

HMRI ha creado un marco de aprendizaje automático humano en bucle para la investigación médica mediante ML.NET

Sector
Estado
Tamaño de la organización
Grande (1 000-9 999 empleados)
País o región
Australia
Tecnología
Empresa
El Instituto de Investigación Médica Der (HMRI) es una organización cuyo propósito es mejorar la salud y el bienestar de sus comunidades. Para ello, reúne a científicos, médicos y profesionales de la salud pública para realizar un seguimiento rápido del aprovisionamiento de soluciones sanitarias nuevas y mejores.
El Instituto de Investigación Médica Der (HMRI) es una organización cuyo propósito es mejorar la salud y el bienestar de sus comunidades. Para ello, reúne a científicos, médicos y profesionales de la salud pública para realizar un seguimiento rápido del aprovisionamiento de soluciones sanitarias nuevas y mejores.
Los detalles de la investigación se pueden encontrar en el documento " Un método para el desarrollo rápido del aprendizaje automático para la minería de datos con Doctor-In-The-Loop", Factora J Bull, Bridget Honan, Andrew J. Spratt y Simon.
Problema empresarial
Las instituciones sanitarias tienen grandes cantidades de datos. Normalmente, estos datos tienen el formato de texto no estructurado. Incluso cuando se digitalizan, a menudo es difícil extraer información significativa y procesable de los datos. Las técnicas como las expresiones regulares, las consultas SQL y el software de procesamiento de lenguaje natural "listo para usar" tienen un éxito limitado.
En tales casos, el aprendizaje automático puede ayudar a analizar y extraer información valiosa de los datos. Las herramientas de aprendizaje automático se han usado anteriormente para clasificar las notas clínicas en categorías con diversos fines clínicos y de investigación. Sin embargo, el uso de estas herramientas de aprendizaje automático a menudo requiere conocimientos de desarrollo de software o ciencia de datos. Aptitudes que a menudo están fuera del ámbito de los profesionales sanitarios.
Incluso en escenarios en los que se entrena un modelo, cuando se deja sin supervisión, los modelos obtienen resultados poco óptimos cuando se usan en el mundo real. Con los altos riesgos que conllevan las decisiones médicas, es importante que los profesionales médicos puedan confiar en sus modelos y, en los casos en los que un modelo es incorrecto, usen su experiencia para proporcionar comentarios.
Por eso, los investigadores de HMRI usaron ML.NET para desarrollar un marco de desarrollo de aprendizaje automático con intervención humana (HITL) para facilitar a los profesionales médicos el etiquetado de datos, el entrenamiento de modelos y el uso de estos modelos para la inferencia, sin necesitar programación o aprendizaje automático. Y lo que es más importante, se creó un mecanismo de comentarios para que los expertos médicos puedan incorporar sus aptitudes y experiencia al proceso de aprendizaje automático. Como resultado, con este alto nivel de supervisión se logran mejores resultados en casos de uso reales con menos puntos de datos.
¿Por qué ML.NET?
HMRI usó Model Builder para comenzar con ML.NET. Model Builder proporciona una manera de validar rápidamente si los problemas se pueden resolver con el aprendizaje automático. Una vez que se haya validado la eficacia del uso del aprendizaje automático para el problema, se habrá sacado provecho de la API de ML.NET Automated Machine Learning (AutoML). La API de AutoML de ML.NET automatiza la elección de un algoritmo, así como la optimización de la canalización e hiperparámetros dentro del marco de desarrollo de aprendizaje automático de HITL personalizado.
Impacto de ML.NET
HMRI usó Model Builder para comenzar con ML.NET. Model Builder proporciona una manera de validar rápidamente si los problemas se pueden resolver con el aprendizaje automático. Una vez que se haya validado la eficacia del uso del aprendizaje automático para el problema, se habrá sacado provecho de la API de ML.NET Automated Machine Learning (AutoML). La API de AutoML de ML.NET automatiza la elección de un algoritmo, así como la optimización de la canalización e hiperparámetros dentro del marco de desarrollo de aprendizaje automático de HITL personalizado.
Mediante el uso de ML.NET, HMRI eliminó la necesidad de externalizar los esfuerzos de desarrollo y ha podido usar las aptitudes y los recursos existentes para crear todo internamente.
Además, al aprovechar ML.NET como parte de su solución, pudieron proporcionar una interfaz para que los expertos médicos entrenaran y consuman modelos de aprendizaje automático que no requerían ninguna experiencia de programación o aprendizaje automático.
Arquitectura de la solución
La interfaz con la que interactúan los usuarios es una aplicación web que admite varias tareas en las fases de entrenamiento y consumo del modelo.
Datos
Para las implementaciones iniciales, los datos usados para entrenar los modelos proceden de registros médicos históricos. Un conjunto de datos usado era una base de datos de 40 años de duración que contiene unos 30 000 registros y el otro un conjunto de datos de recuperación aeromédica que contiene unos 13 000 registros.
Los datos se almacenan en una base de datos SQL Server. Antes del entrenamiento, los expertos médicos usan la aplicación web para etiquetar un conjunto de pruebas en categorías predefinidas para calcular las métricas de precisión durante el bucle de entrenamiento. A continuación, se usa un pequeño conjunto de datos elegidos aleatoriamente para la primera ronda de entrenamiento.
Flujo de trabajo de entrenamiento, evaluación y consumo

