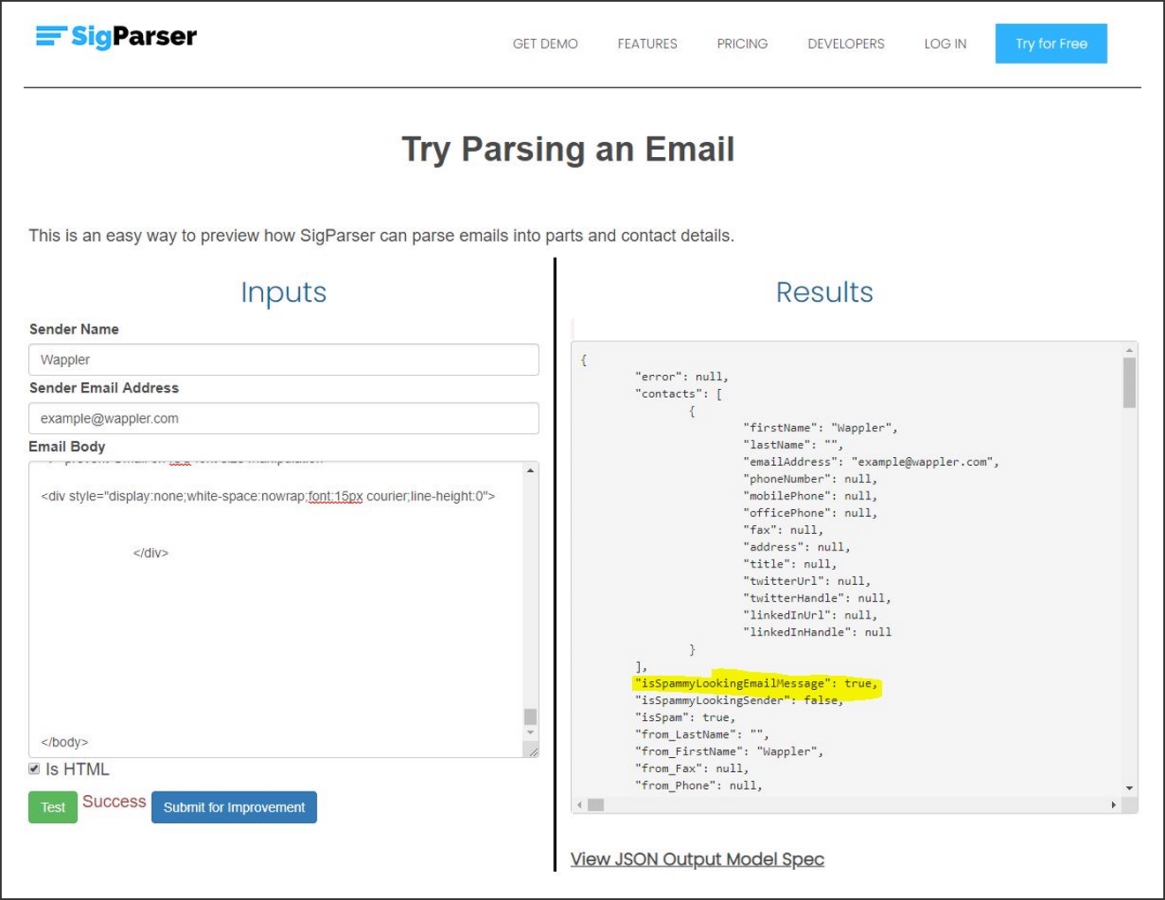
Tome como ejemplo el siguiente correo electrónico de notificación de un foro. El remitente de este correo electrónico no es un contacto que debería aparecer en un CRM, por lo que un modelo de aprendizaje automático predice que "isSpammyLookingEmailMessage" es true:
¿Por qué ML.NET?
Cuando el equipo de SigParser decidió usar el aprendizaje automático, intentó originalmente usar R; sin embargo, encontraron que era muy difícil de mantener e integrar con su API, que se compila con .NET Core.
