

endjin revoluciona las tareas simples con ML.NET

Sector
Tecnología y servicios de la información
Tamaño de la organización
Pequeño (1-100 empleados)
País o región
Reino Unido
Tecnología
Empresa
Endjin es una empresa pequeña de consultoría tecnológica y Partner Gold de Microsoft para plataformas en la nube, plataformas de datos, análisis de datos y DevOps con sede en el Reino Unido. Endjin posee un entusiasmo contagioso por el poder revolucionario de la tecnología y por aprovechar ese poder para ayudar a los clientes a resolver problemas difíciles. Recientemente, se han centrado en usar el aprendizaje automático para resolver problemas empresariales cotidianos, pero de gran valor. Esto ha demostrado que, aunque el aprendizaje automático es excelente para resolver casos de uso novedosos, a menudo se pasa por alto su capacidad para revolucionar tareas sencillas y cotidianas.
"Nos ha sorprendido la facilidad con la que se pueden utilizar AutoML y ML.NET para reducir el tiempo dedicado a tareas monótonas y que consumen mucho tiempo. La libertad que se obtiene mediante el uso de estas tecnologías accesibles y potentes nos permite centrar nuestro tiempo en análisis guiados por el pensamiento creativo y la obtención de información valiosa a partir de los datos que producen."
Problema empresarial
En 2014, endjin creó Azure Weekly, un boletín gratuito que resume las principales noticias de la semana en el ecosistema de Azure. En los primeros 25 problemas, el equipo al final ha mantenido manualmente el boletín, pero a medida que el volumen de contenido ha crecido, se han dado cuenta de que esto era insostenible. Aplicaron su mantra de empresa de "trabajo más inteligente" y automatizaron el proceso de un extremo a otro mediante la creación de su propio clasificador de texto personalizado de C# para clasificar artículos de más de 300 blogs en 19 categorías, incluida Inteligencia artificial + Machine Learning, Analytics, DevOps, Internet de las cosas, Redes y Web. Esto funcionó relativamente bien, pero además del requisito de mantener una lista activa de palabras clave para clasificar, se necesitaban correcciones manuales cada semana, lo que provocaba una sobrecarga de mantenimiento importante.
Tras más de 200 números y muchos miles de suscriptores, Endjin decidió empezar a buscar una solución de aprendizaje automático. Sabían que en el corazón de la plataforma de contenidos tenían dos problemas centrales que resolver: un problema de clasificación binaria ("¿es éste un artículo sobre Azure?") y un problema de clasificación multiclase ("¿qué área de Azure cubre este artículo?"). Así pues, Endjin decidió usar ML.NET para resolver estos problemas, mejorar su plataforma y eliminar la sobrecarga de mantenimiento manual.
" Al examinar el trabajo o los procesos realizados por la mayoría de las organizaciones, puede dividirlos en una serie de pasos de toma de decisiones de 1 segundo. Si aplica aprendizaje automático, los flujos de trabajo reactivos y la economía de API al espacio problemático, empezamos a llegar al corazón de lo que 4th Industrial Revolution podría entregar"
¿Por qué ML.NET?
Aunque su lenguaje de programación elegido es C#, la falta anterior de un marco de aprendizaje automático de primera clase para .NET significaba que endjin había estado usando R y Python en sus experimentos diarios de aprendizaje automático y ciencia de datos orientados a los clientes. Sin embargo, la producción de modelos de aprendizaje automático escritos en R y Python era problemática debido a las opciones de hospedaje limitadas. El resto de la plataforma de contenido de endjin se ha creado con Paas y componentes sin servidor, por lo que la combinación de ML.NET y Azure Functions era increíblemente atractiva para la empresa; tan pronto como se anunció ML.NET en //build 2018, empezaron a usar el marco de aprendizaje automático en su aplicación.
Impacto de ML.NET y AutoML
Edjin se ha beneficiado en gran medida del alto rendimiento de ML.NET, no solo en términos de mejoras de velocidad al clasificar artículos, sino también en términos de precisión. Desde la adopción de ML.NET, han visto muchos menos artículos mal categorizados, lo que se traduce en menos intervenciones manuales y una producción de contenido más rápida.
El uso de la CLI de ML.NET con AutoML también ha hecho que todo el proceso de entrenamiento, evaluación y generación del código para usar ML.NET sea infalible. El uso de AutoML para elegir el modelo de mejor rendimiento y generar, de forma automática, el entrenamiento del modelo y el código de consumo para la clasificación (en comparación con la elección manual de las transformaciones de datos, algoritmos y opciones de algoritmo para crear un modelo y código ML.NET) ha mejorado la precisión del modelo del 68 % al 78 %, y la ejecución de este modelo con datos históricos no solo resaltaba muchos artículos que se habían clasificado de forma incorrecta, sino que también ha identificado muchos artículos válidos que habían sido excluidos por el modelo de clasificación original.