El entrenamiento del modelo es activado por los expertos sanitarios desde la aplicación web. El código ML.NET del lado del servidor se encarga del entrenamiento y reentrenamiento del modelo. Posteriormente, el modelo predice todos los datos restantes. Las predicciones y las puntuaciones de confianza se almacenan en la base de datos de SQL Server. Los procedimientos almacenados de SQL Server se utilizan para calcular y almacenar las métricas de precisión con respecto al conjunto de pruebas. Estas métricas se muestran a los expertos sanitarios a través de la aplicación web. Todo este proceso se completa en segundos.
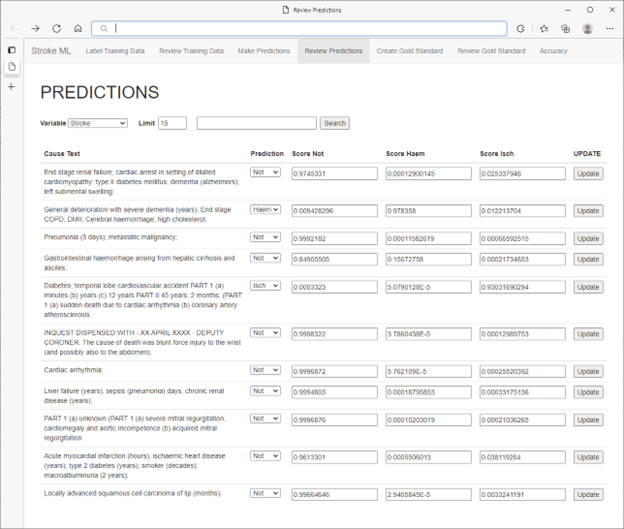
* Datos de pacientes no reales
Los expertos sanitarios han descubierto que han podido usar de forma intuitiva métricas de recuperación y especificidad para guiar la selección de casos adicionales para etiquetar, lo que da lugar a una mejora máxima y rápida en el rendimiento del modelo. Se lograron más mejoras de rendimiento al dirigirse de forma selectiva al etiquetado en función de la ordenación por puntuaciones de confianza. Al hacerlo, los expertos médicos se dedican al aprendizaje activo no solo confirmando predicciones con puntuaciones bajas, sino también corrigiendo predicciones incorrectas con puntuaciones altas.
En este punto, los expertos médicos pueden iniciar un trabajo en el que vuelvan a entrenar el modelo utilizando las etiquetas de datos corregidas. Este bucle de etiquetado, entrenamiento y evaluación continúa al menos hasta que los expertos médicos estén satisfechos con el rendimiento de su modelo. Las marcas de tiempo de los eventos de entrenamiento, las métricas de evaluación y otra información se registran en la base de datos de SQL Server para su posterior inspección y auditoría.
Una vez completada la etiqueta, el bucle de entrenamiento y evaluación, se selecciona un conjunto de predicciones de validación de la base de datos de SQL Server mediante el generador de números aleatorios integrado de SQL Server. Estos puntos de datos fueron etiquetados por un panel de expertos médicos cegados a las predicciones del modelo.
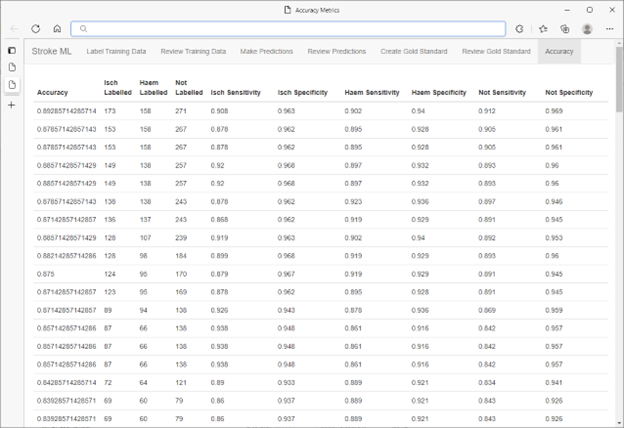
La precisión resultante del modelo osciló entre los 90 grados. Este resultado ha dado a los investigadores confianza para utilizar las categorizaciones producidas por el modelo en su investigación médica en curso. La velocidad de ML.NET, combinada con el flujo de trabajo HITL, permitió repetirlo para diferentes tareas de categorización y/o diferentes conjuntos de datos de una manera altamente eficiente y rentable sin comprometer la precisión.
Planes futuros
El flujo de trabajo Doctor-In-The-Loop desarrollado por los investigadores del HMRI resultará muy valioso para futuras investigaciones que dependan de una categorización rápida y precisa del texto médico libre.