Paul Mendoza, CEO y fundador de SigParser, dijo que R "estaba demasiado desconectado del proceso de desarrollo. Con R generamos todas las constantes y luego las copiamos y pegamos en .NET y luego probamos el modelo de verdad y descubrí que no funcionó del todo y tuve que repetirlo. Esto fue demasiado lento"\.
Por tanto, han recurrido a ML.NET para incluir todo en una aplicación.
"Con ML.NET, podemos entrenar el modelo y, a continuación, probarlo inmediatamente dentro de nuestro código. Esto hace que el envío de nuevos cambios sea más rápido porque todas las herramientas están juntas en un solo lugar."
Impacto de ML.NET
El impacto de pasar a ML.NET desde R ha resultado en una mejora de la productividad multiplicada por 10. Además, hasta que SigParser se trasladó a R, solo utilizaban un modelo de aprendizaje automático. Desde la conversión a ML.NET, ahora tienen 6 modelos de aprendizaje automático para diversos aspectos del análisis sintáctico del correo electrónico. Este aumento se ha producido porque ahora es posible con ML.NET experimentar rápidamente con nuevas ideas de aprendizaje automático y mostrar rápidamente los resultados en la aplicación.
Arquitectura de la solución
Procesamiento de datos
SigParser usó por primera vez el conocido conjunto de datos Enron para entrenar su modelo, pero cuando se dieron cuenta de que estaba bastante obsoleto, terminaron etiquetando un par de miles de correos electrónicos en sus propias cuentas de correo electrónico (de acuerdo con el cumplimiento del RGPD) como humanos o no humanos, y lo usaron como un conjunto de datos de entrenamiento.
Características de aprendizaje automático
El modelo de ML.NET de SigParser tiene dos características (que se usan para realizar la predicción "Is EmailsE-mail"):
HasUnsubscribes—Verdadero si un correo electrónico tiene un "anular suscripción" o "no participar" en el cuerpo del correo electrónicoEmailBodyCleaned—Normaliza el cuerpo del correo electrónico en formato HTML para hacer que el idioma del correo electrónico sea agnóstico y para eliminar cualquier información personal identificable
Algoritmo de machine learning
Estas dos características se introducen en un algoritmo FastTree binario, que es un algoritmo para escenarios de clasificación, y la salida es la predicción de si el correo electrónico se envió desde un "humano real" o desde un origen automatizado. Actualmente, SigParser procesa millones de correos electrónicos al mes con este modelo de ML.NET.
var mlContext = new MLContext();
var(trainData, testData) = mlContext.BinaryClassification.TrainTestSplit(mlContext.CreateStreamingDataView(totalSampleSet), testFraction:0.2);
var pipeline = mlContext.Transforms.Text.FeaturizeText("EmailBodyCleaned", "EmailHTMLFeaturized")
.Append(mlContext.Transforms.Concatenate("Features", "HasUnsubscribes", "EmailHTMLFeaturized"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumn: "IsHumanEmail", featureColumn: "Features"));
Console.WriteLine("Fitting data");
var fitResult = pipeline.Fit(trainData);
Console.WriteLine("Evaluating metrics");
var metrics = mlContext.BinaryClassification.Evaluate(fitResult.Transform(testData), label: "IsHumanEmail");
Console.WriteLine("Accuracy: " + metrics.Accuracy);
using (var stream = File.Create(emailParsingPath + "EmailHTMLTypeClassifier.zip"))
{
mlContext.Model.Save(fitResult, stream);
}
SigParser usa transformaciones de datos y algoritmos de ML.NET para varias soluciones de aprendizaje automático, incluido el modelo de detección de correo no deseado mencionado anteriormente, que les ha permitido exportar automáticamente la información de contacto correcta a las bases de datos de clientes desde firmas de correo electrónico, evitando la necesidad de una entrada de datos de contacto manual lenta y propensa a errores.