Arquitectura de la solución
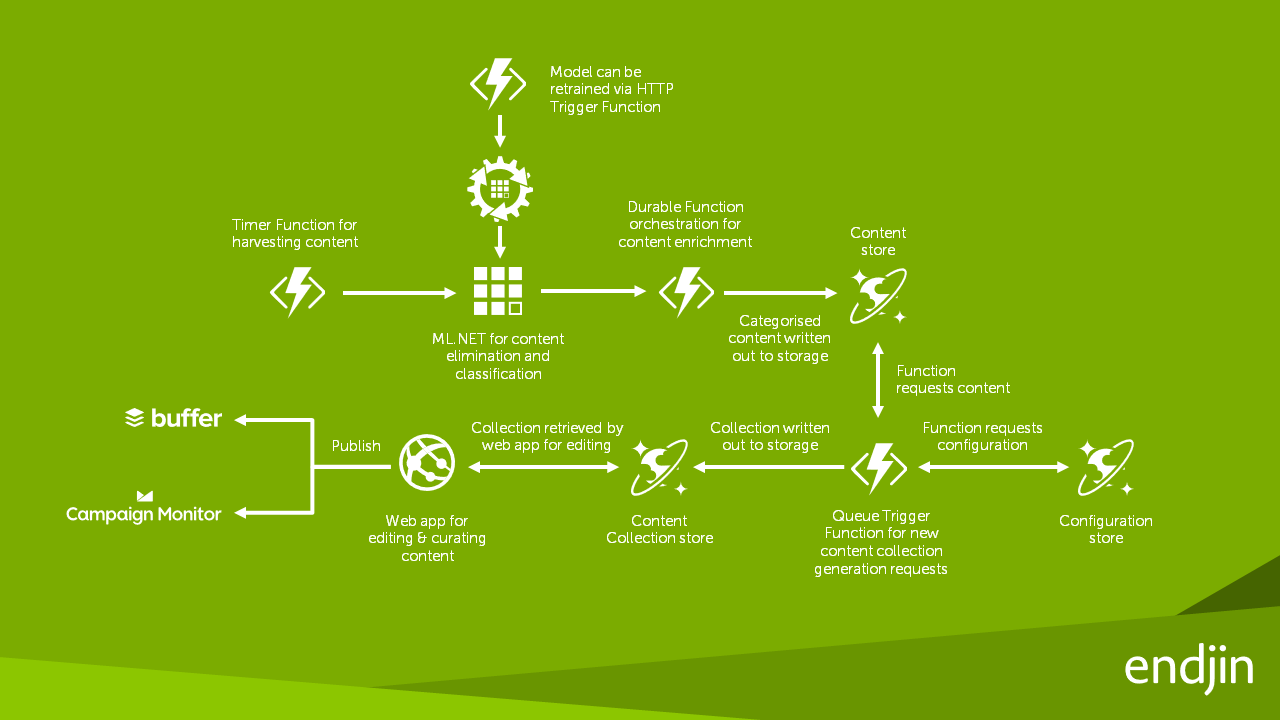
Creación de una aplicación con ML.NET
Cuando endjin comenzó a usar ML.NET por primera vez, crearon una herramienta para convertir los datos históricos de la plataforma de contenido en un conjunto de datos CSV para entrenar manualmente un modelo ML.NET, y crearon otra herramienta para seleccionar aleatoriamente el 20 % del conjunto de datos de entrenamiento como validación. conjunto de datos Luego crearon manualmente un modelo ML.NET para predecir a qué categoría pertenece un artículo.
Una vez que la CLI de ML.NET con AutoML estaba disponible para su uso, simplificó el proceso y generó resultados significativamente mejores. En primer lugar, AutoML generó automáticamente un conjunto de datos de validación a partir del conjunto de datos de entrenamiento, por lo que ya no se necesitaba la segunda herramienta personalizada de Endjin. En segundo lugar, al establecer un tiempo máximo de exploración durante una hora, AutoML pudo entrenar, ajustar y evaluar varios modelos de clasificación y mostrar los 5 modelos con mayor rendimiento.
Una vez que endjin tenía los modelos de ML.NET entrenados generados por AutoML, integraba los modelos en la plataforma de contenido existente,y simplemente intercambiaba los algoritmos de clasificación personalizados existentes. Los modelos de ML.NET se hospedaban dentro de una función de Azure para habilitar la escala elástica de la evaluación de modelos. Se usó una nueva función durable para permitir que los modelos se vuelvan a entrenar a petición.
Procesamiento de datos
Afortunadamente, el equipo de al final sabía cuando creó la versión original de la plataforma de contenido que un día quisiera mejorarla mediante el aprendizaje automático, por lo que conservaba todos los datos usados para generar los boletines en formatos sin procesar y procesados (más de 4000 archivos JSON con un tamaño total de aproximadamente 3 GB). Estos se transformaron en dos conjuntos de datos de entrenamiento: un valor de 28 MB. Archivo CSV para clasificación binaria y 9 MB. archivo .CSV para la clasificación multiclase.
Transformaciones de datos y algoritmos de aprendizaje automático
Dado que el título y el contenido de las entradas de blog que se clasifican son texto libre, ambos deben convertirse mediante la transformación de datos Featurize Text. Después, el título y el contenido se unieron en un solo campo mediante la transformación de datos Concatenate.
El modelo original creado manualmente usaba el algoritmo de clasificación multiclase SdcaMaximumEntropy. Sin embargo, cuando Endjin usó la CLI de ML.NET con AutoML, encontró modelos de mayor rendimiento para sus escenarios.
Para el primer escenario ("¿es este un artículo sobre Azure?") AutoML seleccionó AveragedPerceptronBinary como el algoritmo con mejor rendimiento. Para el segundo escenario ("¿qué área de Azure incluye este artículo?") AutoML seleccionó LightGbmMulti como el algoritmo con mejor rendimiento y generó el siguiente código para entrenar el clasificador multiclase:
public static IEstimator
BuildTrainingPipeline(MLContext mlContext){
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("CategoryId", "CategoryId")
.Append(mlContext.Transforms.Text.FeaturizeText("Title_tf", "Title"))
.Append(mlContext.Transforms.Text.FeaturizeText("Content_tf", "Content"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Title_tf", "Content_tf", "Issue" }));
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.LightGbm(labelColumnName: "CategoryId", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
} Endjin ha usado ML.NET para mejorar su proceso de selección y categorización de artículos para su boletín de Azure. El uso de ML.NET y AutoML para generar modelos de aprendizaje automático también ha permitido a la empresa centrarse menos en ajustar los parámetros del modelo y más en ofrecer su valor empresarial.